
The AI Engineer's Guide to Inference Engines and Frameworks
What solutions are out there? Which one to select based on your use case and AI workload.

Hey, welcome!
Each week, I share insights on advanced, production-ready AI/ML development, the kind of practical knowledge that rarely gets covered elsewhere.
Join 5,400+ AI/ML engineers who subscribe to level up their skills with hands-on advice, insights, and lessons I’ve learned from nearly a decade working in the AI industry.
Introduction
When deploying machine learning models into production, inference speed becomes just as important as accuracy.
To promote an AI model (LLMs included) from research into production, the deployment lifecycle can be viewed in two distinct stages.
The research and development stage focuses on model quality, involving pre-training and post-training phases. The deployment and monitoring stage focuses on the model’s performance as part of a larger AI System.
This article covers everything AI Engineers need to know about Inference Engines and Serving Frameworks, going through every available open-source solution for optimizing, compiling, and serving AI Models.
Table of Contents
The Phases of Model Development
Inference Engines and Inference Frameworks
ONNX and ONNX Runtime
TensorRT, TensorRT-LLM
vLLM, vLLM + LMCache
vLLM + Ray
llama.cpp
Ollama
NVIDIA Triton Inference Server
HuggingFace TGI (Text-Generation Inference)
CoreML
OpenVINO, OpenVINO GenAI for Intel Hardware
Distributed GenAI Inference Frameworks
NVIDIA Dynamo
vLLM + llm-D (Kubernetes)
AirBrix
Mojo and Mojo MAX Engine
Conclusion
Model Development (Pre/Post-Training)
During the first stage, most AI researchers and ML Engineers could train a smaller model from scratch, something which rarely happens, and more often we use a pre-trained model, then further adapt it to downstream tasks. This bit of adapting a model to a new task is a form of Transfer Learning, an older term, given the rate at which the AI field progresses. (i.e 2010, A Survey on Transfer Learning).
Transfer learning is a technique in ML in which knowledge learned from a task is re-used in order to boost performance on a related task.
Nowadays, we hear about `fine-tuning`, `downstream task adaptation`, `post-training`, and other terms, which all refer to the core concept of Transfer Learning.
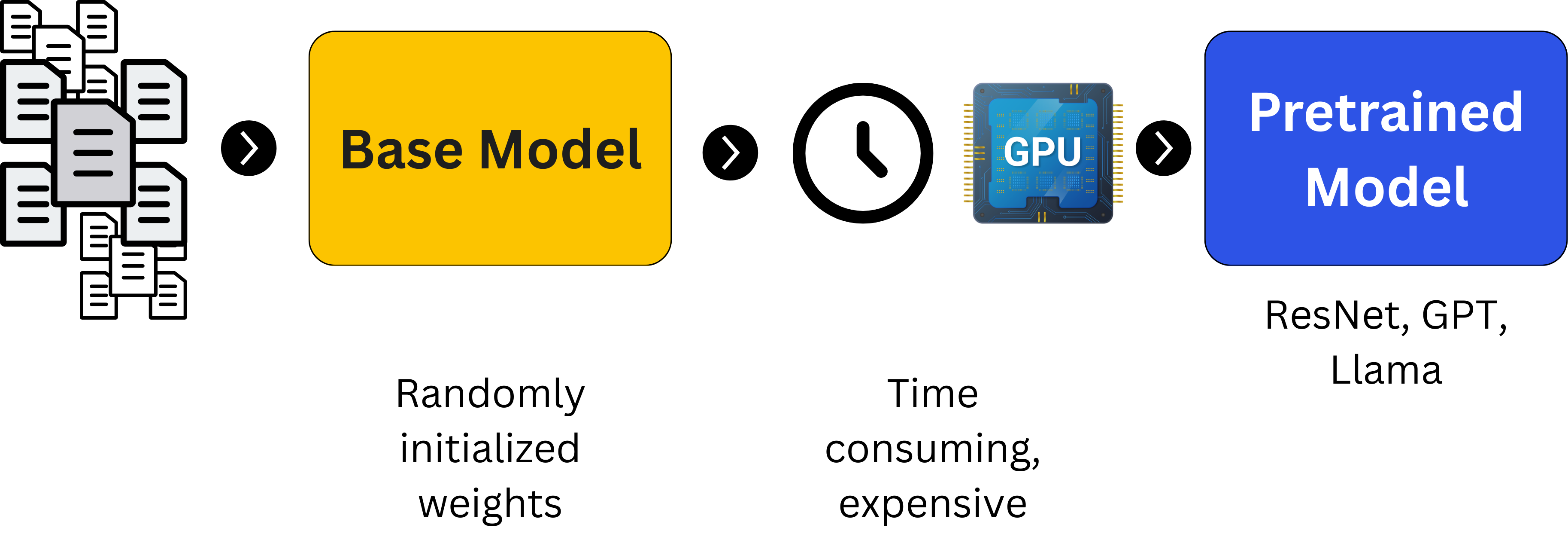
Examples
Let’s say we want to build a model that detects objects. For that, we’d select a Computer Vision model (e.g, YOLOs, RCNN) which was pretrained on the MS COCO dataset or other detection datasets, and we’ll further `finetune` it on our custom subset of objects.
The same goes for an LLM. We’d select a pretrained model on Web text, which learned to complete the next word/token in a sentence, and further `finetune` it for summarization, chat, text entity recognition, writing poetry, or other adaptations.
The difference being that for LLMs, the number of techniques one could use is far richer.
For LLMs, we have SFT (Structured Finetuning), RLHF (Reinforcement Learning from Human Feedback), RLAIF (R.L from AI Feedback), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), and many other methods.
To group all these, the term `post-training` is widely used within the field, and it makes the most sense.
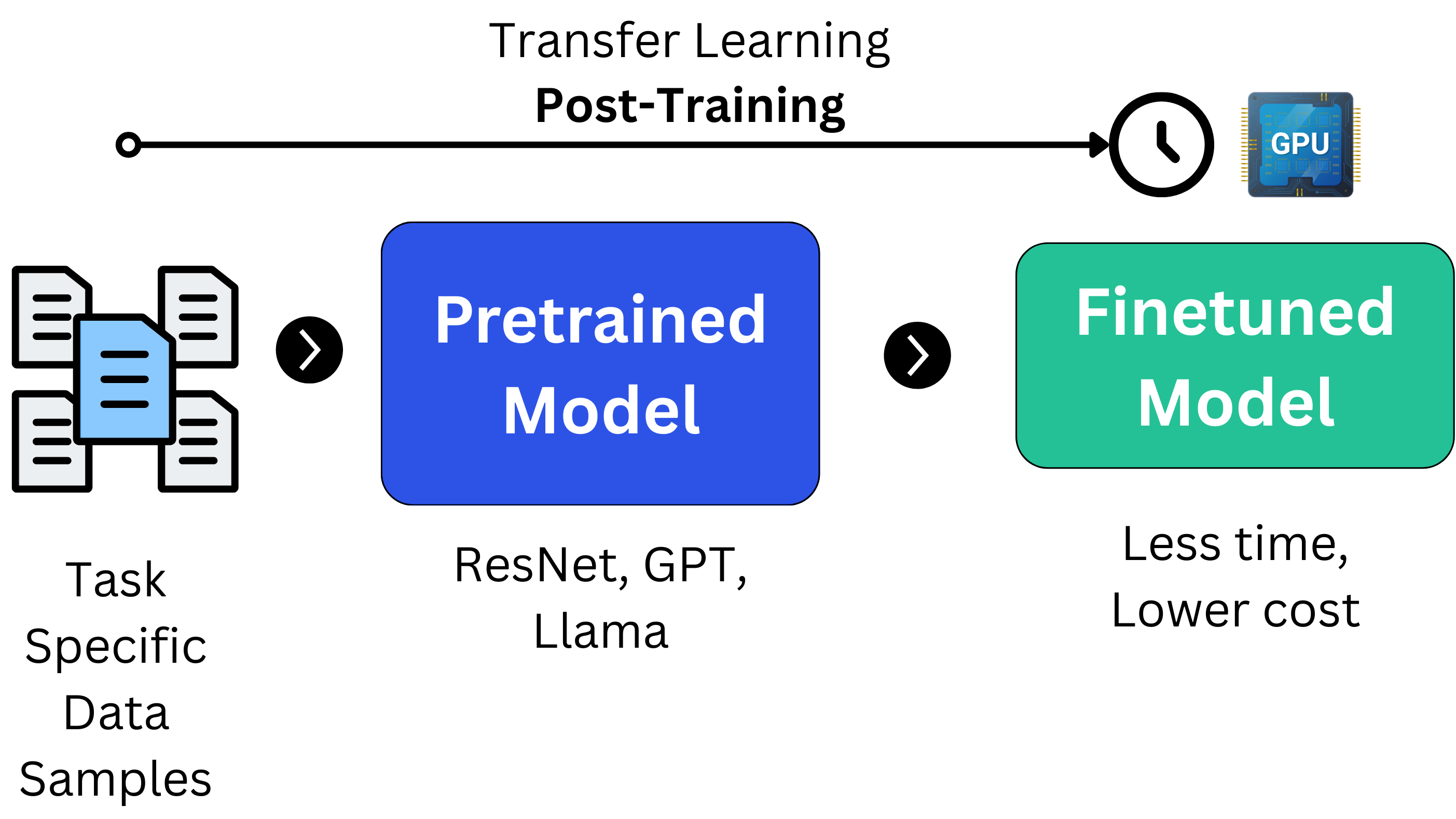
Model Deployment
Model deployment and monitoring is the phase where most AI/ML Engineers would work in as it connects the research-engineering gap. This phase includes optimizing the model, packaging it into serving infrastructure, integrating with APIs and applications, and monitoring the end-to-end system.
Even if a model performs well in pre-deployment tests or evals, what ultimately matters in production are its performance metrics with regards to the entire AI System it is in.
These performance optimizations could be grouped into 2 categories:
System-wide, which focuses more on the infrastructure part with model parallelisation across multiple GPUs or multiple Nodes, distributed processing of model feed-forward stages, caching, or speculative decoding (LLMs).
Model-wide optimizations are applied at the model level, and these include quantizations, pruning, Knowledge Distillation via Teacher/Student, or model compilation.
You could learn more about these two categories of optimizations, on LLMs specifically by reading one of my previous articles:

