
Unpacking NVIDIA Dynamo LLM Inference Framework
Everything you need to know about Dynamo. Code, components, concepts with diagrams and details.

In the AI world, this week was NVIDIA’s GTC 2025 week.
Amongst the many announcements that Jensen made in his Keynote, the open-sourcing of Dynamo Framework is the one that will have the most impact on AI/ML Engineers.
After researching it for the past 8 hours, I can say it’s a beautiful yet powerful approach to solving LLM inference optimally and at scale, and I was just surprised by it.
This article is deeply technical, as we’re going to unpack each technical module of NVIDIA Dynamo, the same way we’ve done with NIM (Nvidia Inference Microservice) in a past article, if curious - find it here:

For Dynamo, we’re going to go over all major components, and the inner workings, what it provides, and why AI Engineers should be excited about it.

Table of Contents
Recap on the LLM Inference Process
NVIDIA Dynamo Inference Framework
What is Disaggregated Serving and the Role of the Prefill Queue
NVIDIA Inference Communications Library (NIXL) and KV Cache Transfer
Distributed Load balancing and Smart Routing
Memory Manager and Dynamo Events
Installing and serving LLMs with Dynamo
Conclusion
1. Recap on the LLM Inference process
From the previous article, we learned that LLMs are trained on a large text corpus (e.g. Trillions of tokens). The dataset for pretraining LLMs is composed of text that is passed through a tokenizer with a fixed vocabulary size of tokens. The LLM then learns to map the next token from the previous sequence of tokens.
Due to this auto-regressive nature, the inference process for LLMs splits into two stages, prefill and generation.

The prefill phase can be considered as a warmup, as it represents a first pass of the User’s query through the model, generating the first token. This populates the attention matrices, KV values, GPU memory, etc. Prefill efficiently saturates the GPU memory because the model sees the entire input context on the first prompt.
Next, let’s see the decoding (i.e generation) phase:

The generation phase is the iterative process of sampling the next token until the inference reaches a stop condition, be it predicting a special token that tells LLM to stop, or it reaches the MAX_NEW_TOKENS limit that we’ve set.
Generation is memory-bound, meaning that the speed at which weights, keys, values, and activations are transferred to the GPU from CPU memory is slower than the actual compute time required to get these in the first place.
For more details on this topic, here is the full article.

With this summary in mind, we can conclude two things:
Firstly, the prefill happens once per request, and it’s highly parallelizable.
Secondly, the decoding is iterative and each new token “requires” computation of the previous KV states of the sequence. To mitigate that and avoid recomputation, KV pairs can be cached in GPU memory and loaded on demand - a concept known as KV Caching.
KV caching is a core optimization feature that many LLM serving engines support, for example, vLLM through PagedAttention or SGLang through RadixAttention designs.
With NVIDIA Dynamo, the KV Caching mechanism becomes way more interesting due to the Smart Router and Cache distribution across GPUs.
2. NVIDIA Dynamo Inference Framework
Just 2 days ago (March 17), at GTC, Jensen announced that the NVIDIA Inference team is open-sourcing Dynamo, an inference framework for accelerating and scaling AI reasoning models at the lowest cost with the highest efficiency.
With the current surge of Reasoning models such as DeepSeek R1, R1-Zero - the challenges LLM serving faced at scale grew more complex due to the dynamic and unconditional behavior that reasoning models have, as they generate a long sequence of “reasoning” tokens before providing an output, which does a hit on system’s performance.
For that use case, and many other challenges of LLMs at scale, Dynamo proposes an innovative approach that builds and takes inspiration from the existing inference engines.
Dynamo is built mainly in Rust (55%) for critical performance-sensitive modules, thanks to the memory safety, and concurrency of Rust. Go (28%) for the deployment module, including Operator, Helm, and API Server part, and Python (10%) for its flexibility and customization to bring it all up together.
Let’s see what Dynamo is composed of, how it works, and what problems it aims to solve.
Dynamo brings 4 key components, which we’ll describe in detail. These are:
(7) GPU Planner - a planning engine that dynamically adds and removes GPUs to adjust to fluctuating user demand, avoiding GPU over- or under-provisioning.
(2) Smart Router - an LLM-aware router that directs requests across large GPU fleets to minimize costly GPU recomputations of repeat or overlapping requests — freeing up GPUs to respond to new incoming requests.
(3) NVIDIA Inference Transfer Library (NIXL) - An inference-optimized library that supports state-of-the-art GPU-to-GPU communication and abstracts the complexity of data exchange across heterogeneous devices, accelerating data transfer.
