

The Open-Source Kubrick Course
Short article, complete overview and final steps of the course.

Welcome to Neural Bits. Each week, get one deep-dive article covering advanced, production-ready AI/ML development.
Subscribe to join 4,900+ AI/ML Engineers for production-ready insights and tips gained from close to a decade in the AI industry.
The final module on building Kubrick: The Multimodal Agent.
Kubrick is an open-source, comprehensive course that walks you through building AI Agents that can process Videos, Audio, Images, and Text. You upload a video and can start chatting with it.
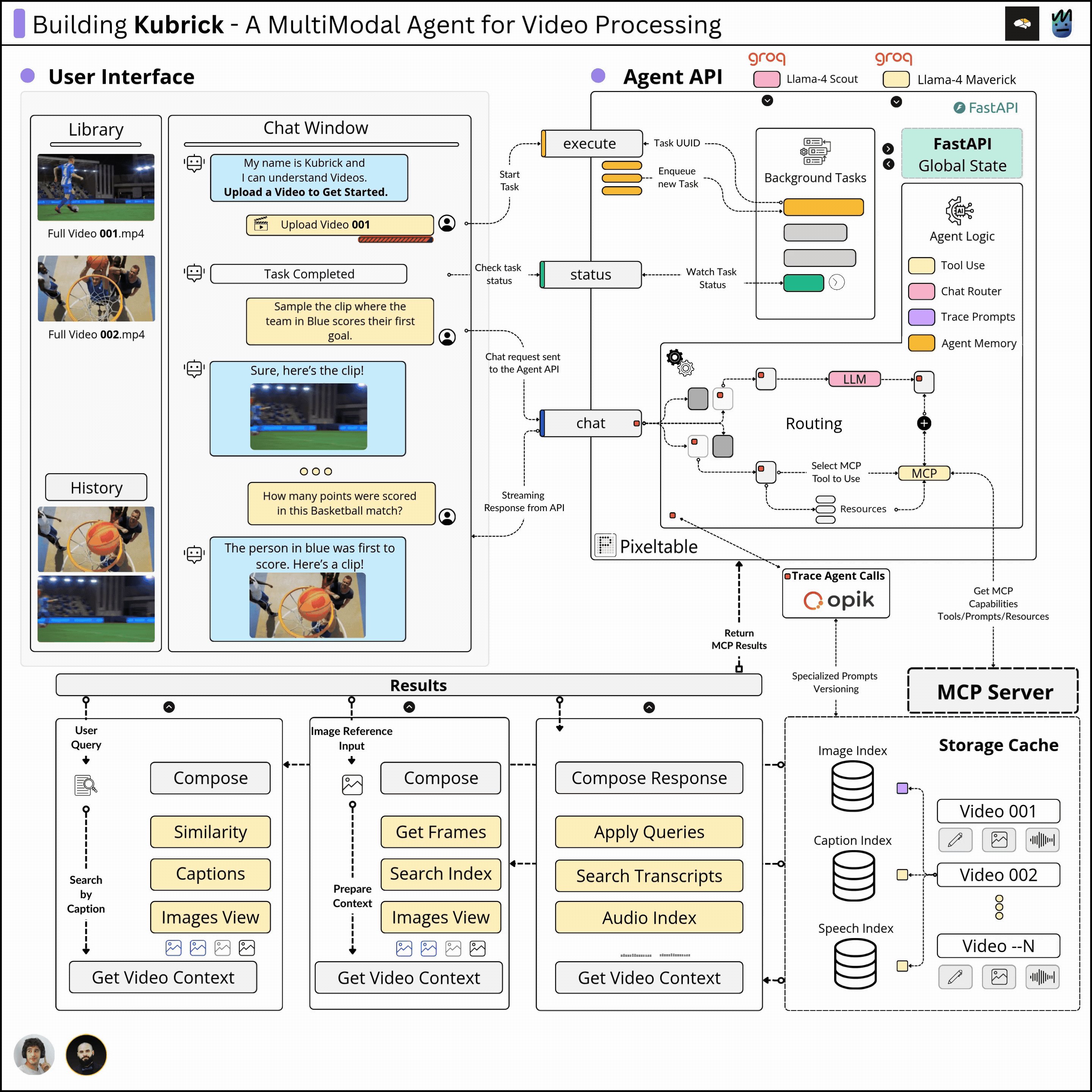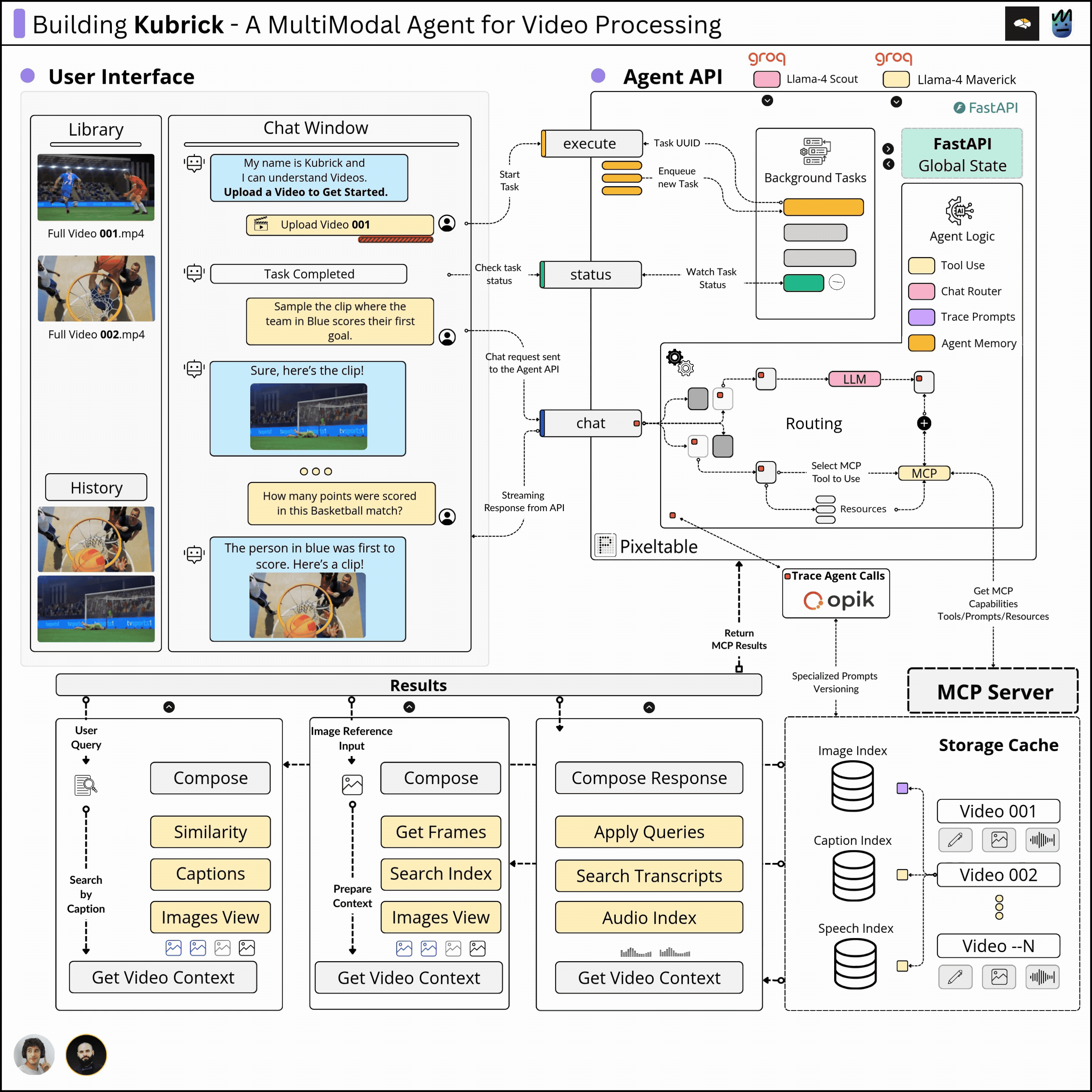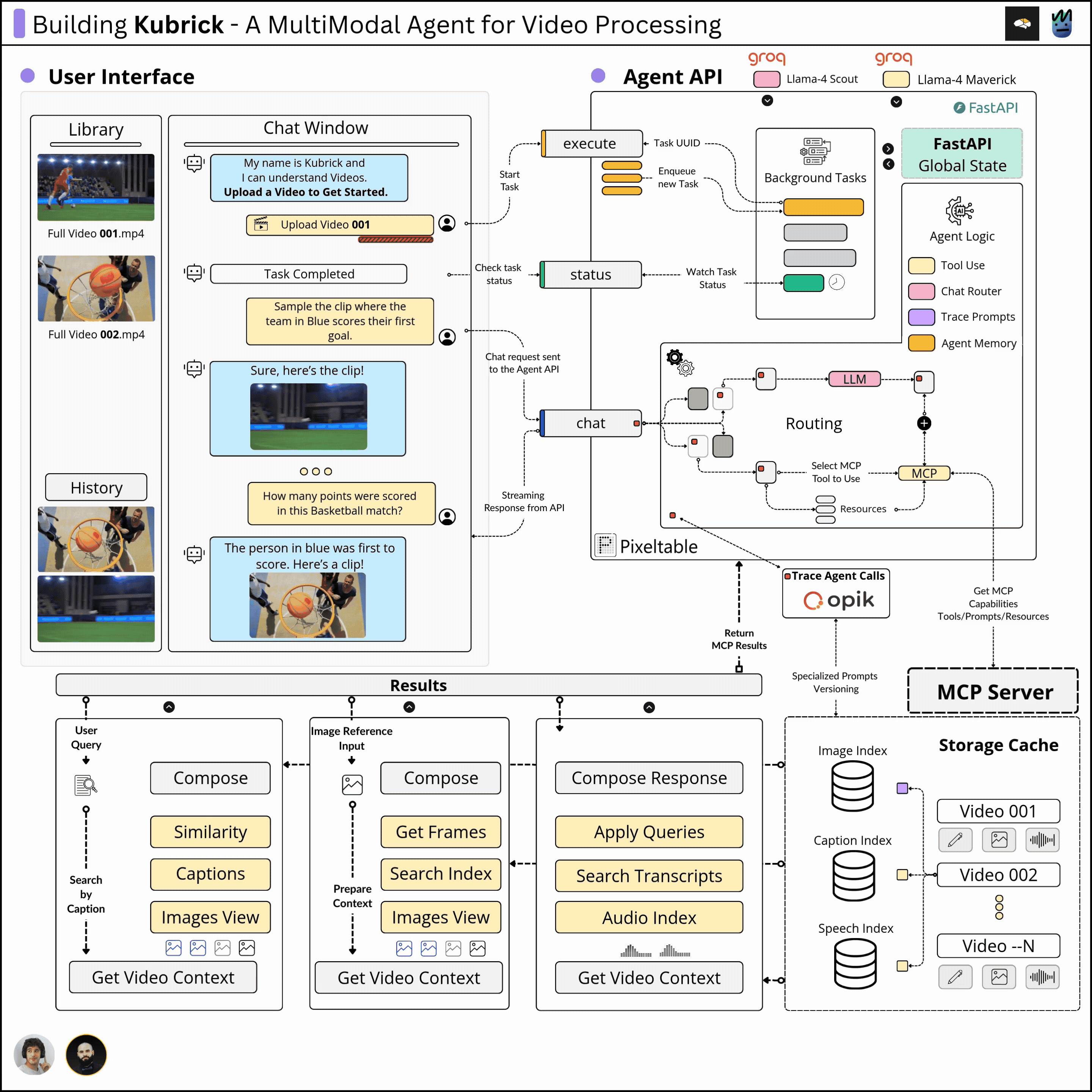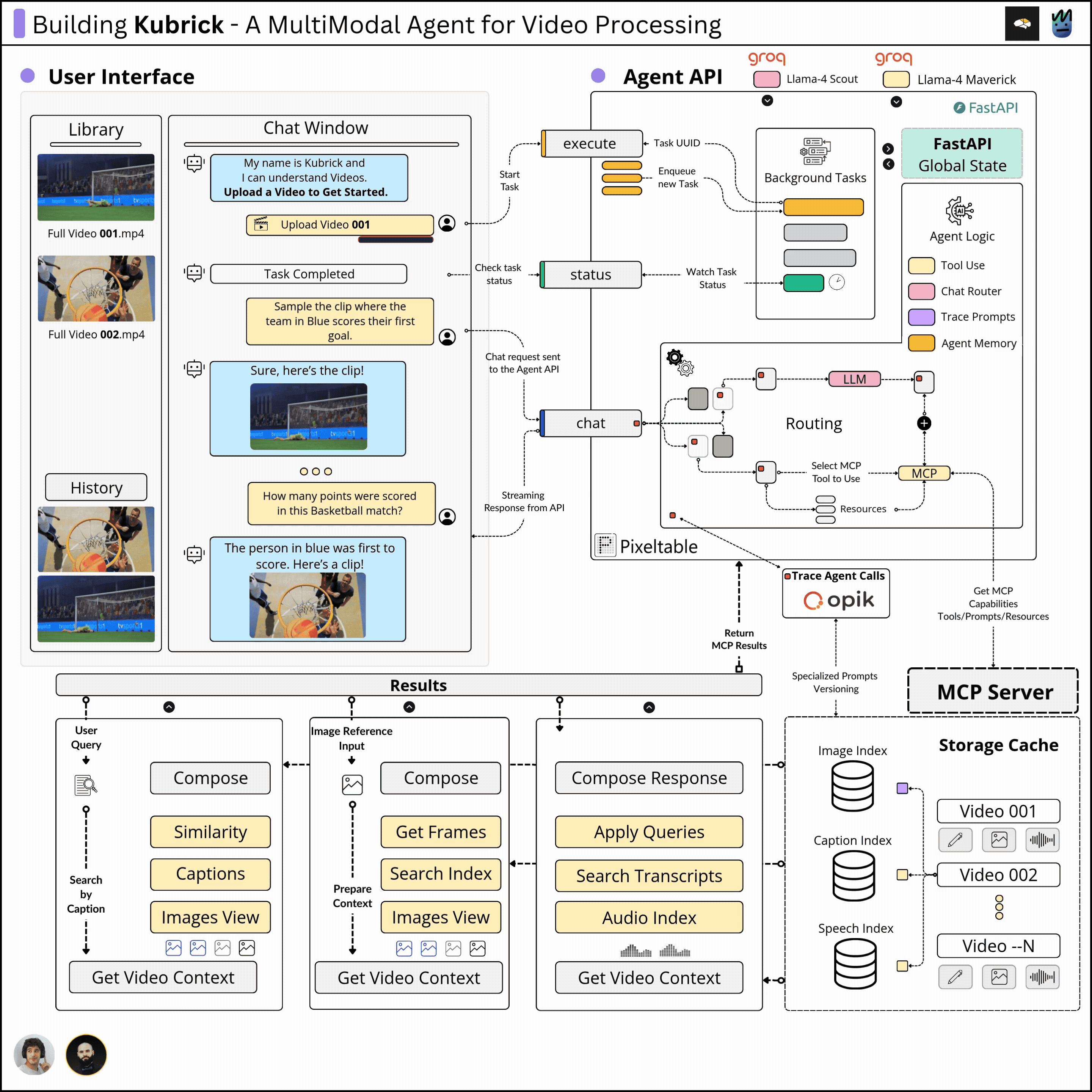
This course is structured in 6 modules, where you will learn how to:
Build Multimodal Data Pipelines, MCP Servers, and Video-RAG.
Build Tool Calling Agents from scratch, in Python.
Design an AI System, with LLMs, VLMs, RAG, and LLMOps.
Best practices in Python, FastAPI, and ML System Design.
📌 Here’s what Kubrick can do:
This course is done in collaboration with Miguel Otero Pedrido! 🙌
Course Modules
✅ Module 0: Introducing Kubrick Course: Multimodal AI Agent
✅ Module 1: Cracking the Code of Multimodal AI Pipelines
✅ Module 2: Advanced MCP Servers for Your Agents
✅ Module 3: Tool Calling Agents from Scratch
✅ Module 4: Building a FullStack (BE/FE) Agent ↔ UI Application
📌 Module 5: Kubrick Course - Final Round-up
Completing this course, you'll learn how to build an Agentic System that works with multimodal data. You'll gain hands-on experience in designing production-ready APIs (FastAPI) to host your agents, build MCP Servers and Tool Calling Agents, Multimodal agent RAG systems, and more.
This will allow us to build a Multimodal Agentic RAG and chat with Videos.
Find the complete roadmap for this free course: Kubrick Code Repository
Kubrick Final Round-up
In this article, we’re going to group every resource and create a clear roadmap for each course module, going through what we’ve built, design decisions, how we’ve implemented each component, and integrating them into the complete project.

Table of Contents:
Initial Design Decisions
Building Multimodal Pipelines on Videos
Building the MCP Server
Implementing the Agent from Scratch
Building the Agent API and the React UI
Conclusion
Initial Decisions
When we started planning the outline of this project, we iterated over multiple components and ideas and ended up with a clear direction in mind: Make it multimodal such that we don’t process only Text, but expand the capabilities to Audio, Images, and Videos - all at once.