Examples
With traditional Deep Learning models, such as the ones for vision-based tasks of tracking an object in a video or removing the background of an image, we would quantize or compile them on specific GPU hardware to reduce the latency and size of the model, making it run faster.
When running AI on video, each second, there are ~30 different frames we could send to the model for inference, and since a large majority of Vision AI has to run in real-time, we need lightweight, fast models.
In the case of LLMs, inference is a bit trickier as it’s composed of 2 stages: prefill and decode, the former being highly parallelizable, and the latter running sequentially.
Apart from this, LLMs are large, thus one GPU might fit the model weights, but will crash due to OOM (Out of Memory) during inference, because layer activations also have to be stored in memory.
Optimizations for large models such as LLMs include sharding the model across different GPUs (TP = Tensor Parallel, PP = Pipeline Parallel), FlashAttention (fusing attention operations into a single GPU kernel), and efficiently storing the KV-Cache for further re-uses.
Having covered the optimizations we could apply, let’s get practical and study what Inference Engines are, how they work, and which one to choose.
Inference Engines and Inference Frameworks
An inference engine is a specialized runtime designed to execute trained models efficiently on hardware. Between a trained model, which is usually in its default PyTorch (.pt), TensorFlow (.tf2) format, and a serving framework such as NVIDIA Triton Inference Server, FastAPI, TorchServe, BentoML, or Tensorflow Serving, there is an inference engine.
An inference engine optimizes a model to balance latency, throughput, precision, and efficiency for it in a production scenario.
Commonly, inference engines do one or more of the following:
Graph Optimization
It analyzes the computational graph of the model and applies optimizations to reduce the graph size and depth, fusing model layers or removing redundant computations.Hardware-Specific Optimization
Models could be compiled for target hardware accelerators such as CPU, GPU, TPU, or custom accelerators, by selecting highly tuned compute kernels for each architecture in part.Lowering Precision
Reduces the memory footprint by quantizing layers’ precision (e.g., FP32 → FP16 → INT8/INT4).Model Pruning & Sparsity
Pruning redundant weights or exploiting sparsity in matrices.
Since there is a major difference between traditional deep learning models and generative models, an inference engine will apply different optimizations.
General Purpose Inference Engines
These include the traditional compilers such as ONNX Runtime, TensorRT (NVIDIA), OpenVino (Intel), and CoreML (Apple).
From the above-mentioned list, only ONNX Runtime is cross-compatible with multiple accelerators.
Let’s see why.
ONNX and ONNX Runtime
ONNX stands for (open-neural-network-exchange) and is an open-source standard for representing deep learning models. An ONNX model is a serialized file containing the computation graph, architecture, weights, and other parameters.
When we convert a model to ONNX, the graph of operations is represented in an internal format (ONNX IR), which can be interpreted by other Inference Engines that will further transform this IR into their internal representation.
An important to be made is that ONNX is a model format, we could use to serialize a model into, whereas ONNX Runtime is an Inference Engine that can run ONNX models.
When we run inference via ONNX Runtime, an inference session object is created, which loads the model graph, decodes the operator, and partitions the graph of operations based on the Execution Provider.
Execution providers in ONNXRuntime are the target platforms the model should be optimized for (CPU, CUDA, ROCm).
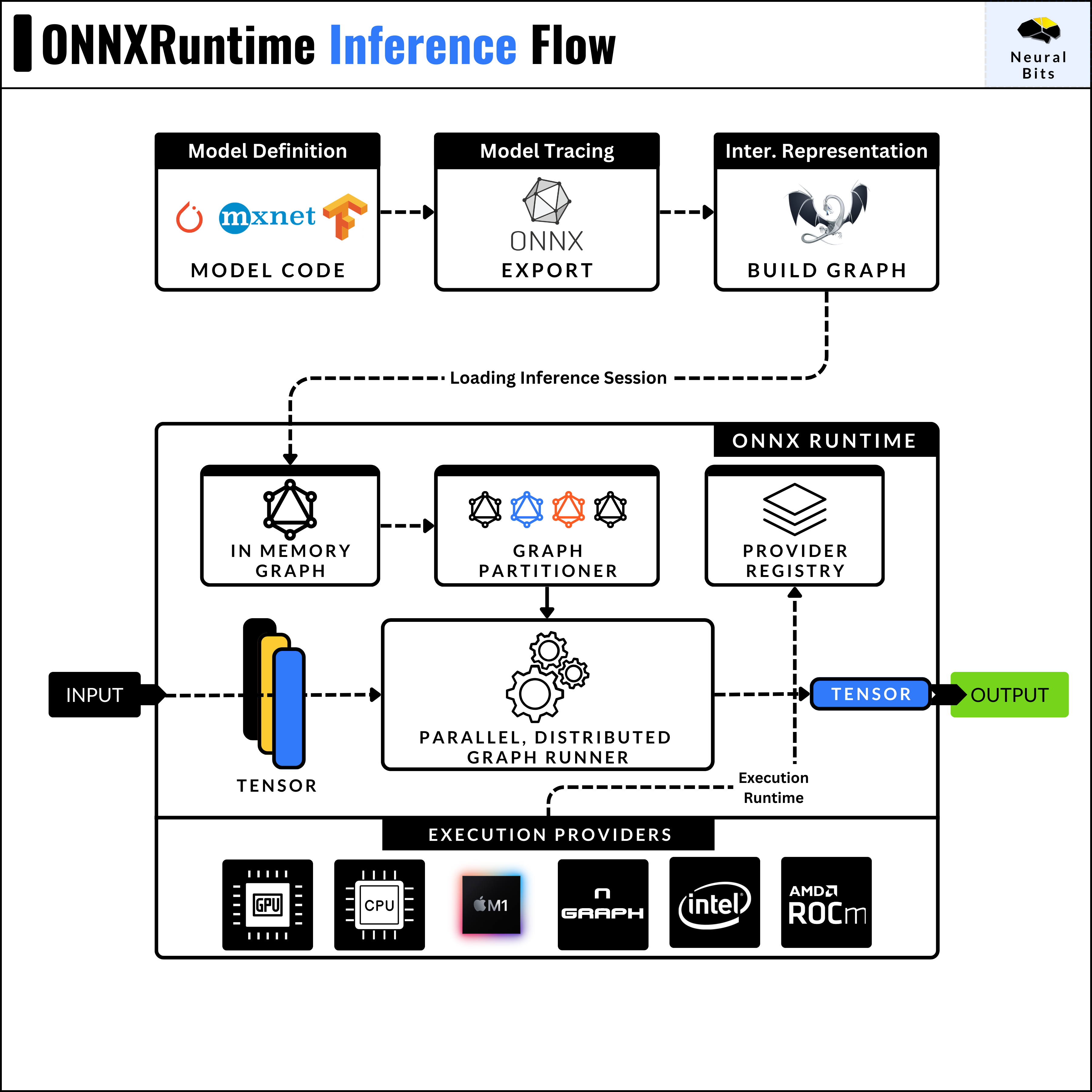
After you’ve converted a model to the ONNX format, you can view its graph architecture using Netron, which is a JavaScript application that parses model files. Research engineers often use Netron to analyze models.