(8) Memory Manager - an engine that intelligently offloads and reloads inference data to and from lower-cost memory and storage devices without impacting user experience.
All the components are robust, modular, and independently scalable.
Dynamo Disaggregation
The Disaggregated Serving module is inspired by the DistServe (2024) paper, which points to separating prefill and decode to different GPUs co-optimizing the resource allocation and parallelism strategy tailored to each phase. Separating prefill and decode increases efficiency because they have different memory and computation footprints.
The execution of a request follows these main steps:
The prefill engine computes the prefill phase and generates the KV Cache
Prefill engine transfers the KV cache to the decode engine
The decode engine computes the decode phase
In case the prefill is short (short prompt) or the decode engine has a high cache hit, the prefill can be done locally in the decode engine directly by piggybacking chunked prefill requests with ongoing decode requests.
Dynamo by design handles all these different scenarios, prefill locally or distributed remotely, as seen in the following diagram:
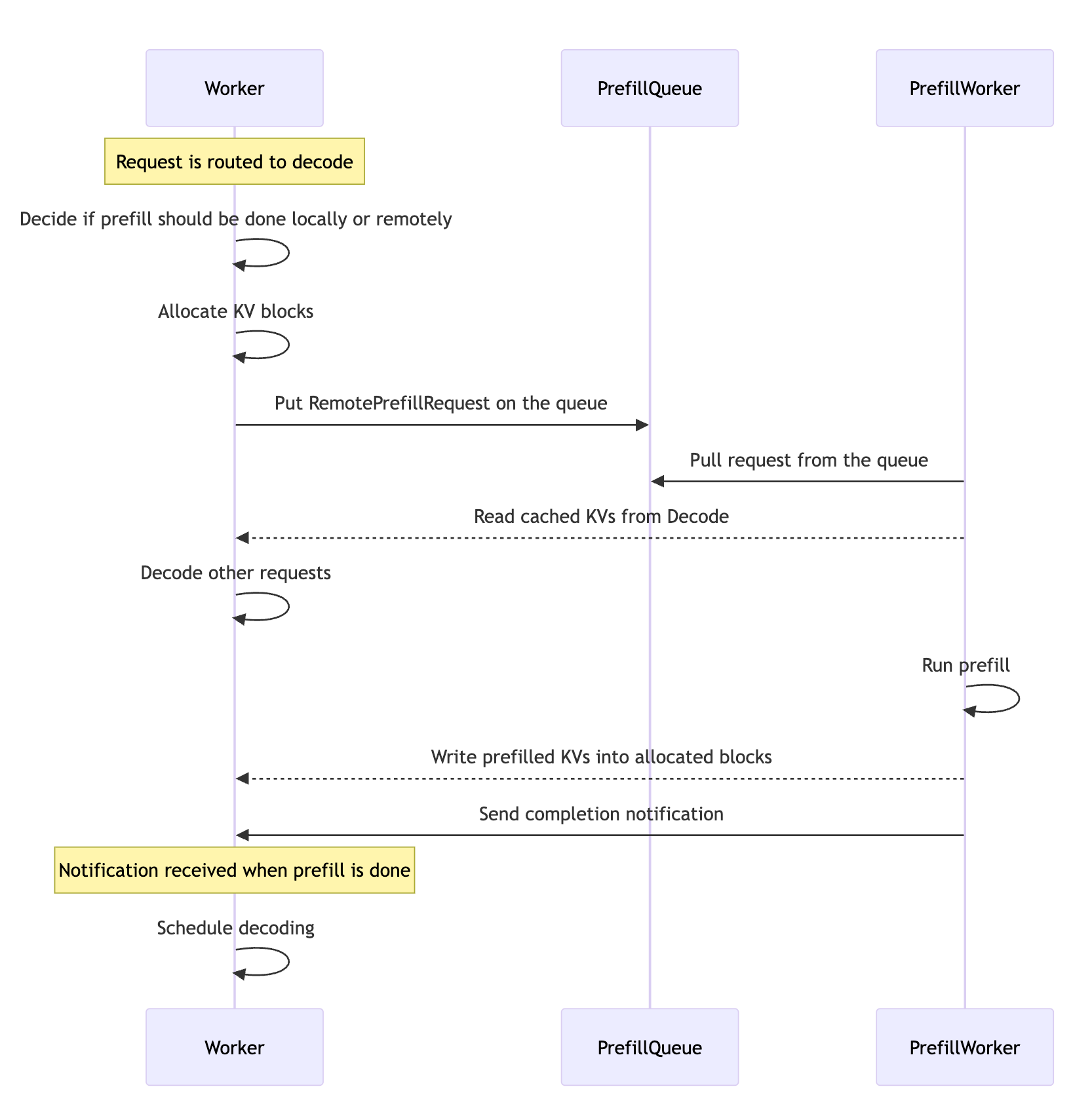
The Prefill Queue
If the prefill requests can’t be executed locally in the decode workers as specified above, they are executed in their dedicated iterations without any other requests to ensure optimal TTFT (Time to First Token) times.
