
How does vLLM serve LLMs at scale?
The Online/Offline API modes, PagedAttention and distributed inference with Ray.

As Large Language Models (LLMs) continue to grow in size, a single GPU can no longer handle the entire model. Models that are suited for production deployments have a lot of parameters, and they don’t fit on a single GPU or a single node.
That requires GPU distribution, where multiple GPUs or Nodes load a “part” of the model, techniques varying from Tensor/Pipeline/Sequence parallelism.
In this article, we’ll cover vLLM, what it is and its core features for deploying LLMs at scale, how PagedAttention works in vLLM, what serving modes it offers, and how to scale it using Ray, to distribute the inference workloads.
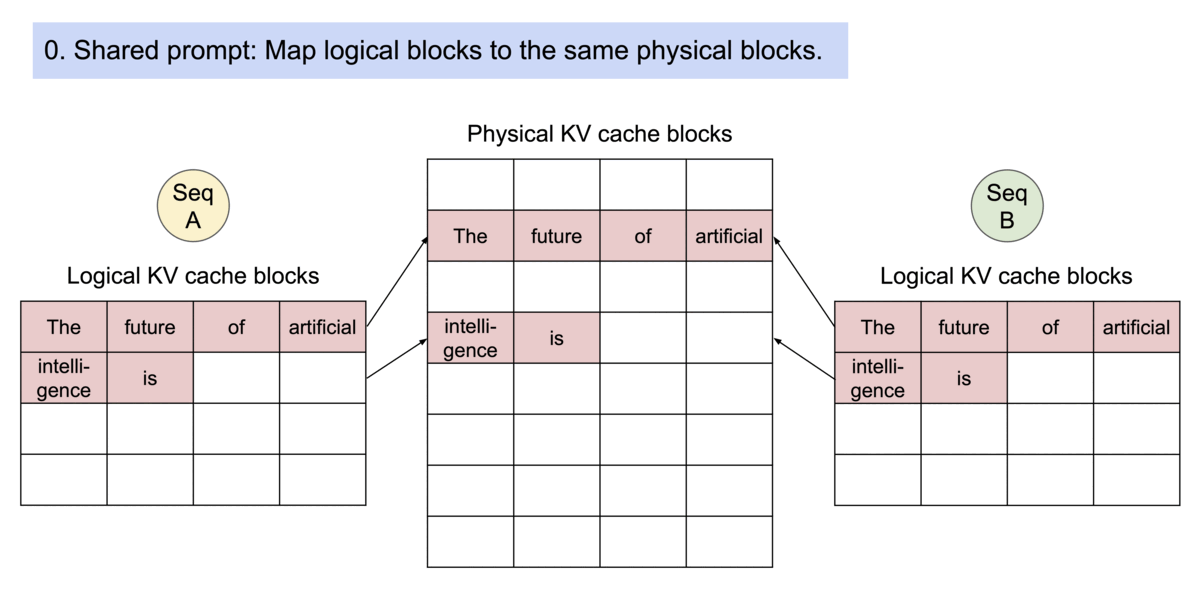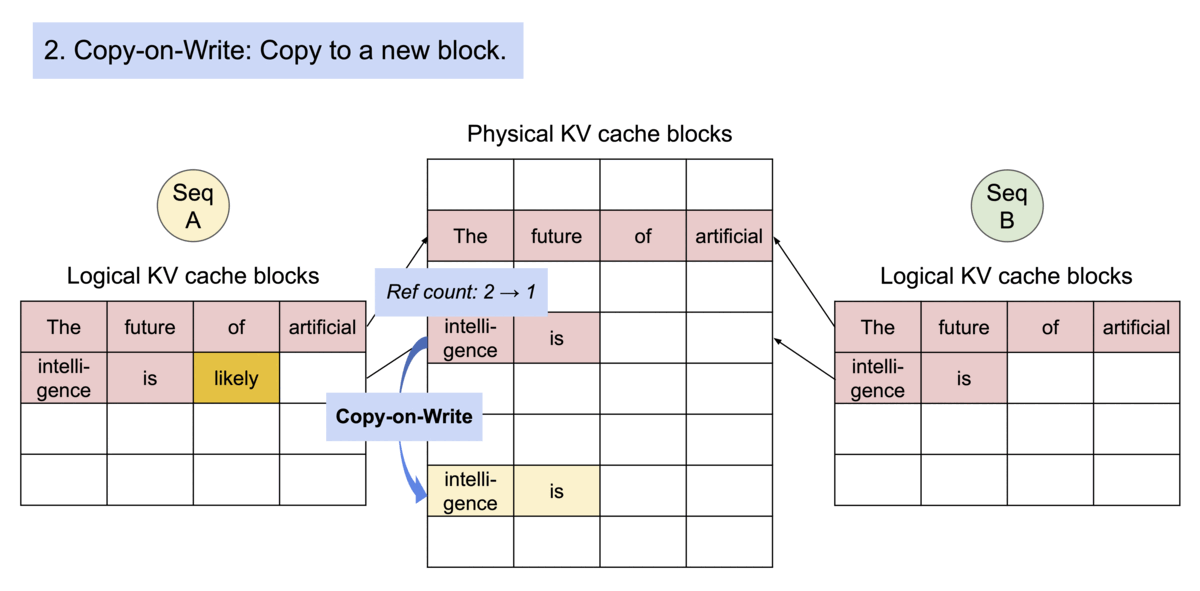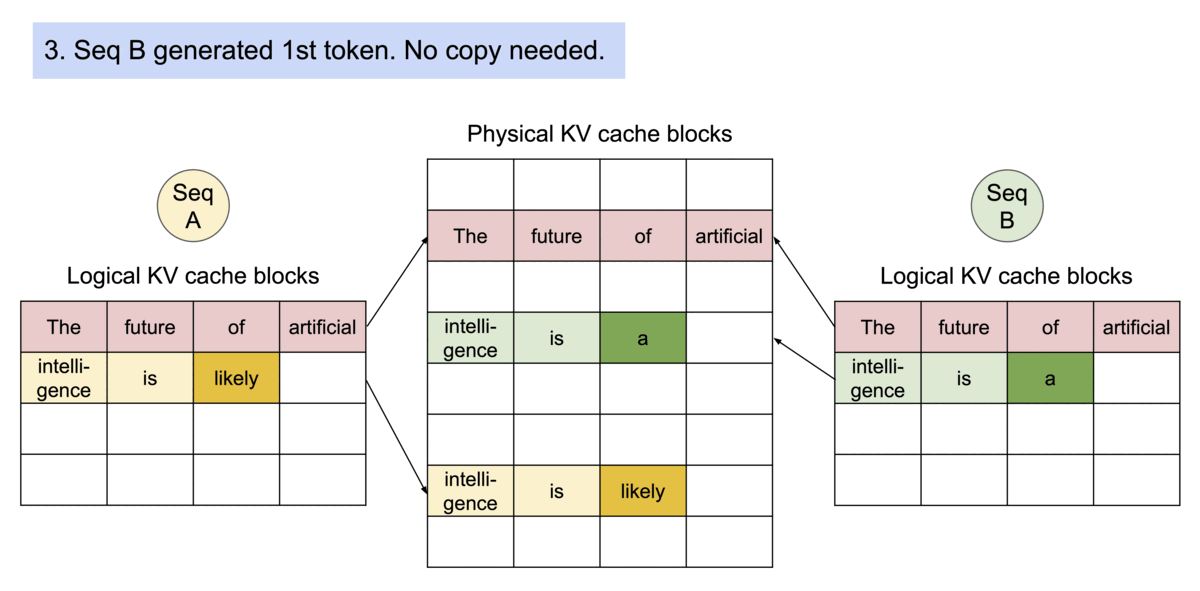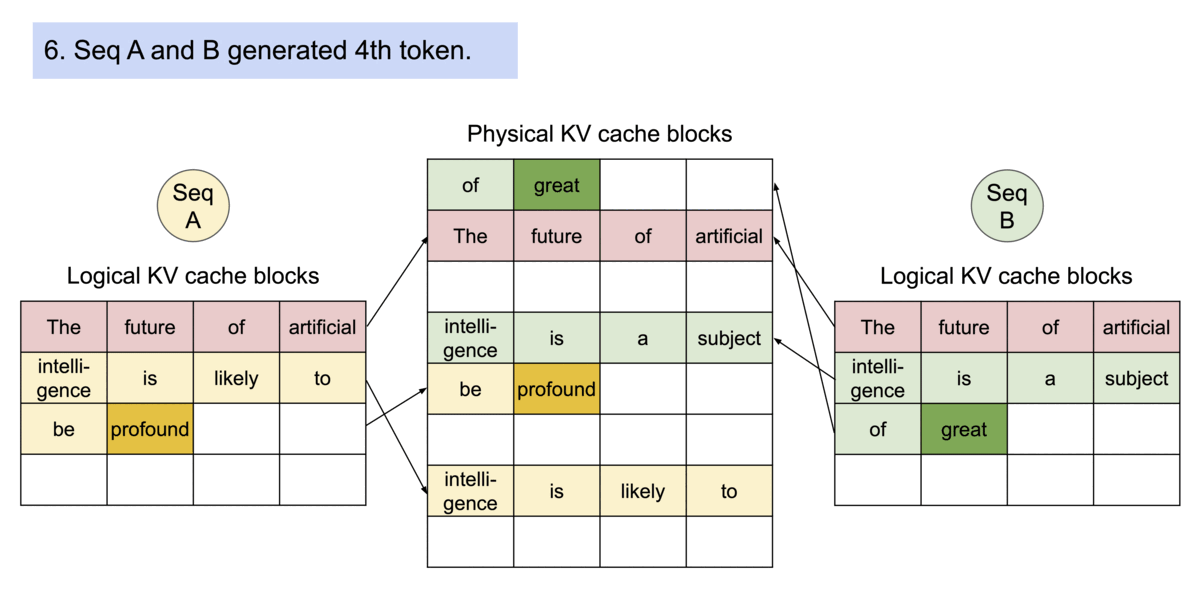
Table of Contents
What is vLLM and its place in the GenAI Landscape
OS Memory Layout and Paged Attention
Serving LLM models using vLLM in Python
Ray + vLLM and multi-node inference task distribution
Conclusion
References
1. What is vLLM and its place in the GenAI Landscape
vLLM is a high-throughput and memory-efficient inference engine for serving Large Language Models. It was originally developed in the Sky Computing Lab at UC Berkeley and it quickly evolved into a community-driven project. Being built mostly in Python (80+%) with a bit of CUDA and C++ (~13%) for Attention kernels and other optimizations, vLLM became popular amongst AI Engineers who need to deploy LLMs at scale.