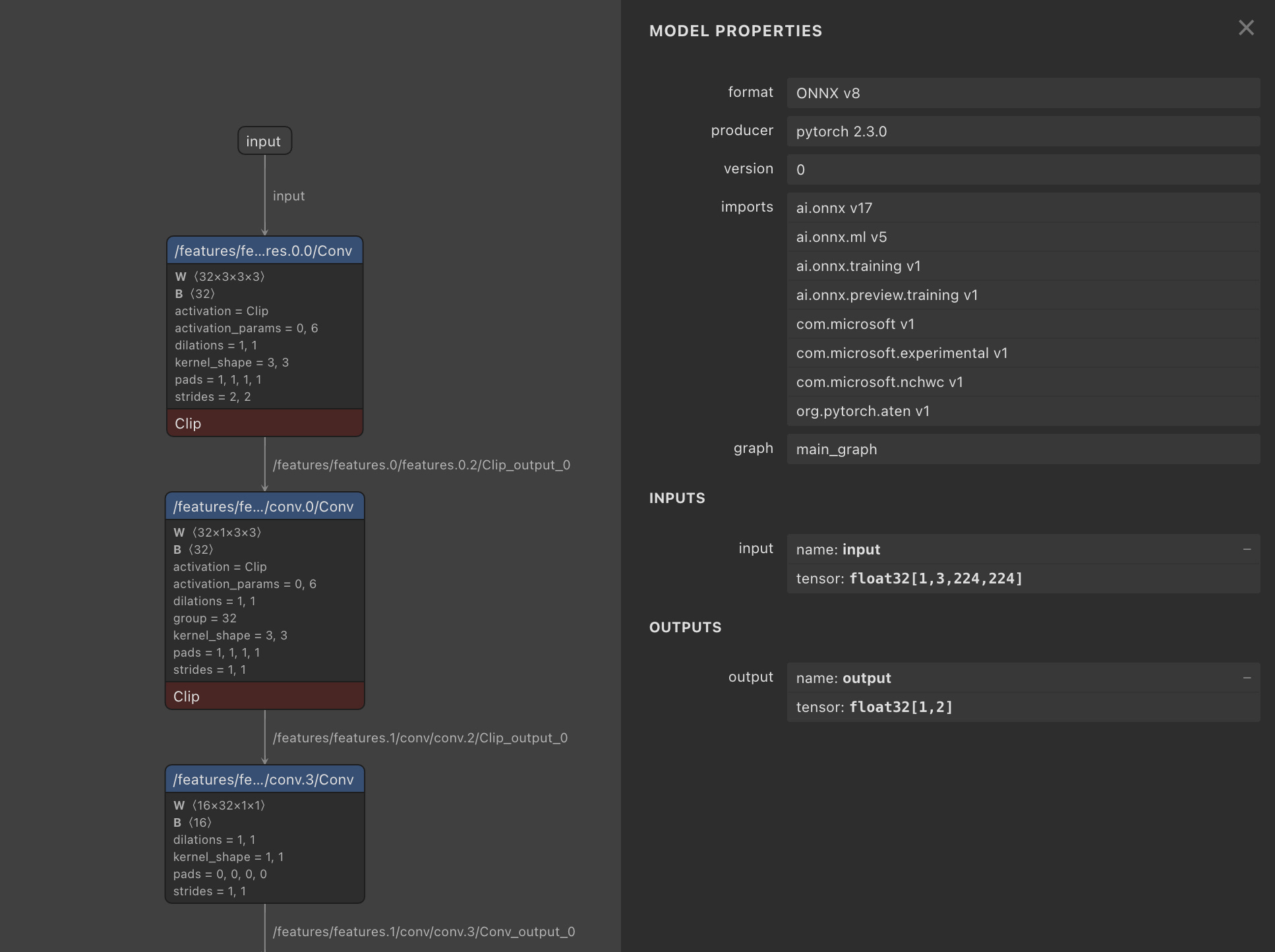
From ONNX, a model could be further converted into other Inference engine formats, such as OpenVino for Intel CPUs and GPUs, Core ML for Apple devices, or TensorRT for NVIDIA GPUs.
NVIDIA TensorRT
The TensorRT compiler is specifically designed to maximize performance on NVIDIA GPUs, due to its low-level integration with the underlying CUDA kernels, cuDNN routines, and NVIDIA GPUs.
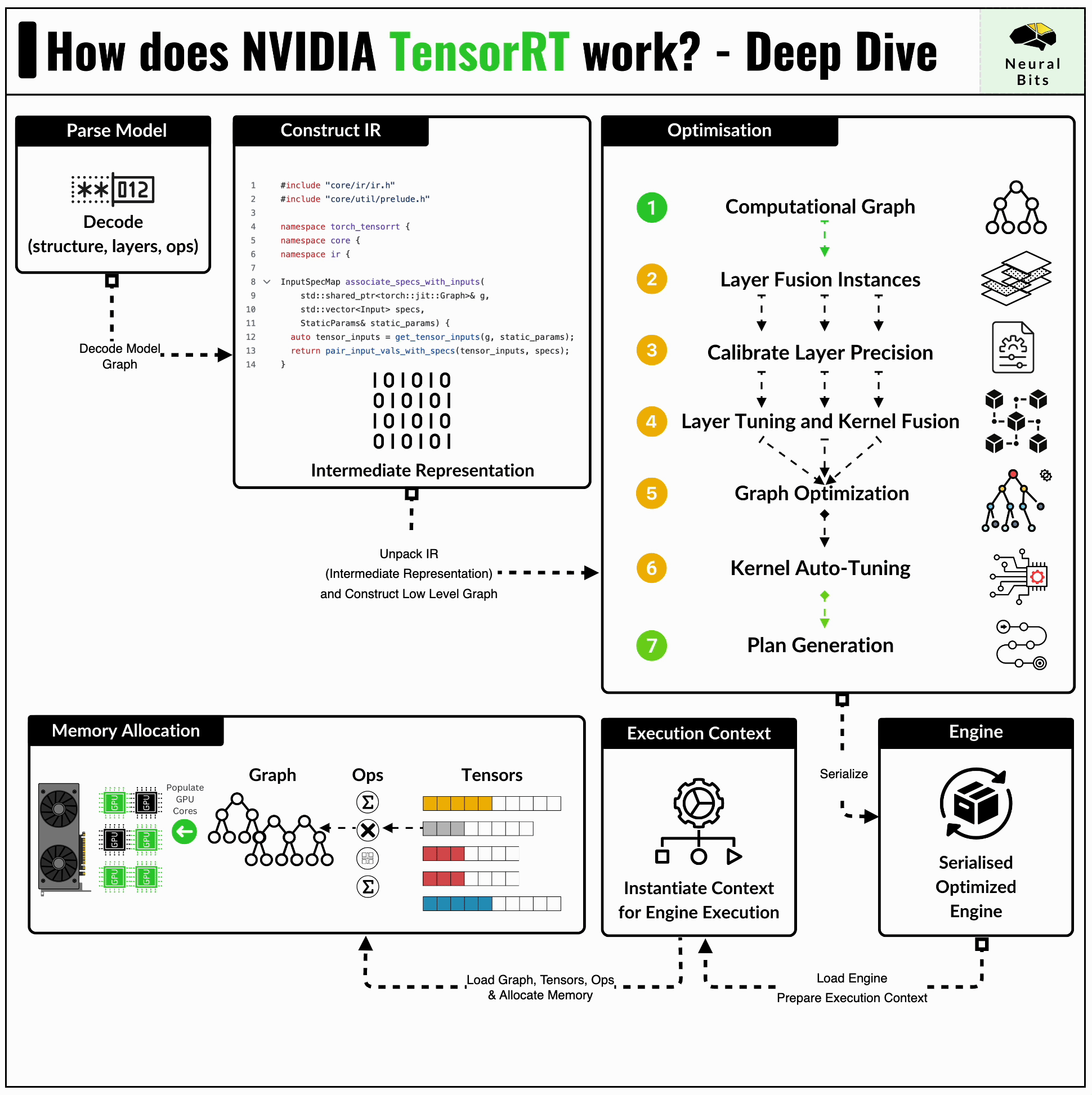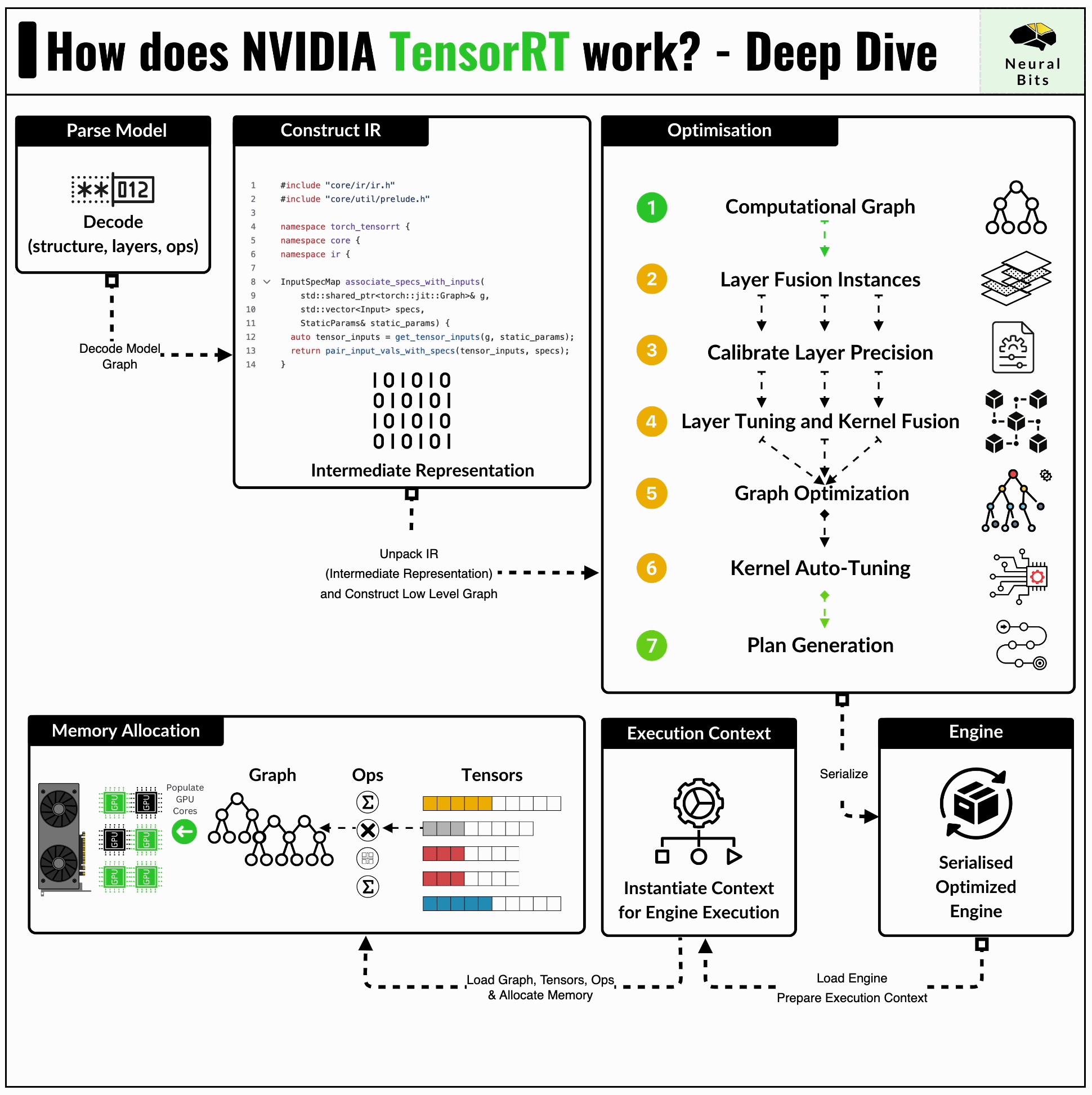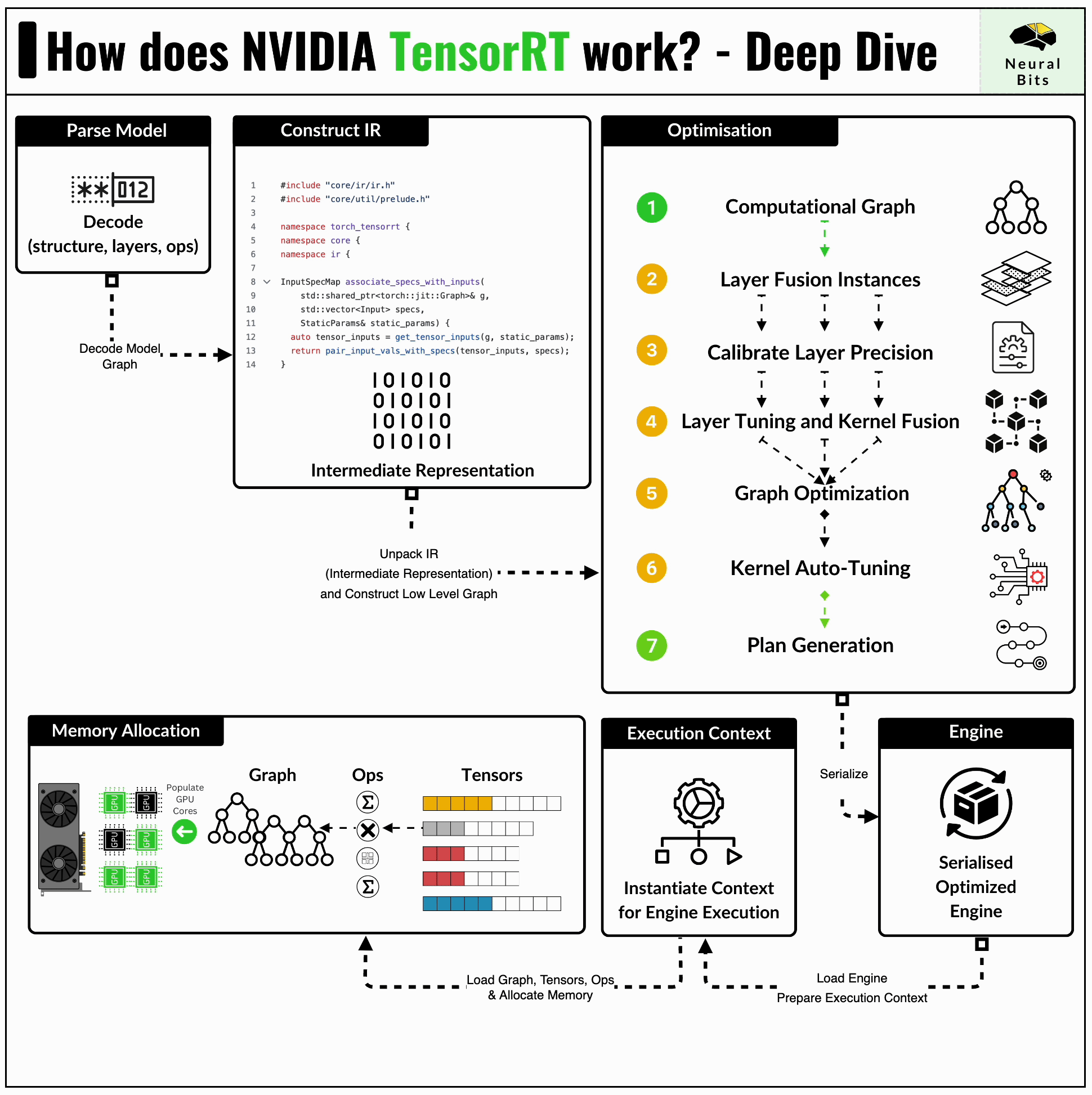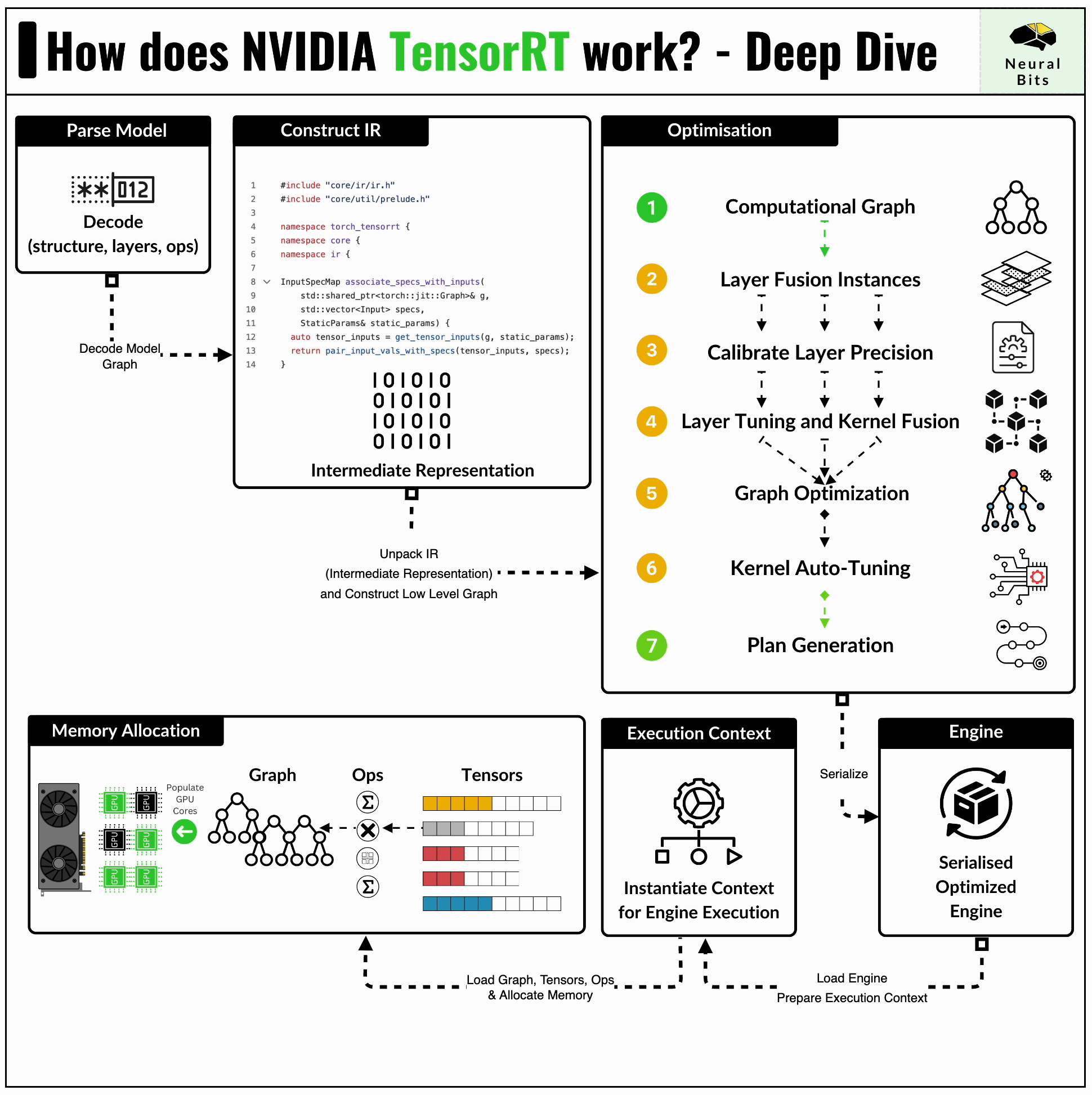
Before compiling a model to TensorRT, one would have to convert it to the standardised ONNX format first. Further, TensorRT applies a series of optimizations that are closely related to the NVIDIA GPU architecture this model is built for.
When using TensorRT, if we compile a model for the A100 GPU, we’ll have to repeat the entire process for other GPUs.
TensorRT is tightly related to how many CUDA and Tensor Cores, how many SM (Streaming Multiprocessors) a GPU has, what’s the overall Compute Capability (CC) of the GPU, and more.
You could learn more about GPUs, GPU Programming and CUDA by reading my previous article on GPU Programming.
Here are two key optimizations that TensorRT brings that have a large impact on performance:
Kernel Fusion - distinct kernels can be fused and calculated on a single data flow. For example, we can fuse a convolution kernel followed by ReLU, and compute the results on a single pass through the data.
Kernel Auto-Tuning - CUDA programming is based on Threads and Blocks, and kernel auto-tuning detects the optimal n_of_threads and n_of_blocks for the specific GPU Architecture, based on its CUDA Cores and Tensor Cores counts.
Because TensorRT is general-purpose, let’s walk through how an LLM model is converted into a TensorRT engine.
NVIDIA TensorRT-LLM
TensorRT-LLM is a high-level Python API to build TensorRT engines that contain transformer-specific optimizations. It provides state-of-the-art optimizations, including custom attention kernels, in-flight batching, paged KV caching, transformer quantizations (FP8, INT4, SmoothQuant), speculative decoding, and much more, to perform inference efficiently on NVIDIA GPUs.
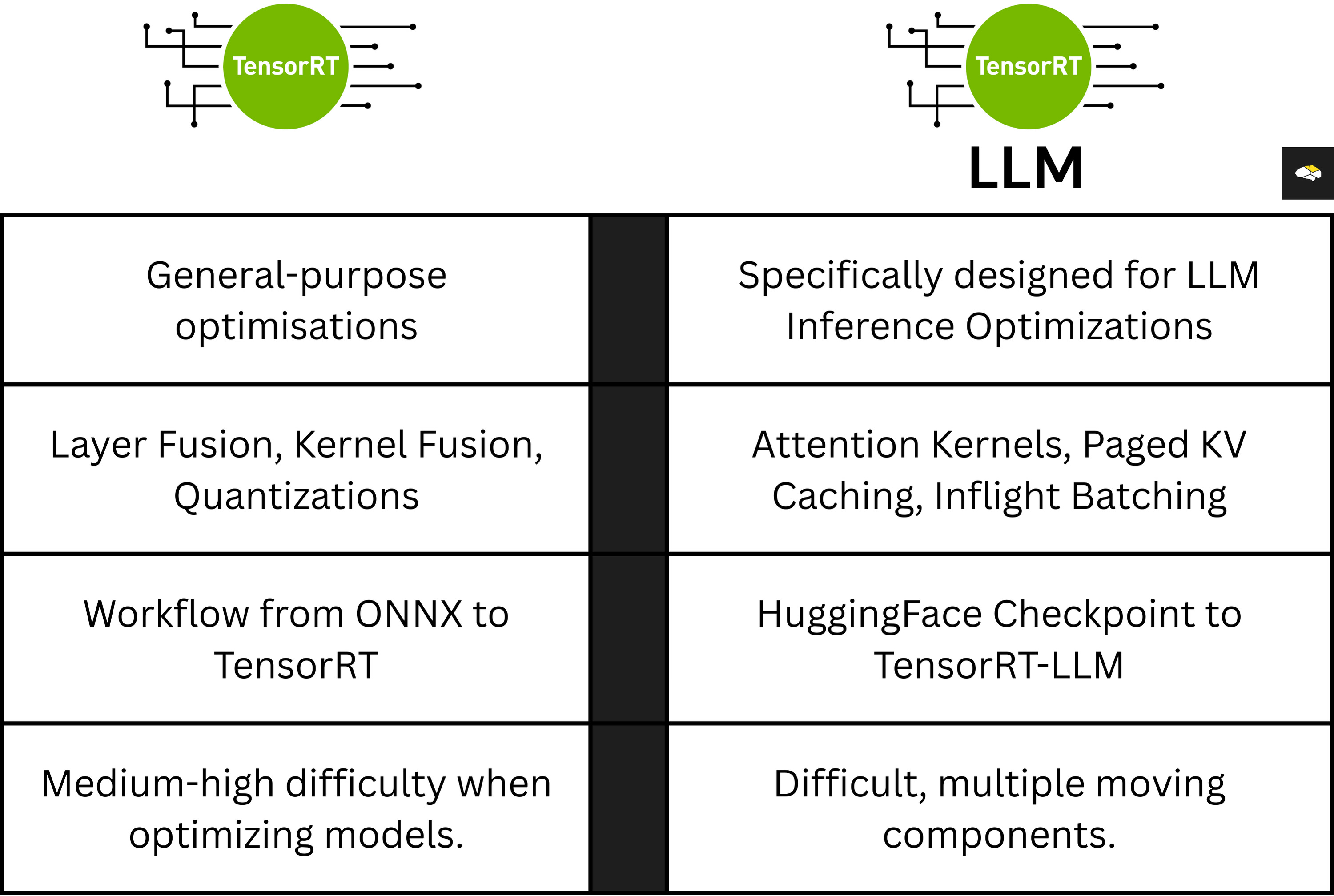
To optimize an LLM using TensorRT-LLM, the team at NVIDIA published the code workflow for each LLM variant. For example, Llama models follow a different optimization configuration than Gemma or Mistral models.
To find the model compatibility and steps to optimize and serve TensorRT-LLM engines, see the library models section on GitHub.
With TensorRT-LLM, after optimizing a model, we don’t get a monolithic engine file, but multiple sub-engines connected as a pipeline.
Each sub-engine is responsible for a part of the model in the inference workflow:
Tokenizer Engine - this is the optimized model that does token-preprocessing before passing the sequence to the LLM.
The Transformer Model - this is the TensorRT engine of the transformer model.
Detokenizer Engine - this block decodes token IDs back to text tokens, also integrating in-flight-batching and optimized kernels.
The BLS Model Pipeline - this is the pipeline composer, a Business Logic Scripting module chaining the blocks.
TensorRT-LLM is designed for large-scale deployments, squeezing the best out of the GPUs. Simpler engines that have comparable results on latency for small-mid scale deployments are vLLM and SGLang.
vLLM and vLLM + Ray
vLLM is a high-throughput and memory-efficient inference engine for serving Large Language Models. It was originally developed in the Sky Computing Lab at UC Berkeley, and it quickly evolved into a community-driven project. Being built mostly in Python (80+%) with a bit of CUDA and C++ (~13%) for Attention kernels and other optimizations, vLLM became popular amongst AI Engineers who need to deploy LLMs at scale.