Imagine you have a movie scene you want to “talk to” or you want to view a specific dialogue, event, or be able to “talk” and ask questions about that particular scene.
We know that LLMs “hallucinate” and occasionally “make things up,” and you don’t want them to do that over key properties that construct the final response.
For that, we ended up with a 3-layer split:
The MCP Server - to handle complex functionality that the agent could call.
The Tool Use and Router Agent - to route and interpret the user’s request.
The API and Frontend UI - the chat interface, API, and its connections.
Agent API
In our system, the Agent is implemented from scratch, in pure Python, using a provided LLM from Groq. Each workflow step of the Agent, from monitoring, tracing with Opik, and Short Term Memory using Pixeltable, is implemented without any framework.
The Agent sits behind an API that processes user requests. Depending on the intent extracted from the user prompt, which could range from extracting a specific clip, explaining a scene, filtering by an image, or answering a question, the Agent will decide whether to use any capabilities it has been given access to fulfill the request.
MCP Server
Once a video is uploaded, on the MCP server side, we execute a tool that constructs a table-based schema using Pixeltable, which extracts the audio clips, image frames, computes embeddings, generates transcripts, and image captions.
This tool's execution results in creating multimodal embedding indexes, which will be queried by the Agent to extract short clips or answer user queries related to the uploaded video.
Further, the MCP server also implements tools for various querying patterns, either by audio, using an image, using only text, or just asking the Agent any question about the video.
React UI