To balance the load across multiple prefill engines, Dynamo adopts a global prefill queue where workers push remote prefill requests and prefill workers pull and complete the requests one by one. The global prefill queue is implemented based on the NATS stream to ensure high performance and availability.
NIXL and KV Cache Transfer
The LLM-aware request routing module can target the workers with the best KV match in the distributed KV Cache setup across multiple nodes, and execute the inference stages there.
After the KV blocks are allocated, the worker scheduler sends the remote prefill requests, which contain the memory descriptors for the allocated KV blocks, to the prefill worker scheduler via the prefill queue.
This allows the prefill worker to read and write from the remote KV blocks without explicit handling in the remote worker engine, thanks to the RDMA read-and-write NIXL operations.
If you’re curious how KV Cache, being composed of tensor states is shared through NIXL, the answer is that NIXL offers generic interfaces capable of supporting data transfers in the form of tensors, bytes, or objects, across multi-nodes.
Once the remote prefill is done, the worker scheduler simply adds the decode request to the worker in-flight. This allows workers to execute forward passes of ongoing decode/prefill requests while waiting for the remote prefill to finish.
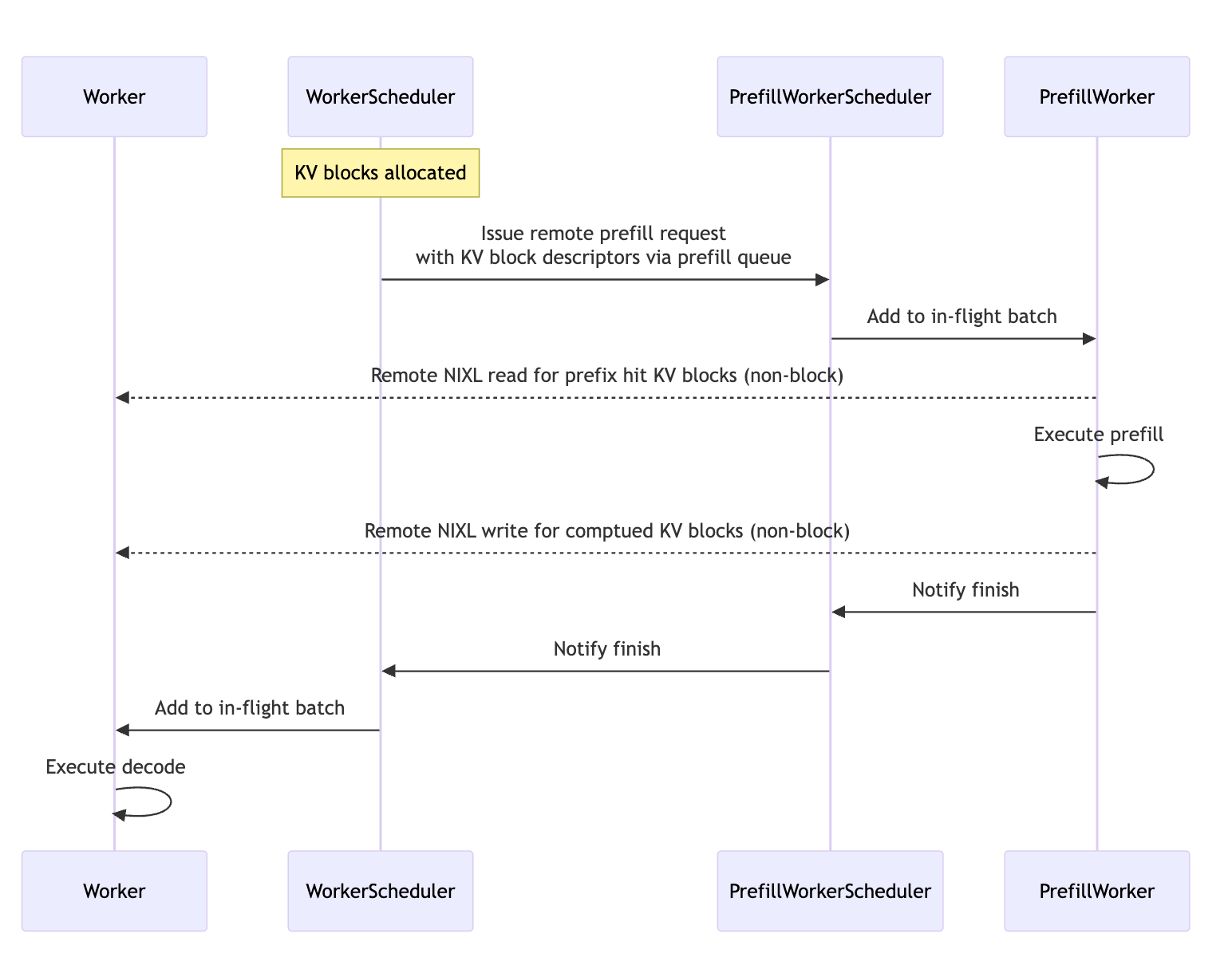
KV Cache and Load Balancing in Dynamo
In vLLM we had PagedAttention as a mechanism to reuse KV Cache. In SGlang, RadixAttention with the RadixTree + LRU eviction policy enhanced cache reuse.
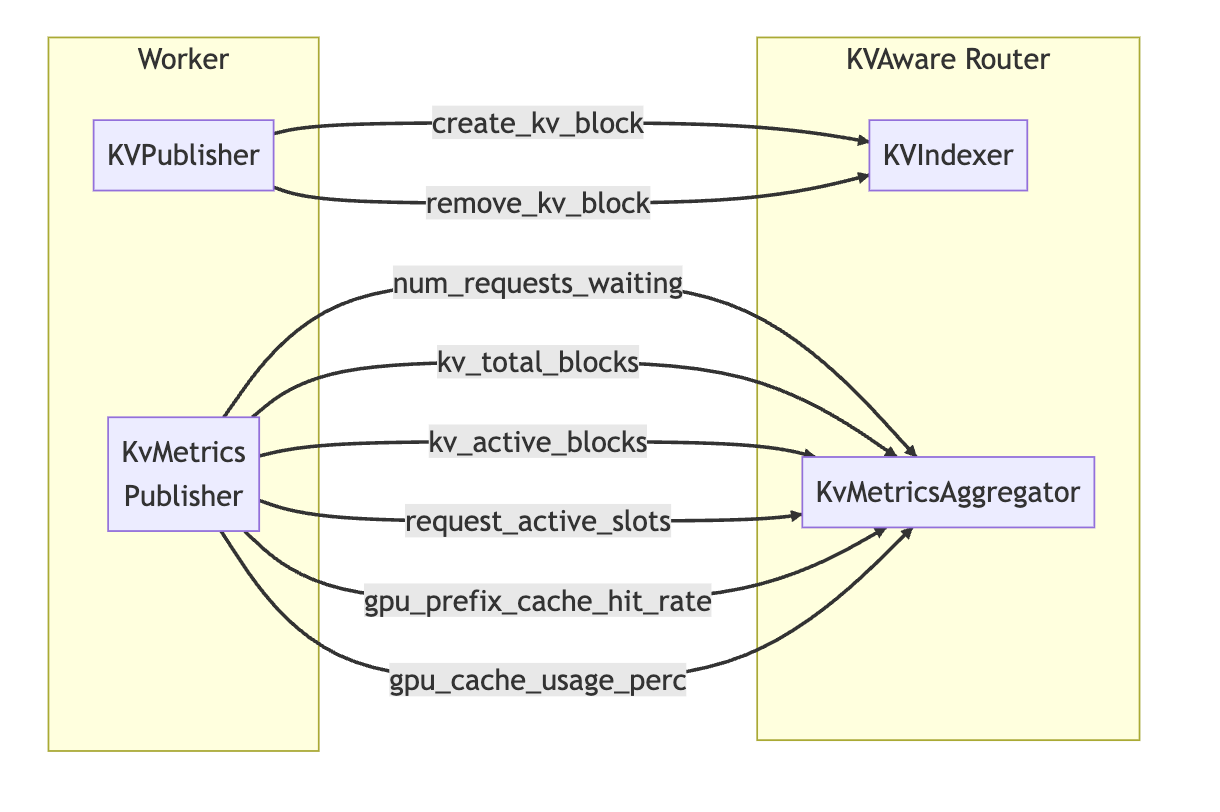
In Dynamo, a KVPublisher is introduced which emits KV Cache events that occur at each worker, and a KVIndexer which keeps track of these events globally.