Alongside other LLM serving engines, such as SGLang, and TensorRT-LLM, vLLM is one of the most popular engines for LLM inference out there, with over 40k ⭐ on their GitHub repository.
Amongst the popular model optimizations and improvements that other serving engines have, vLLM also provides a wide range of techniques that make LLMs run faster and more efficiently.
Common optimizations include:
Optimized CUDA kernels, FlashAttention, FlashInfer
Continuous batching for incoming requests
Quantizations GPTQ, AWQ
Speculative Decoding, Chunked Prefill, and more.
For a more detailed approach on these techniques, please see this article.
To save time, and not bore you with too many details, let’s provide a short description of some important ones in the list above:
Continuous batching
Compared to traditional batching, where each request got the same output length and we could batch them together, LLMs work differently because the output length is dynamic and traditional batching would underutilize the GPU. Continuous batching adds a new request to a batch as soon as a slot is freed.
Figure 2. How continuous batching (a.k.a Iteration Batching) works for LLM requests. Source: https://friendli.ai/blog/llm-iteration-batching Quantizations
Quantization refers to reducing precision (FP16, BF16, FP8, INT8, etc) and it works especially well for text generation since all we care about is choosing the set of most likely next tokens and don’t care about the exact values of the next token logit distribution. That’s why we can afford to do a computation in lower precision FP16 instead of FP32 and lose a bit of accuracy, making the inference faster.
Speculative Decoding
Simply refers to a 2-way inference approach, where a smaller and faster LLM predicts a set of tokens in the future, and the bigger slower LLM ranks and selects the most appropriate one, thus the concept of “speculation”.

The most notable feature of vLLM however, is PagedAttention, a mechanism for efficient management of attention key and value memory, which could improve LLM serving ~24x using 50% less GPU memory compared with traditional methods. Let’s unpack it in the next section.
2. OS Memory Layout and Paged Attention
The concept behind PagedAttention is inspired by the OS’s virtual memory design.
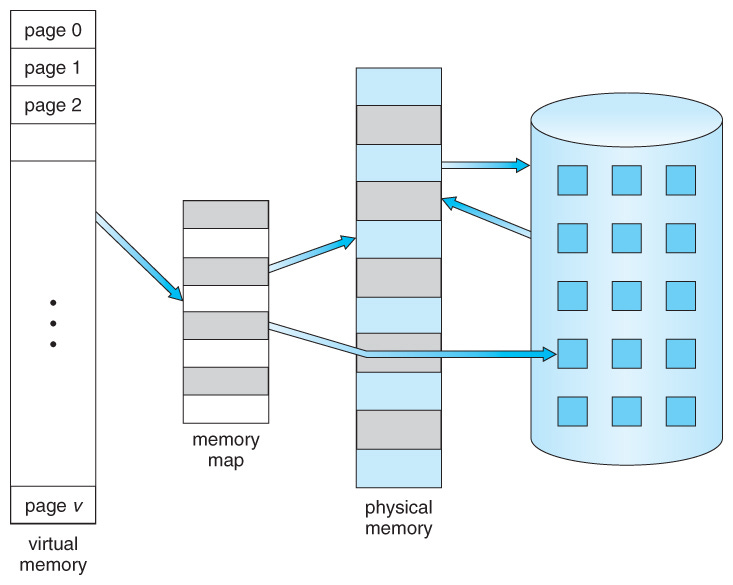
As the team behind vLLM stated, the performance of LLM serving is bottlenecked by memory. In the autoregressive decoding process (i.e. Decoder generation phase), all the input tokens to the LLM produce their attention key and value tensors, and these tensors are kept in GPU memory to generate the next tokens.
These cached key and value tensors are often referred to as KV cache, which is:
Large: Sometimes taking several GBs in size, depending on the model.
Dynamic: Its size depends on the sequence length, which is highly variable and unpredictable.
To mitigate that, vLLM introduced PagedAttention, which, unlike the traditional attention algorithms, allows storing continuous keys and values in non-contiguous memory space. Let’s unpack how PagedAttention works.
1. Partitioning
The KV cache is partitioned into fixed-size blocks or “pages”, with each block containing a subset of KV pairs from the original cache.