The UI is composed of a chat window from which the user can interact with the Agent, and a video library where the user can see previously processed videos.
One can further select any video from the uploaded ones and start chat sessions. As the processed metadata is persisted using Pixeltalbe, the wait time from switching between videos is instant.
Building Multimodal Pipelines on Videos

Here we dive into the core components of the multimodal processing pipeline, covering video, images, text, and audio data.
We start with a brief look at the progression of Multimodal AI to understand how we arrived at today's stage of Generative AI models that can process image, text, and audio - all at the same time, in a shared representational space.
Also in this module, we cover Vision Language Models (VLMs), which are used to generate Image Captions, as well as Speech To Text (STT), such as OpenAI Whisper, used to process audio segments and generate text transcriptions.

Find a summary of this Module One on Miguel’s Substack.

Building the MCP Server
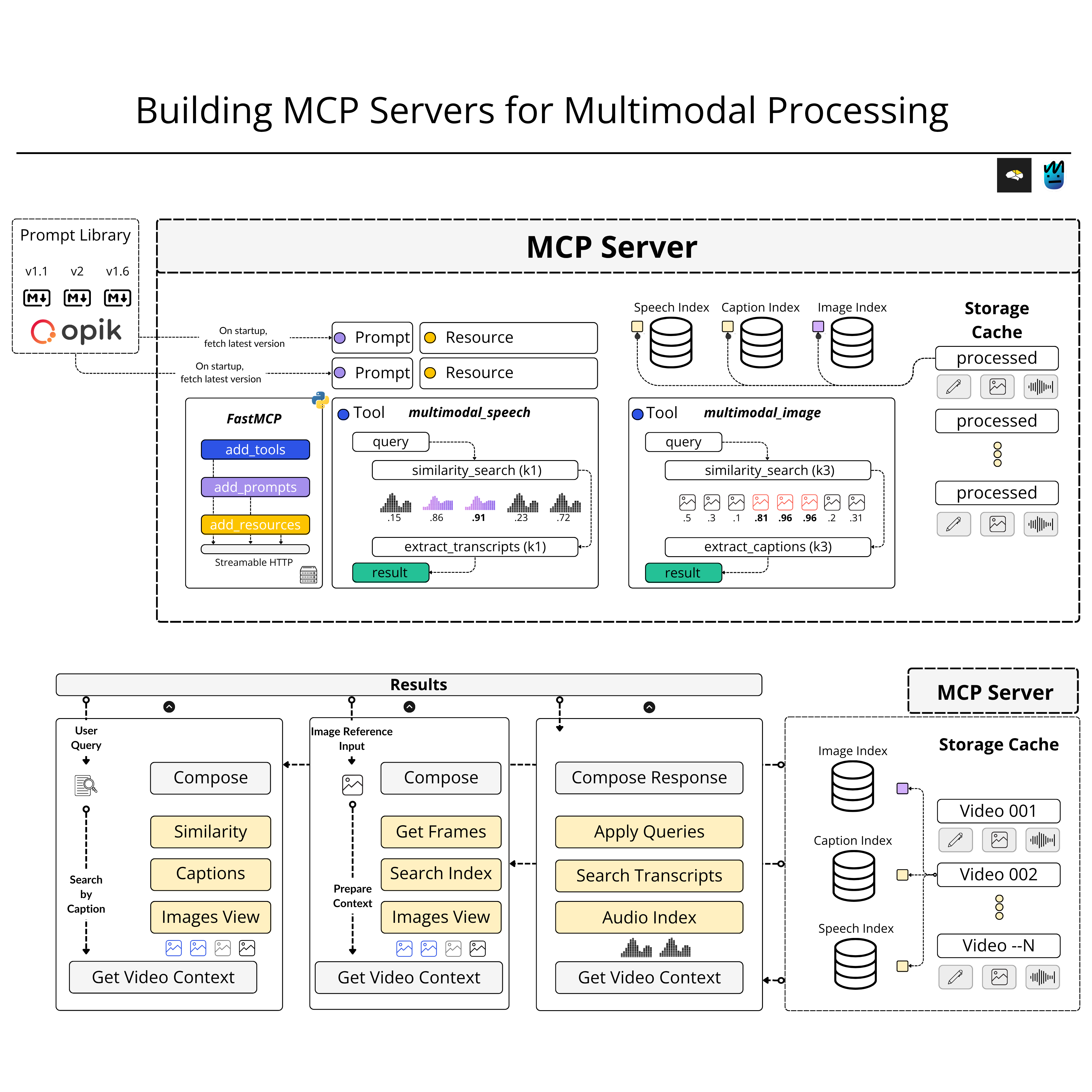
Here, we implement the functionality to sample data from our multimodal index and build on that behind the MCP protocol, which will allow our Agent to connect to our MCP server and selectively use the capabilities we expose.
Here we do a deep dive into MCP, covering the underlying structure, such as the Transport and Messaging Protocols, and provide details on how to build efficient MCP Servers.
Finally, we go through each tool implementation that we host on our MCP Server, and showcase how we can run and debug servers with Anthropic’s MCP Inspector UI utility.

Find a summary of this Module on Miguel’s Substack: The Neural Maze
Implementing the Agent from Scratch
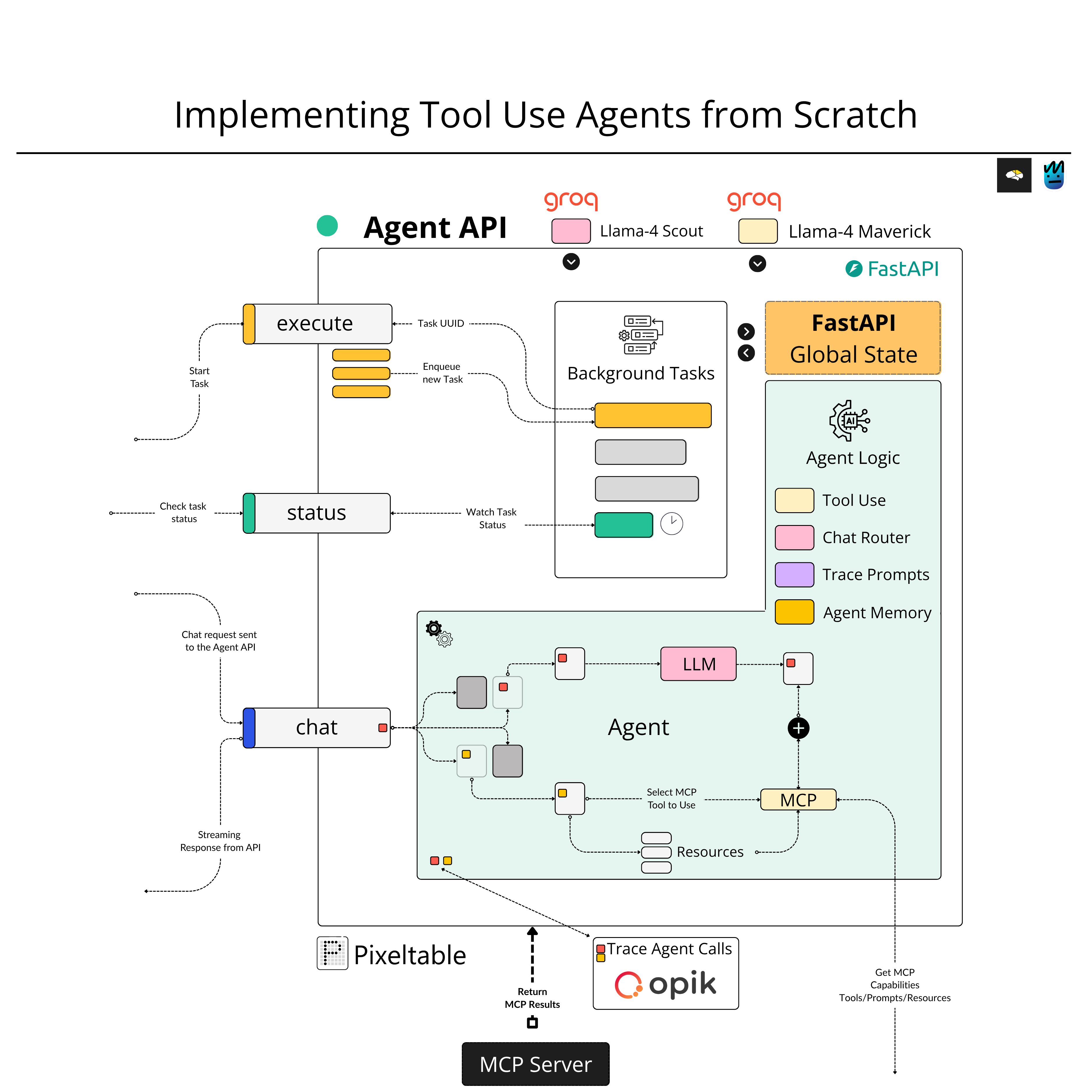