Amongst the optimizations vLLM brings to the table, two key techniques that improve performance are Paged Attention and Continuous Batching.
1/ Smarter Memory Management with Paged Attention
Paged Attention is a mechanism for efficient management of attention key and value memory, which could improve LLM serving ~24x using 50% less GPU memory compared with traditional methods.
In LLM inference, having a starting prompt, the prefill phase computes the initial attention states Keys (K) and Values (V). Next, with each decoding step, we get a new token into the sequence (i.e, completion tokens) and the K, V states have to be updated.
To avoid computing these states on each iteration, vLLM uses Paged Attention to store previous states, and re-computing only the current token state.
2/ Continuous Request Batching
Static batching waits for all sequences in a batch to finish. For LLMs, since inference requests will have different lengths, continuous batching dynamically replaces completed sequences with new ones at each iteration.
This allows new requests to fill GPU slots immediately, resulting in higher throughput, reduced latency, and more efficient GPU utilization.
You could dive into more detail about vLLM, and learn how to get started with vLLM by reading my previous article.

One important add-on to vLLM is LMCache, which adds a different layer on how vLLM processes and reuses the KV Cache in its built-in Paged Attention mechanism.
LMCache aims to reduce TTFT (Time To First Token) and increase throughput, especially under long-context scenarios. Compared to other serving frameworks, it caches reusable texts across various locations, including (GPU, CPU DRAM, Local Disk), caching entire reused text KV Cache, not only prefixes.