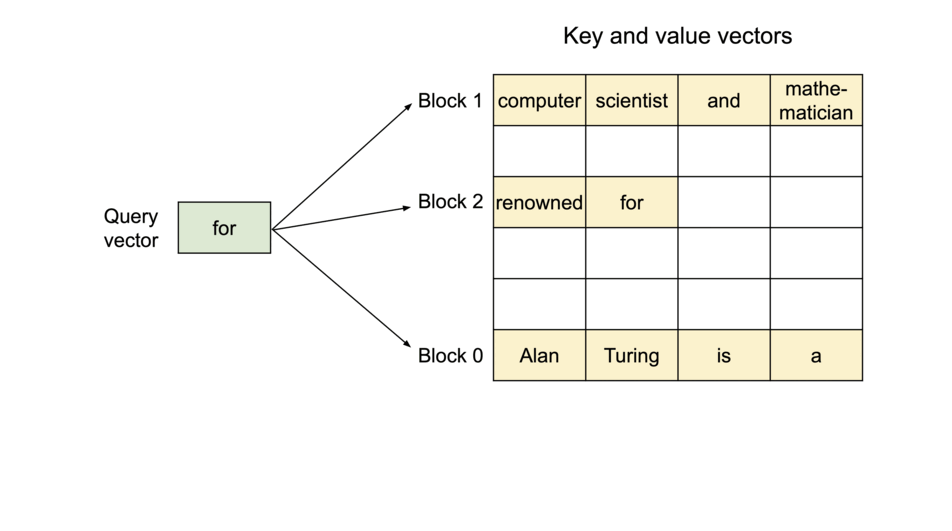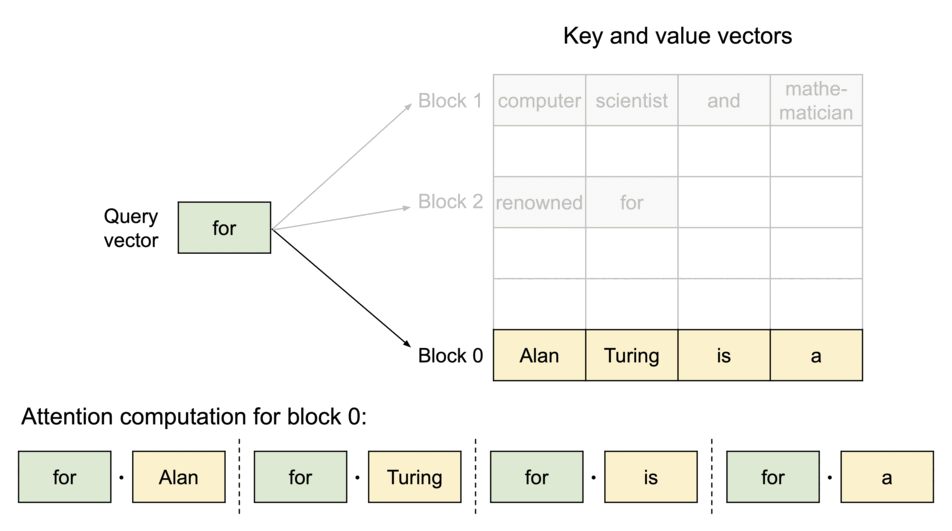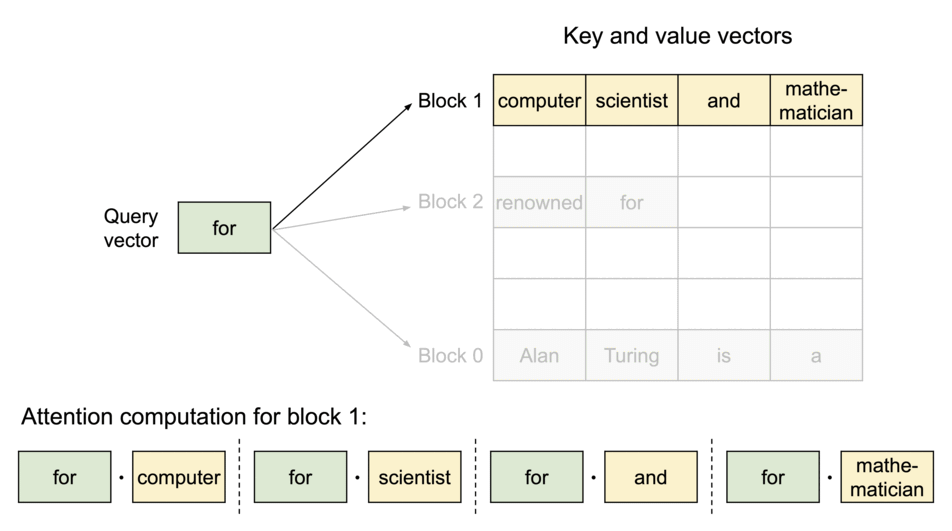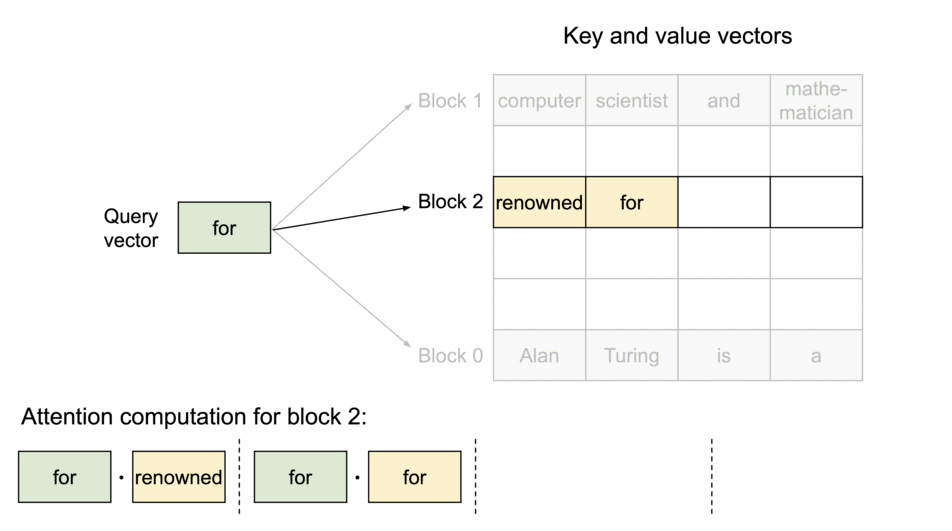
2. Lookup Table
A lookup table then maps the Query keys to specific pages where the corresponding KV values are stored.
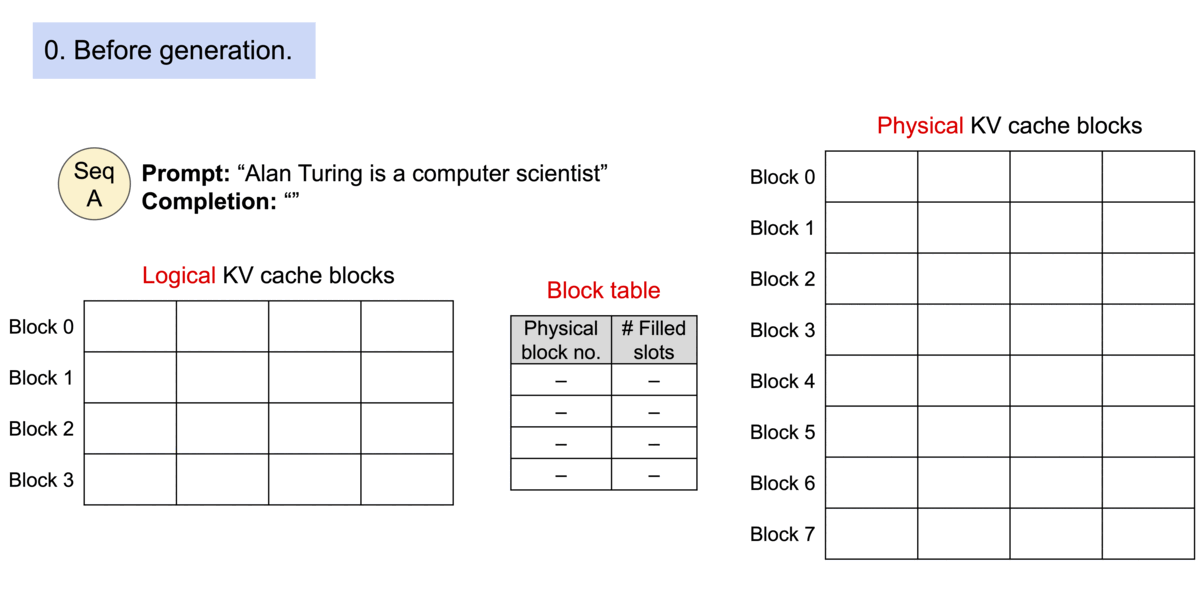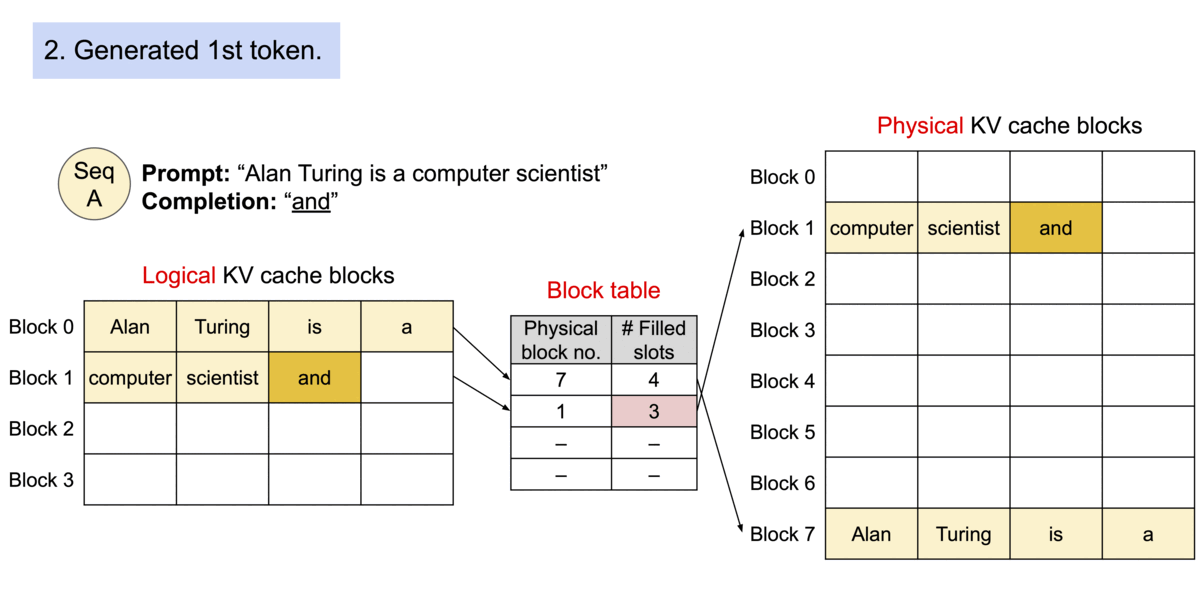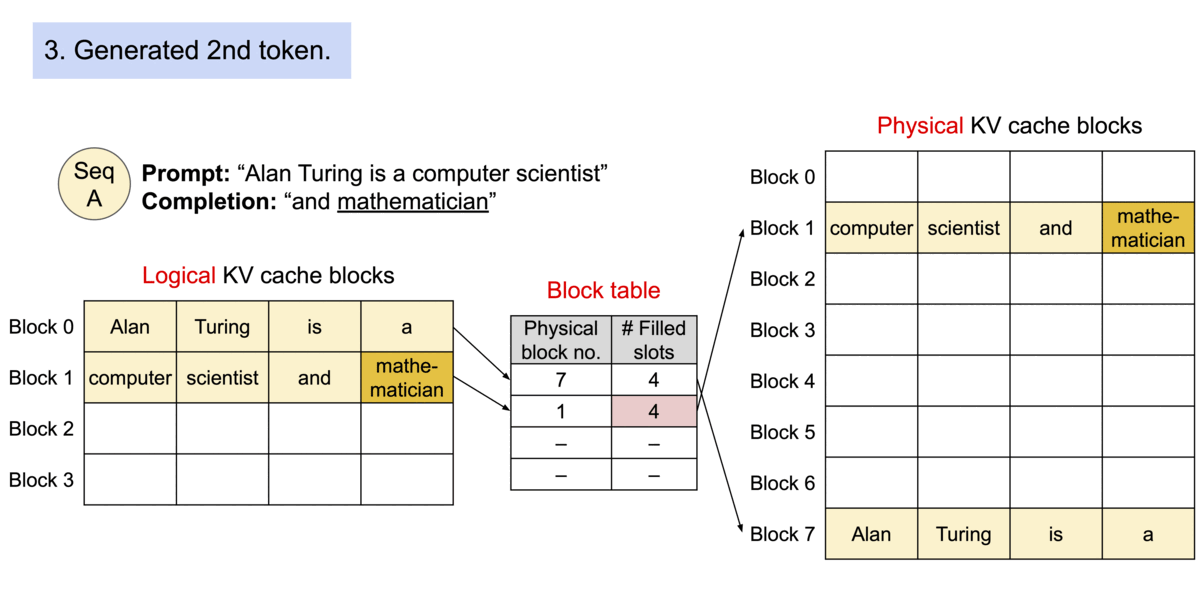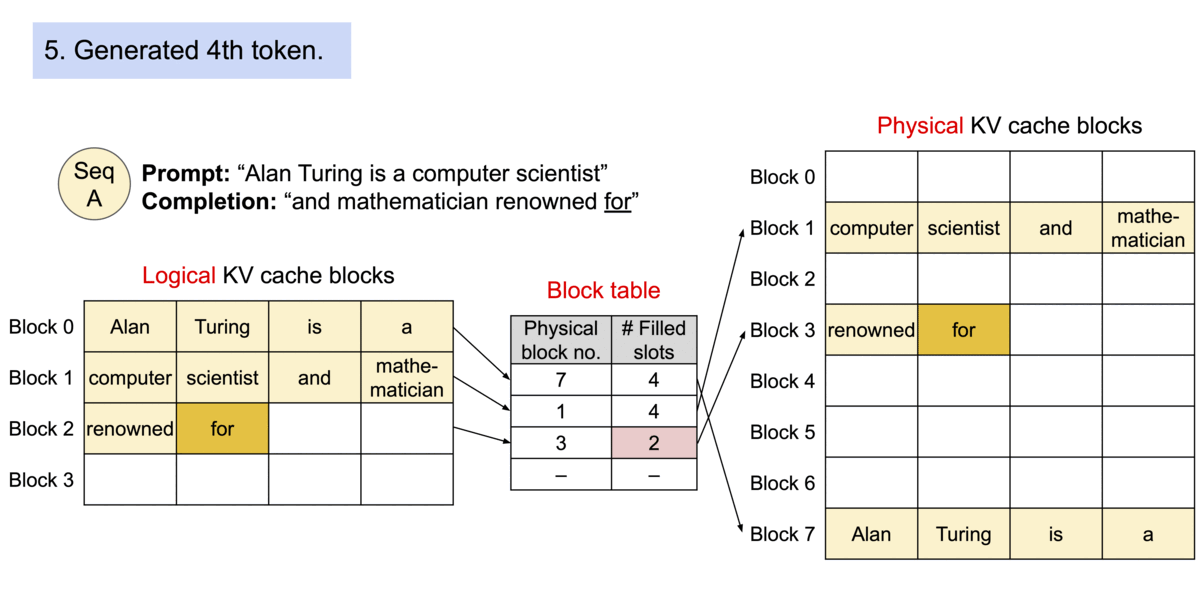
3. Memory sharing across requests
During inference, the model only loads the “pages” that are necessary for the current input sequence, reducing the memory footprint. Since the KV values are stored in non-contiguous blocks (i.e. they don’t take an entire continuous slot of GPU memory to be stored, but rather stored sparsely in different slots and accessed through a look-up table) the KV Cache can be efficiently shared across multiple requests.