Here, we’ll implement the Agent from scratch, including Tool Use and Routing patterns, as well as the MCP Client and Agent memory using Pixeltable.
We’ll go through the popular Agentic Patterns: Routing, Tool Use, Reflection, and Multi-Agent, go over the BaseAgent Abstract Base Class definition, and unpack the GroqAgent class implementation.
We’ll cover the Opik Integration, to monitor and track structured conversation traces, and prompts which we’ll use for further Prompt Engineering, and explain how the Agent will be able to select the appropriate tool for the current user’s query.

Find a summary of this Module on Miguel’s Substack: The Neural Maze
Building the Agent API and the React UI
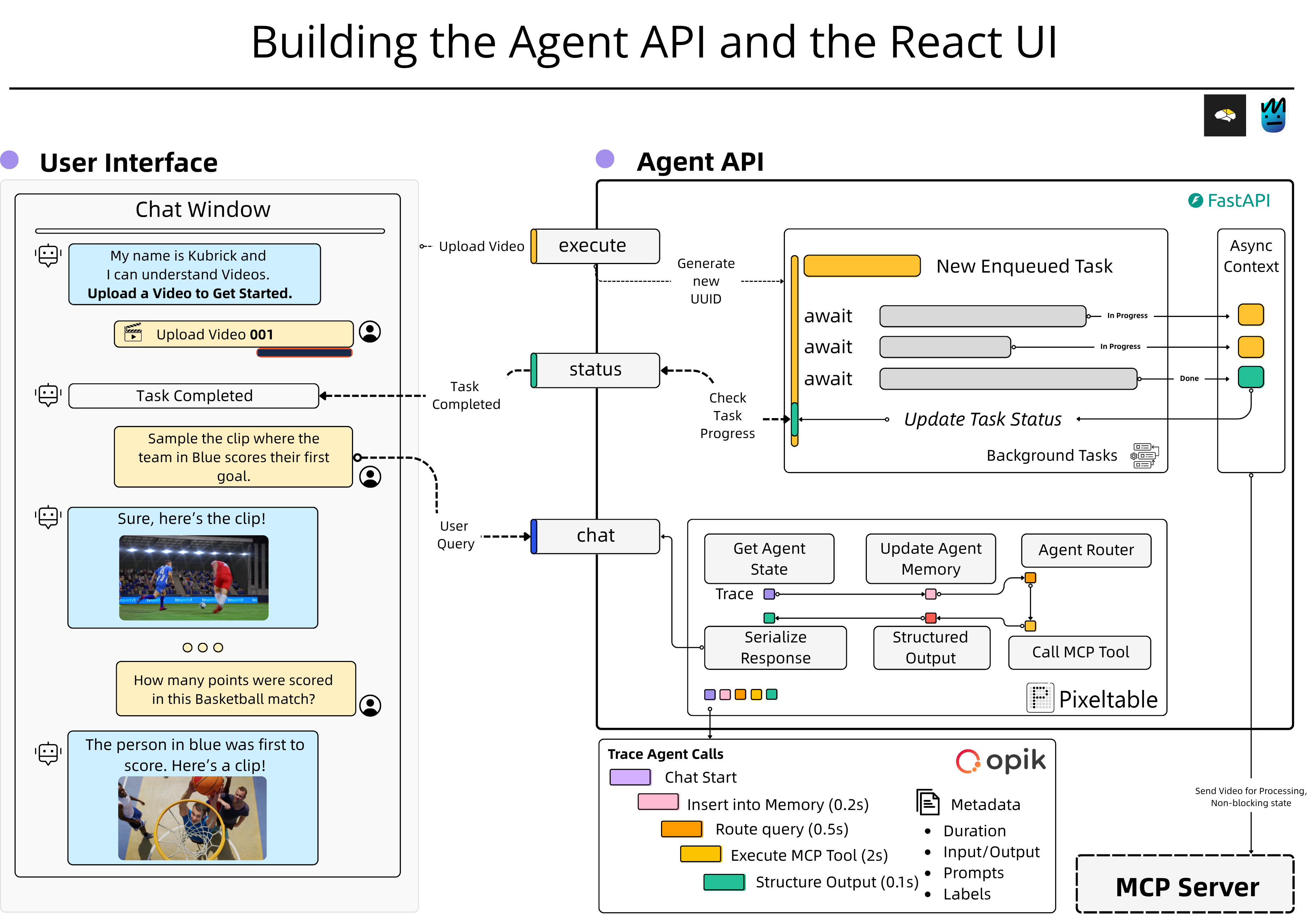
Once we have the Multimodal pipeline structure, the MCP server that implements tools to sample and use the multimodal embedding indexes, and the Agent Implementation, we build the API and the communication endpoints with the frontend chat UI.
On the Agent API side, we go through using FastAPI state management and lifecycle, Pydantic Models, and Background tasks to queue processing requests and enable a seamless user experience.
We unpack the UI implementation in React, Functional Components, and how to update state using React hooks. We define the Frontend-Backend endpoints and requests, and extensively cover how we added Opik to monitor the end-to-end Agent request lifecycle.

Find a summary of this Module on Miguel’s Substack: The Neural Maze
Conclusion
Thank you for building along and getting to the end of this free course.
If you’ve enjoyed and find the course interesting, help us with a ⭐ on the repo!
Over the five modules of the Kubrick: The Multimodal Agent course, you’ve gone beyond theory.