This next set of Inference Engines is more specialized, either architecture-bound bound such as CoreML for Apple Devices, or use-case bound, such as llama.cpp for LLMs.
1/ CoreML
CoreML is Apple’s framework for on-device inference. Models in this format leverage the unified CPU & GPU memory and the Neural Engine components in Apple chips.

On Apple devices, all memory is unified. You no longer need a separate GPU with dedicated VRAM because the entire model is loaded into the shared memory pool (RAM + GPU + CPU).
See this tutorial on how to port Llama-3.1 with CoreML.
The CPU, GPU, and Neural Engine can access model parameters directly from this unified memory, without transferring data back and forth, which allows developers to load larger models.
See this benchmark on running DeepSeek R1 on a MacBook Pro M2.
2/ Intel OpenVINO
OpenVINO is an open-source toolkit developed by Intel for optimizing and deploying deep learning models. It enables AI inference on a variety of Intel hardware, including CPUs, GPUs, and VPUs, with a "write-once, deploy-anywhere" approach.
Initially, OpenVINO was popular for computer vision models, since most AI deployments that needed to run efficiently on smaller devices or at the edge were based on vision tasks. As a result, OpenVINO was heavily optimized for CV and CNN-based models.
Today, OpenVINO also provides a GenAI blueprint to optimize and serve LLMs using the OpenVINO runtime. To do that, you could either use the `optimum-cli` from HuggingFace to convert your LLM to OpenVino format, or download a pre-compiled OpenVino profile.

Find more about OpenVINO and OpenVINO GenAI in the official docs.
3/ LLama C++
llama.cpp is a high-performance C/C++ inference engine to run LLMs locally with minimal dependencies. Being built in a low-level language, and with every system being able to run C and C++, it’s compatible with a wide range of target architectures, making it portable.

Based on your system architecture, llama.cpp binaries are built with the appropriate backends, such as:
BLAS (Basic Linear Algebra Subprograms) for all architectures
CUDA for NVIDIA GPUs.
HIP for AMD GPUs.
MPS (Metal Performance Shaders) for Apple M-series.
In this context, a backend is nothing more than an execution engine that translates model operations into hardware-specific instructions.
See the full list of supported llama.cpp Backends.
One key component of the llama.cpp ecosystem is the GGUF binary model format. On HuggingFace, the recommended model storage format is safetensors, which stores tensor-only data. GGUF is llama.cpp compatible, and it stores tensors and rich metadata.