This is important because, as stated in this paper Efficient Memory Management for LLM Serving with Paged Attention, around 65% of GPU memory is occupied by the model’s parameters, with another ~30% to store the dynamic states and tensors, which we refer as KV Cache, the size of which is also dynamic and unpredictable.
By decoupling the logical organization of data from physical storage, PagedAttention can be shared across multiple requests, making inference run faster. To make this even simpler, let’s see how an incoming inference request is solved within the vLLM inference engine.
3. Serving LLM models using vLLM in Python
vLLM operates in two modes: online and offline. Before explaining how Online/Offline works, let’s install vLLM using uv and Python 3.12:
uv venv myenv --python 3.12 --seed
source myenv/bin/activate
uv pip install vllmWith offline inference, it works similarly to a PyTorch module, where we instantiate the module, load the parameters (i.e. weights), prepare input samples, and apply the model.
When using it in Offline API mode, we’ll instantiate the LLM class, like this:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
With online inference, vLLM acts as a server that once started awaits requests from different clients and handles them concurrently. The online mode is the one most frequently used for LLM serving.
Underneath, vLLM instantiates the AsyncLLMEngine class and uses FastAPI to host its server. Let’s see what a request lifecycle looks like with vLLM online mode:
Request handling - the vLLM frontend is built in FastAPI, which will capture a request, unpack it, and enqueue it to the AsyncLLMEngine.
Prompt Processing - tokenizing the incoming prompt and allocating logical KV blocks to store K and V vectors for each token. Further, logical blocks are mapped to physical KV blocks in GPU memory.
Compute Attention - using cached blocks.
Generation Phase - pass the internal states to the LLM decoder which samples the next token of the sequence.
Update KV Cache - vLLM checks the block table, appending the Key and Value vectors to logical blocks to fill into the fixed size or create a new block if the size is exceeded. Then the block table is updated to reflect the new changes.
Generate Output - the newly generated token is returned from the vLLM engine into the vLLM frontend, and streamed back to the user.
Here, for the vLLM Online API mode, we have to do two things, starting the server and building the client.
vLLM Serve to start the Server
vllm serve meta-llama/Meta-Llama-3-8B --dtype auto --api-key <my_custom_token>Sending requests via Python client
from openai import OpenAI
openai_api_key = "<my_custom_token>"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
chat_completion = client.chat.completions.create(
messages=[{
"role": "system",
"content": "You are a helpful assistant."
}, {
"role": "user",
"content": "How are you?"