Similarly to SGLang, the KV Cache eviction is based on a RadixTree approach.
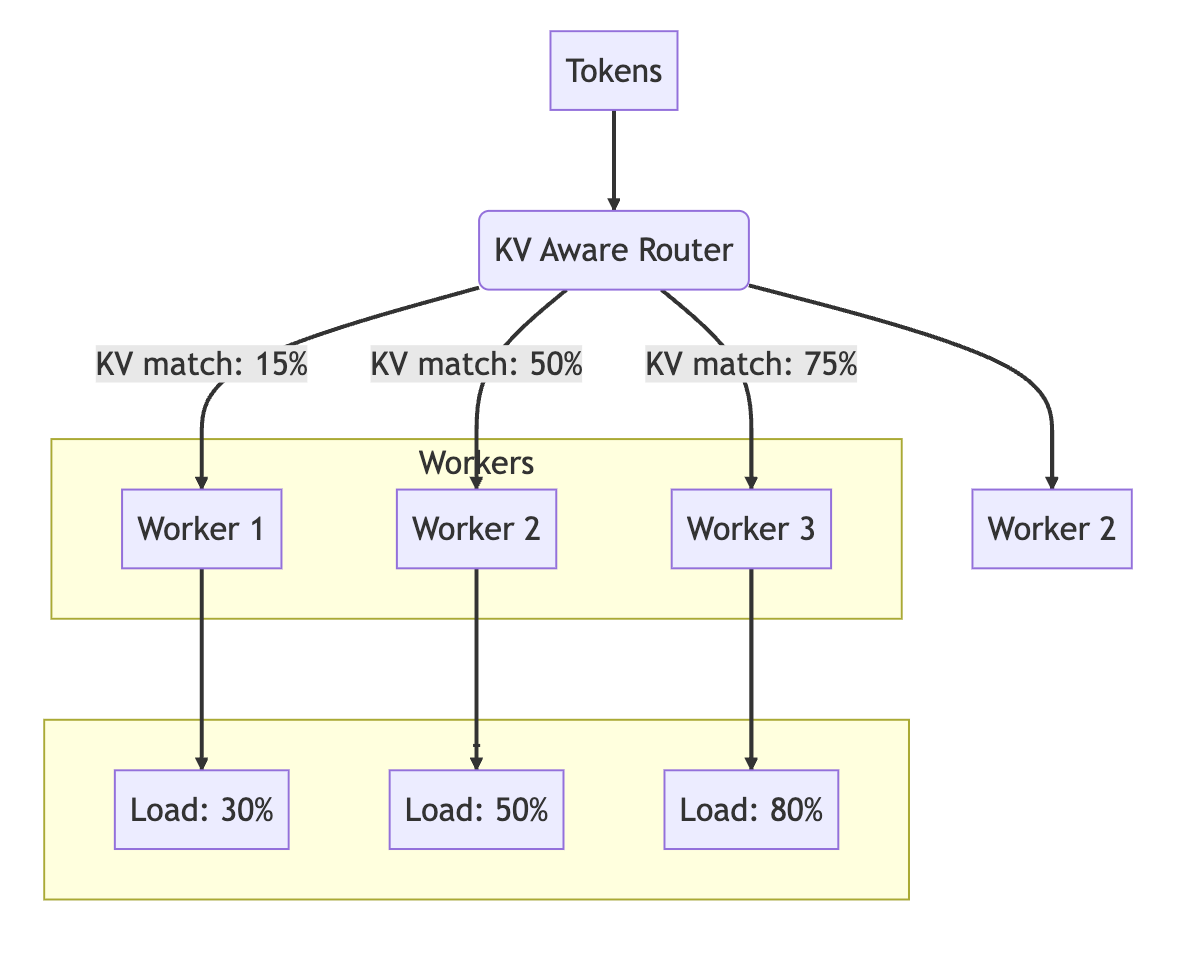
With the router having a global view over the KV Cache and Load, it can align and select a worker based on a cost function composed of Load + Match.
For example, in the following image, the cost is (KV match - Load). Worker 3 has the best KV Cache match, but it’s also at 80% load. Given these conditions, Worker 2 is selected as even if the KV match is lower than Worker 3’s, the load is at almost half.