GGUF standardizes how weights, tokenizers, and metadata are stored, making models portable across different backends (CPU, CUDA, Metal, Vulkan, etc.), enabling faster model loading times.
See this extensive tutorial, on getting started with llama.cpp.
Serving Frameworks
Having covered a majority of Inference Engines, the next component of an AI Inference stack is the Serving Framework. Besides parsing the inference engine and executing it, a Serving Framework takes care of managing the inference server.
This includes system-wide optimizations, batching, request-response mapping, and more.
In this section, we’ll describe 4 Serving Frameworks while using the LLM serving use-case. We won’t cover TorchServe or TensorFlow Serving, as these are more general-oriented.
1/ Hugging Face TGI - Text Generation Inference
TGI is a toolkit for deploying and serving LLMs, enabling high-performance text generation for the most popular open-source LLMs.
As with any other Serving Framework, TGI is built on two components: a Web Server in Rust to handle batching and request routing, and the LLM Executor from the HuggingFace Transformers library to run the token sequence through the LLM.
Notable system-wide optimizations that TGI offers are:
Tensor Parallel - to distribute larger models as shards on multiple GPUs.
FlashAttention plugin that fuses the Attention operations as a single kernel, to reduce the memory footprint and increase token throughput.
Continuous Batching and Paged Attention

Find more about TGI and how to get started.
2/ Ollama
Ollama can be considered as a wrapper over llama.cpp, to serve LLMs locally.
Similarly to TGI on the architecture side, Ollama runs GGUF models through llama.cpp as the Inference Engine, but builds an optimized Web Server in GO to handle batching, system-wide optimizations, or request-response routing.
Getting up-and-running with llama.cpp is no easy-feat, and Ollama aims to simplify that by providing an easy-to-use workflow to run LLMs.