}],
model=model,
)
print("Chat completion results:")
print(chat_completion)Sending requests using curl
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "How are you?"}
],
"max_tokens": 20,
"temperature": 0.7
}'4. Ray + vLLM and multi-node inference task distribution
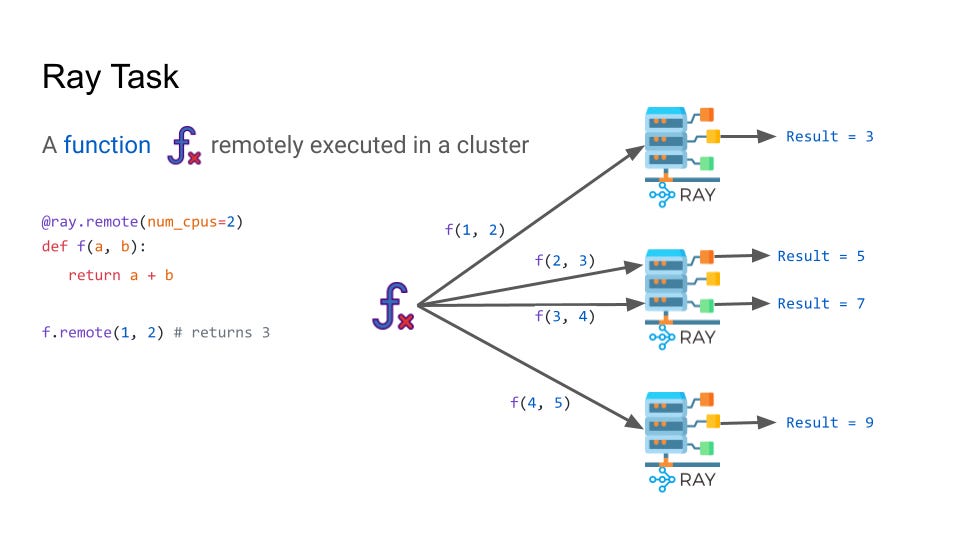
Ray is a Python-based framework designed to simplify the development and execution of distributed applications. Ray can scale Python workloads across a single machine using multiprocessing or across multi-nodes using the ray core Head and Worker concepts.

The Ray Head node is the central control point of the cluster. Its responsibilities include task scheduling and distribution across workers, autoscaling worker nodes based on workload and overall managing the cluster metadata.
The Ray Worker nodes execute tasks that were scheduled by the Ray Head and participate in the distributed storage and retrieval of Ray Objects. When we execute a remote task and it’s assigned to a worker, the reference to that task is called a Ray Object.
Now that we’ve covered Ray, let’s see how vLLM and Ray work together. Following the example from the vLLM repository `vllm/examples/offline_inference/distributed.py` we have:
from typing import Any
import numpy as np
import ray
from vllm import LLM, SamplingParams
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
tensor_parallel_size = 1
num_instances = 1
ds = ray.data.read_text("s3://anonymous@air-example-data/prompts.txt")
class LLMPredictor:
def __init__(self):
self.llm = LLM(model="meta-llama/Llama-2-7b-chat-hf",
tensor_parallel_size=tensor_parallel_size)
def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, list]:
outputs = self.llm.generate(batch["text"], sampling_params)
prompt: list[str] = []
generated_text: list[str] = []
for output in outputs:
prompt.append(output.prompt)
generated_text.append(' '.join([o.text for o in output.outputs]))
return {
"prompt": prompt,
"generated_text": generated_text,
}
resources_kwarg: dict[str, Any] = {"num_gpus": 1}
ds = ds.map_batches(
LLMPredictor,
concurrency=num_instances,
# Specify the batch size for inference.
batch_size=32,
**resources_kwarg,
)
outputs = ds.take(limit=10)
for output in outputs:
prompt = output["prompt"]
generated_text = output["generated_text"]
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}"Here, we define a batch LLMPredictor which uses the LLM class instance from vLLM Offline API, for which we override the __call__ method that’ll handle our requests.
Next, we load a dataset using ray.data and map batches executor across num_instances, where ray will automatically handle the distribution.
The vLLM team attached more examples on how to run vLLM with Ray, both in Offline API and Online API modes, find them here:
While not directly from the vLLM team, this tutorial from Alibaba Cloud showcases how to deploy vLLM Distributed Inference in Kubernetes.
Conclusion
In this article, we’ve explained the vLLM engine for serving LLMs at scale.
We covered the Online/Offline serving modes providing examples in Python on how to run both modes, and explained PagedAttention, covering the OS Virtual Memory design.
Further, we’ve touched on using vLLM and Ray to distribute inference across Ray Clusters, explaining the core concepts of Ray and how to run an offline inference workload parallelized using Ray.
After reading this article you have learned about the core concepts of vLLM, PagedAttention, and how to leverage Ray for distributed inference.
Thank you for reading, see you in the next one!
References:
PagedAttention: (Hopsworks.ai, 2024) - https://www.hopsworks.ai/dictionary/pagedattention
vLLM Optimization: (Medium: Bhukan, 2024) - https://medium.com/cj-express-tech-tildi/how-does-vllm-optimize-the-llm-serving-system-d3713009fb73
vLLM & PagedAttention: (Continuumlabs.ai, 2024) - https://training.continuumlabs.ai/inference/why-is-inference-important/paged-attention-and-vllm
vLLM GitHub: (GitHub: vllm-project) - https://github.com/vllm-project/vllm
vLLM Blog: (vllm.ai: Siyuan, 2023) - https://blog.vllm.ai/2023/06/20/vllm.html
Paged Attention paper: (ACM: 10.1145/3600006.3613165) - https://dl.acm.org/doi/pdf/10.1145/3600006.3613165
FlashInfer: (flashinfer.ai, 2024) - https://flashinfer.ai/2024/02/02/introduce-flashinfer.html
If not stated otherwise, all images used are made by the author.
Amazing article man. Appreciate all the effort you are putting into teaching us these concepts.