You started with the fundamentals of multimodal AI, learning how to process text, audio, images, and video through Pixeltable. You’ve learned about multimodal data and how current models such as VLMs or STT understand diverse data types.
Then, you built a complex MCP Server in Python using the FastMCP library to process detailed videos to enable Agents to use external tools via a standardized protocol.
From there, you implemented an Agent that can route user queries and construct MCP tool calls, from scratch in Python.
Next, you turned your Agent into a real product by building a full-stack application with an API built with FastAPI in Python, and a React frontend for the chat interface to interact with the Agent.
You’ve learned how to correctly manage long-running tasks in the Background, not blocking the main thread, and how to connect Frontend and Backend applications using REST.
Finally, you integrated Opik for observability across the Agent communication workflow. You traced conversations, versioned prompts, and instrumented your Agent for real-world use.
By now, you haven’t just studied multimodal AI, you’ve engineered an end-to-end, full-stack, multimodal agent system.
You now understand the architecture, tools, communication, and observability required to build AI systems that are robust, reliable, and production-ready — the exact skills companies are hiring for as AI moves from labs into the real world.
Keep learning. Keep building.
Stay tuned, see you next week with other big news :) Another course, maybe?
Why is this course free?
This course is free and Open Source - thanks to our sponsors: Pixeltable and Opik!

Images and Videos
All images are created by the author, if not otherwise stated.
Pin this comment, this will be one of the best resource moving forward!!!
Great article man!! (and amazing collaboration)