With Ollama, you can download the installer and launch it, which will automatically start an Ollama Server and keep it alive. Further, using the Ollama UI or the CLI, you could pull models and serve them.
In reality, Ollama models are GGUF profiles stored under the Ollama’s own model format called Modelfile. These GGUFs are executed by llama.cpp underneath.
Ollama provides the ecosystem around it.
Ollama Server exposes OpenAI-compatible API endpoints you could integrate further into your applications.
Find more about Ollama, how it works and how to get started.
3/ Triton Inferece Server
NVIDIA’s Triton Inference Server is one of the most mature and production-ready serving frameworks out there. Even if its learning curve is high and is quite complex to master, Triton Server is strictly optimized for AI workloads in production.
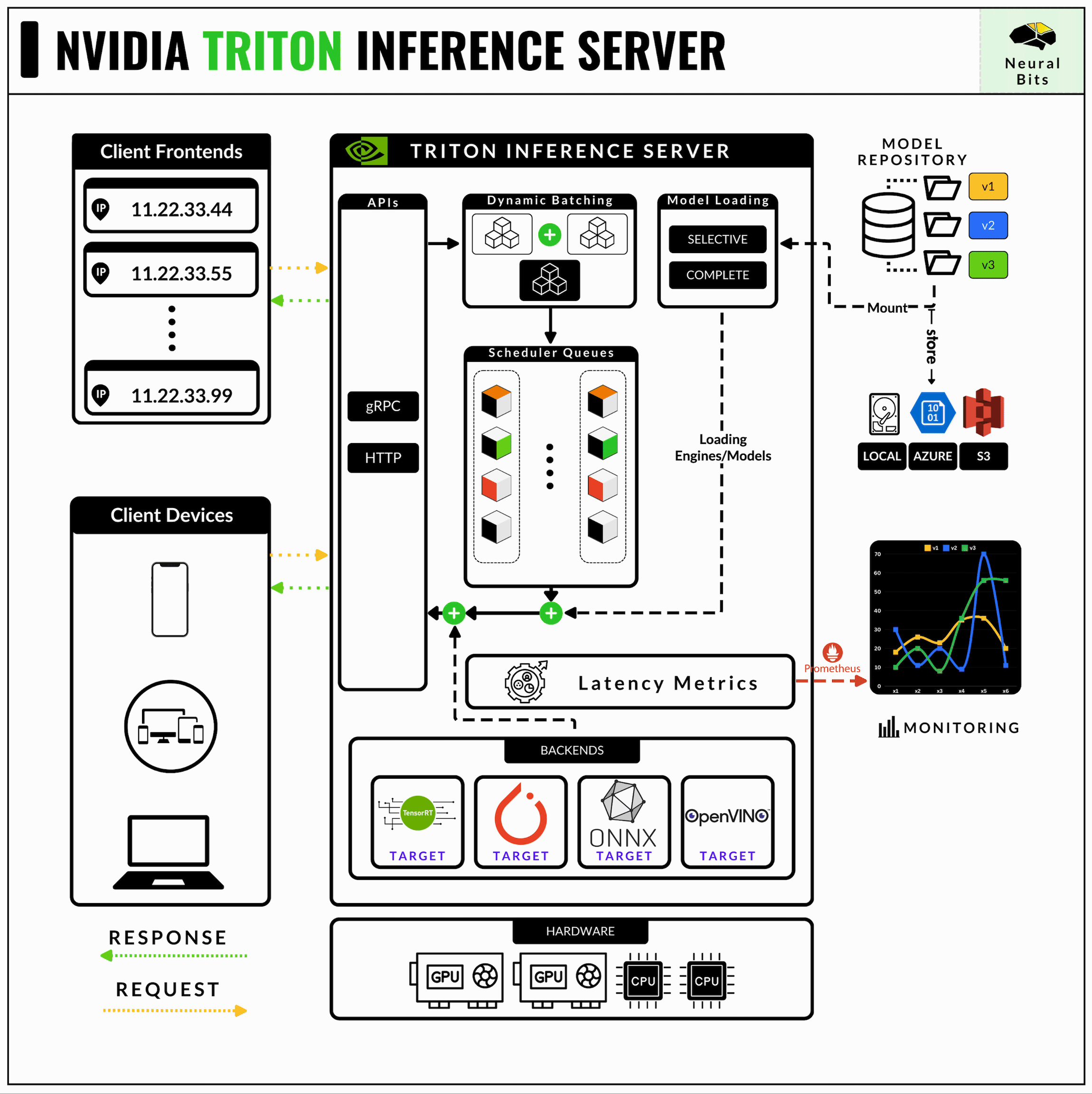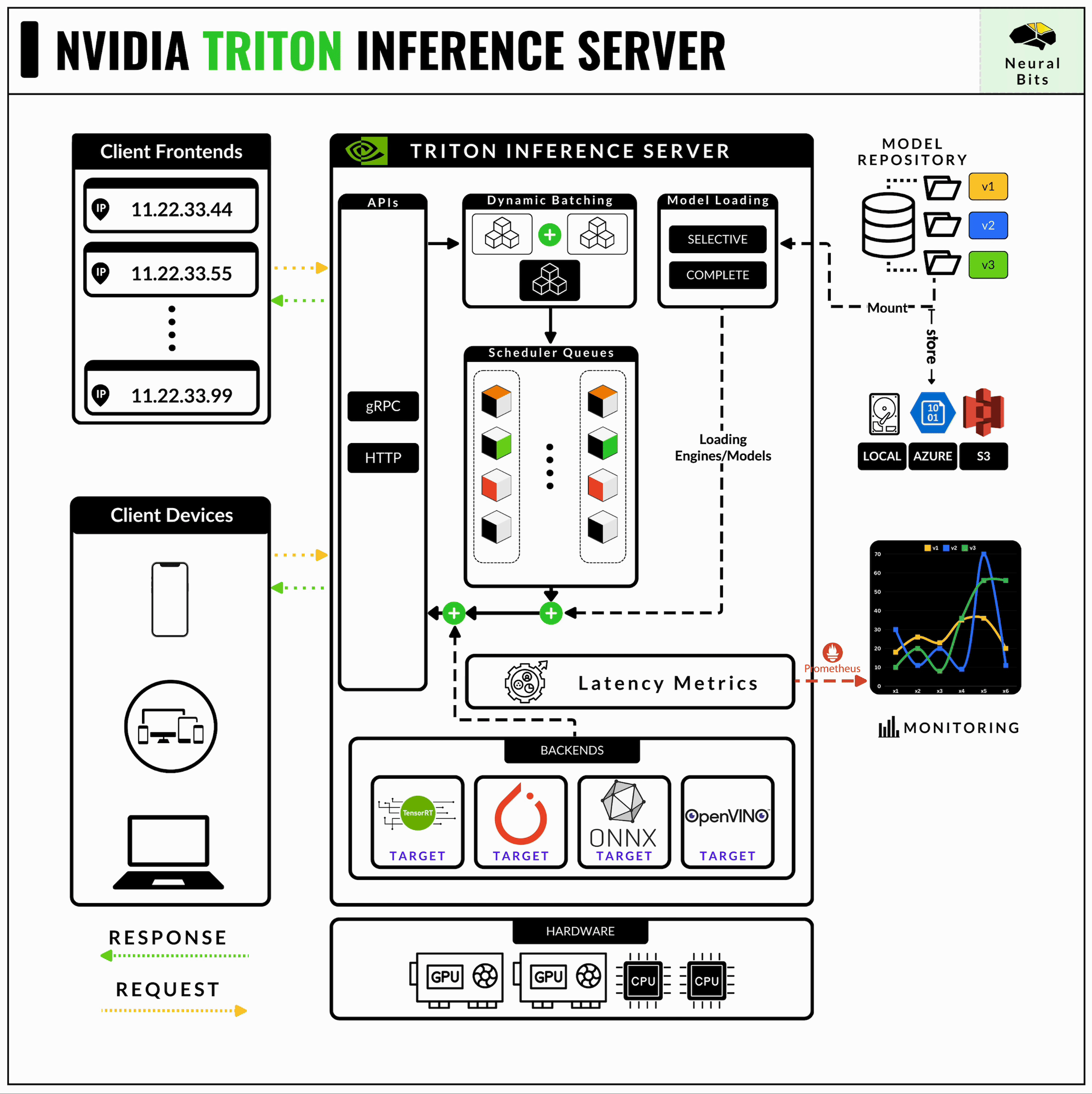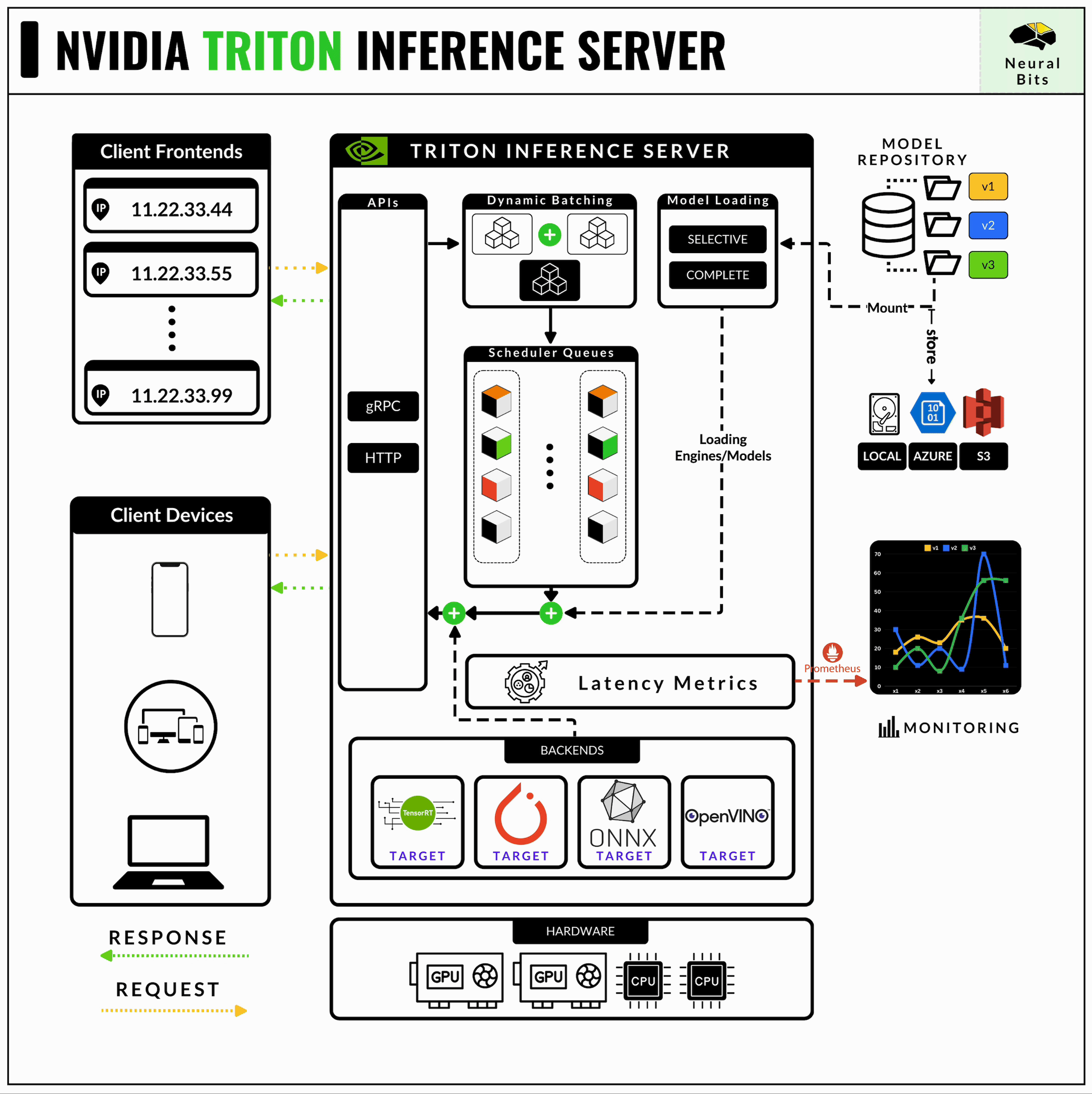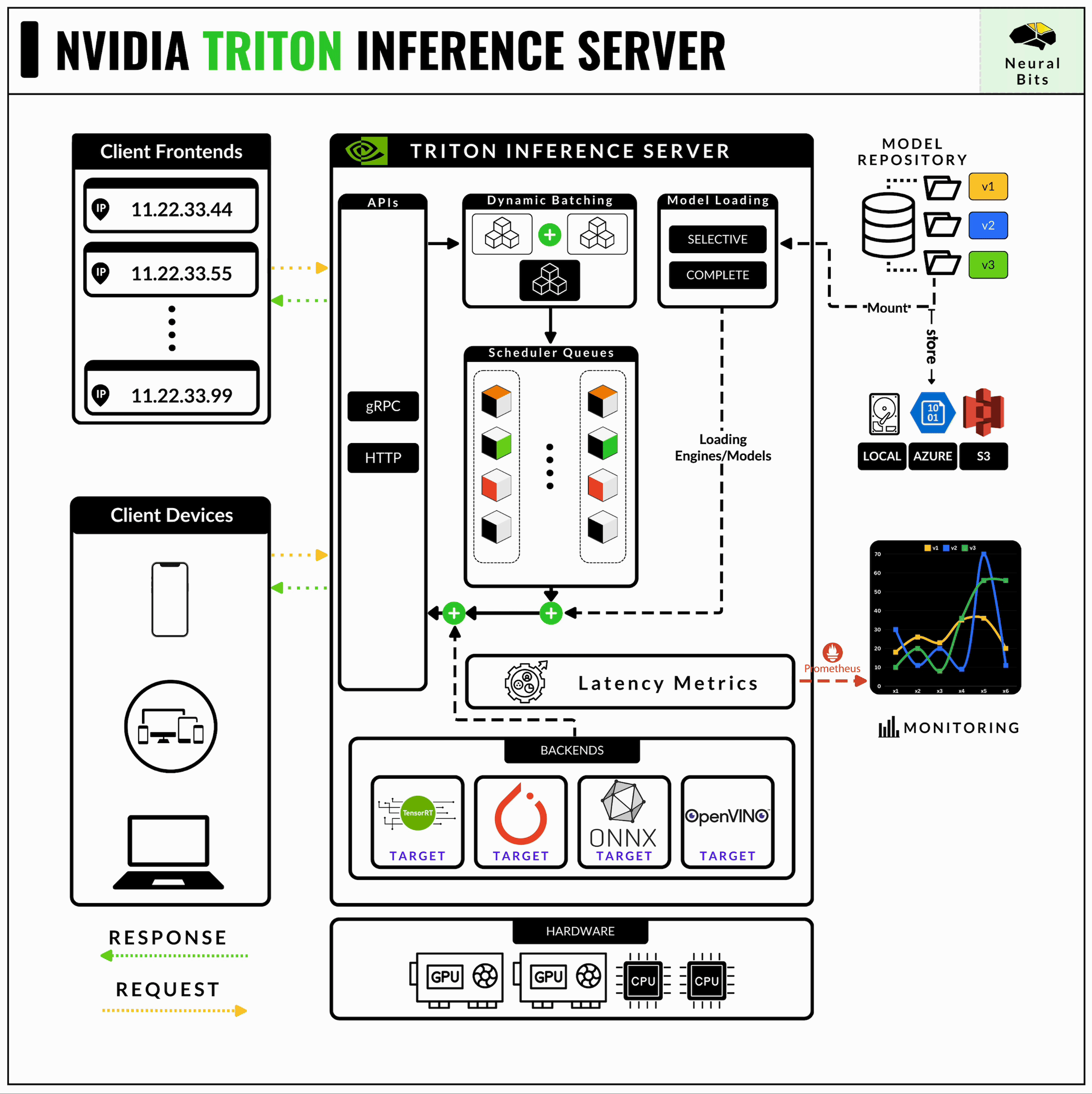
NVIDIA Triton Server supports multiple Inference Engines, such as TorchScript, TensorFlow, ONNX, TensorRT, and, more recently, it can also serve TensorRT-LLM engines.
Learn more about NVIDIA Triton Server in this hands-on article.

Distributed Inference Frameworks (LLMs)
1/ NVIDIA Dynamo
Dynamo is the newest serving framework from NVIDIA that focuses strictly on LLM inference. Referred to as `Triton Server successor`, Dynamo focuses on distributed inference of large LLMs and particularly Reasoning LLMs.
One of the key optimizations of Dynamo is Disaggregated Serving.
If you remember, LLM inference has two stages, prefill and decode, with the decode part predicting one token at a time - Dynamo focuses on parallelizing the decode stage on multiple GPUs or Nodes.
Dynamo supports and can serve both TensorRT-LLM and vLLM engines, with the former getting the SOTA results on NVIDIA GPUs.