GPU Planner
The GPU planner takes care of elastic GPU resources, maximizing GPU throughput within a cluster of nodes. Based on the metrics insights that Event Plane is gathering, Dynamo adjusts the cluster’s resources and can add, remove, or reallocate GPUs in response to fluctuating request volumes and types, or route specific requests to target GPUs, for example, “a very long reasoning request” routed to an H200 GPU node as it requires more VRAM to compute the prefill/decode phases.
Dynamo Events
In the documentation, the team stated they want to support KV Cache Routing and load balancing for many backends that have different implementations of KV Cache and record different metrics. With that purpose in mind, the KVPublisher can be plugged into any framework to publish KV Events and a KvMetricsPublisher can publish Metric Events.
For example, following this design, vLLM could publish and update the PagedAttention table of logical-physical memory blocks it uses to store the KV Cache through the KVPublisher.
Similarly, the same could be done for SGLang’s RadixAttention approach of storing KVCache into a RadixTree, by controlling the KVCache layout through KVPublisher events.
On the receiving side, the KVIndexer accepts events from KVPublisher and puts them into a global prefix tree and a KvMetricsAggregator which aggregates metric events by the worker.
Installing and serving LLMs with Dynamo
Done with the theory, let’s get practical and deploy a model using Dynamo Framework. Remember that Dynamo is an inference framework, and acts as the backbone for LLM serving engines, such as vLLM, SGLang, or TensorRT-LLM.
In this example, we’ll serve a HuggingFace model using the vLLM backend.
Installing Dynamo (Ubuntu 20.04 + x86_64 CPU)
apt-get update
DEBIAN_FRONTEND=noninteractive apt-get install -yq python3-dev python3-pip python3-venv libucx0
python3 -m venv venv
source venv/bin/activate
pip install ai-dynamo[all]
Download a model from hugging face
curl -L -o Llama-3.2-3B-Instruct-Q4_K_M.gguf "<https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q4_K_M.gguf?download=true>"
Serve model from local
# As a text CLI interface
dynamo run out=vllm Llama-3.2-3B-Instruct-Q4_K_M.gguf
# As a HTTP interface
dynamo run in=http out=vllm Llama-3.2-3B-Instruct-Q4_K_M.gguf
## Use the OpenAI API spec to send requests
curl <http://localhost:8080/v1/completions> \\
-H "Content-Type: application/json" \\
-d '{
"model": "Llama-3.2-3B-Instruct-Q4_K_M",
"messages":[{"role":"user", "content": "Tell me a story" }]
"max_completion_tokens": 7,
}'
If serving in a multi-node setup, use the following:
Make sure etcd and nats are installed on all nodes
On node 1 run
dynamo run in=http out=dyn://llama3B_pool
On the rest of the nodes, run
dynamo run in=dyn://llama3B_pool out=vllm ~/llm_models/Llama-3.2-3B-InstructThis video walkthrough from NVIDIA Developer’s YouTube Channel showcases how to run disaggregated serving using vLLM and Dynamo.
Conclusion
In this article, we’ve explained the core phases of the LLM inference process - prefill and decode and unpacked the new NVIDIA Dynamo Framework, announced at GTC2025, 2 days ago at the date of posting this article.
After reading this article you have a clear understanding of LLM limitations and challenges when deployed at scale, and how Dynamo tackles and solves these problems.
Thank you for reading, see you in the next one!
References:
ai-dynamo/dynamo: A Datacenter Scale Distributed Inference Serving Framework. (n.d.). GitHub. https://github.com/ai-dynamo/dynamo
DistServe: (arXiv:2401.09670, 2024) - https://arxiv.org/abs/2401.09670
NATS Protocol: (docs.nats.io) - https://docs.nats.io/reference/reference-protocols/nats-protocol
Dynamo Disaggregated Serving: (GitHub: ai-dynamo/dynamo, disagg_serving.md) - https://github.com/ai-dynamo/dynamo/blob/main/docs/disagg_serving.md
Dynamo KV Cache Manager: (GitHub: ai-dynamo/dynamo, kv_cache_manager.md) - https://github.com/ai-dynamo/dynamo/blob/main/docs/kv_cache_manager.md
NVIDIA NIXL: (GitHub: ai-dynamo/nixl, nixl.md) - https://github.com/ai-dynamo/nixl/blob/main/docs/nixl.md
If not specified otherwise, all diagrams are made by the author.
Thanks for the great article. Is aibrix similar to Dynamo?
Great article man!