One key component of Dynamo is the NIXL (NVIDIA Inference Xfer Library), which enables high-performance point-to-point communication, allowing for the KV-Cache computed on a set of distributed nodes to be accessed and shared fast, reducing the time it takes for prefill & decode inference steps.
Check this previous article with a full, in-depth walkthrough of NVIDIA Dynamo.

2/ AirBrix (backed by vLLM Team)
Similar to Dynamo, AirBrix is an open-source initiative designed to provide essential building blocks to construct scalable GenAI inference infrastructure, built by the same team behind vLLM.
Airbrix distributes the inference infrastructure on top of a Kubernetes cluster, with the Control Plane handling the Model Metadata stores, which could include LoRA Adapters or fully-finetuned model checkpoints, Load Balancing, the Autoscaler of Inference Endpoints, and Controllers.
The actual inference workload is distributed across a set of Kubernetes Pods, with each Pod serving a vLLM Engine with a built-in Model Loader, WatchDog for metrics, and autoscaling triggers. To share the KV-Cache across multiple vLLM Instances, AirBrix uses KV-Cache-specific pods, mounted as side-cars to the runtimes serving the models.
For cross-pod KV-Cache, AirBrix could also use the NVIDIA NIXL Library.

3/ vLLM + LLM-D (Kubernetes)
llm-d follows the same principles of AirBrix and Dynamo. It uses vLLM as model server and engine, Inference Gateway as request scheduler and balancer, and Kubernetes as infrastructure orchestrator and workload control plane.
To share KV-Cache across Pods and Nodes, it can also use NVIDIA NIXL or DCN libraries, and for pod-persistent independent KV-Cache, it can use LMCache or Host Memory.

Other Interesting Frameworks
Mojo and Mojo MAX Engine
Developed by Modular, Mojo aims to combine the flexibility and usability of Python with the raw performance of languages such as C++ or Rust.
Mojo is designed to become a superset of Python, focusing on familiar syntax while adding systems-level features for performance and control.
An AI Engineer wants the performance without having to write custom kernels for every accelerator, such as CUDA for NVIDIA GPUs or ROCm for AMD. Mojo’s ambition is to make this possible.
To understand how, let’s go through a few details at the compiler level.
Python is an interpreted language. The source code you write is compiled into bytecode, which the CPython interpreter executes through its virtual machine.
Mojo, like C++ or Rust, is a compiled language, but it works differently. In C++, for instance, if you build a library for x86 CPUs, you need to rebuild it again for ARM64 (e.g, Apple M-series chips).
Mojo avoids this limitation by building on LLVM. Instead of targeting one architecture directly, it translates source code into MLIR (Multi-Level Intermediate Representation). MLIR contains a set of different dialects with primitives for multiple hardware targets (NVIDIA, AMD, TPU, CPU, etc.).
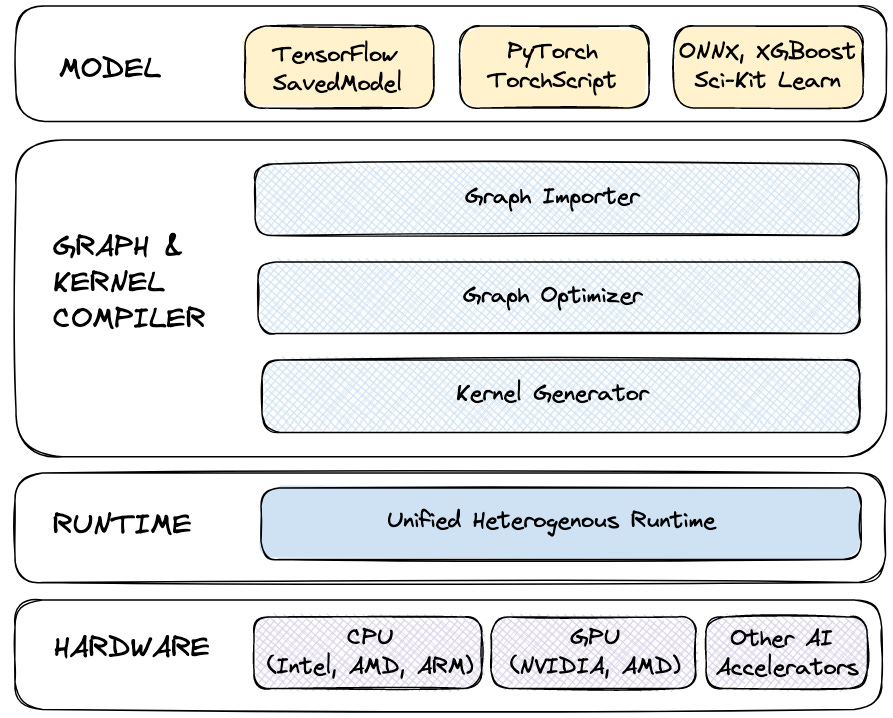
MAX Engine is Modular’s next-generation compiler and runtime library for running AI inference and serving AI Models.
Similar to other serving frameworks, MAX Engine can take a trained model either in PyTorch (TorchScript), ONNX, or native Mojo formats, and serve it on a wide range of hardware, based on the principles discussed above.

2/ LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM.

Conclusion
In this article, we started by explaining the phases of Model Development and Deployment, a workflow that every AI model likely follows. We covered pre-training, post-training, and what to consider before deploying an AI model as part of a larger System.
On that topic, we covered a wide range of AI inference engines and serving frameworks, each designed for different deployment scenarios.
Each has its strengths, and in only a few cases will one be better than another. The core optimizations are the same overall, with minor changes in between.
As a rule of thumb:
→ Use OpenVINO when your deployment targets are Intel CPUs and GPUs.
→ For Apple devices, focus on CoreML and llama.cpp.
→ To test things out and run LLMs locally, go with Ollama.
→ To debug models and store them in a standardized, multi-compatible format, you might want to choose ONNX.
→ Experimental yet promising is the Mojo MAX Engine, which is cross-compatible with any type of hardware.
→ For a large majority of LLM deployments, vLLM is enough.
→ If you want more control, with more complexity, choose llama.cpp
→ For real large-scale deployments, stick to TensorRT and TensorRT-LLM Inference Engines and choose NVIDIA Triton, NVIDIA Dynamo, vLLM + llm-D or AirBrix for large-scale distributed inference.
The key takeaway: there is no one-size-fits-all runtime.
The right choice depends on your hardware, your latency vs. throughput needs, and whether your model is running in the cloud or on the edge.
-
Thank you for reading, hope you learned a lot!
See you next week!
References
What Is Transfer Learning? A Guide for Deep Learning | Built In. (2022). Built In. https://builtin.com/data-science/transfer-learning
Lambert, N. (2025, January 8). The state of post-training in 2025. Interconnects.ai; Interconnects. https://www.interconnects.ai/p/the-state-of-post-training-2025
ONNX Runtime | Home. (2025). Onnxruntime.ai. https://onnxruntime.ai/
Shah, A. (2024, February 21). NVIDIA TensorRT-LLM Revs Up Inference for Google Gemma. NVIDIA Technical Blog. https://developer.nvidia.com/blog/nvidia-tensorrt-llm-revs-up-inference-for-google-gemma/
Razvant, A. (2024, August 6). 3 Inference Engines for optimal model throughput. Substack.com; Neural Bits. https://multimodalai.substack.com/p/3-inference-engines-for-optimal-throughput
Razvant, A. (2025, March 27). How does vLLM serve LLMs efficiently at scale? Substack.com; Neural Bits. https://multimodalai.substack.com/p/unpacking-vllm-distributed-inference
Core ML | Apple Developer Documentation. (2025). Apple Developer Documentation. https://developer.apple.com/documentation/coreml
openvinotoolkit/openvino: OpenVINOTM is an open source toolkit for optimizing and deploying AI inference. (2025, June 18). GitHub. https://github.com/openvinotoolkit/openvino
GGUF. (2025). Huggingface.co. https://huggingface.co/docs/hub/en/gguf
ggml-org/llama.cpp: LLM inference in C/C++. (2025). GitHub. https://github.com/ggml-org/llama.cpp
Text Generation Inference. (2025). Huggingface.co. https://huggingface.co/docs/text-generation-inference/en/index
Ollama. (2025). Ollama. https://ollama.com/
Reminder: You don’t need ollama, running llamacpp is as easy as ollama. Ollama i... | Hacker News. (2024). Ycombinator.com. https://news.ycombinator.com/item
ai-dynamo/dynamo: A Datacenter Scale Distributed Inference Serving Framework. (2025, August 12). GitHub. https://github.com/ai-dynamo/dynamo
Team, Aib. (2025, February 21). Introducing AIBrix: A Scalable, Cost-Effective Control Plane for vLLM. VLLM Blog; AIBrix Team. https://blog.vllm.ai/2025/02/21/aibrix-release.html
LMCache/LMCache: Supercharge Your LLM with the Fastest KV Cache Layer. (2025, August 3). GitHub. https://github.com/LMCache/LMCache
Modular: MAX 24.3 - Introducing MAX Engine Extensibility. (2024). Modular.com. https://www.modular.com/blog/max-24-3-introducing-max-engine-extensibility
Images and Videos
All images are created by the author, if not otherwise stated.
This was a very informative post!
Hey Alex, thanks for the post! One question:
Do you know the best practices to scale and deploy ONNXRuntime? I recently tried scaling it by using Ray Serve to automatically create replica of my service, but despite allocating certain number of CPU cores for each replica, they all suffer from contention. Is it not the way to go, but instead one deployment per one machine? on CPU it seems to just use up every cores it can access, despite being limited / pinned to certain cpu cores