

Introducing Kubrick Course - A Multimodal Agent powered by MCP
Free course on building an AI Agent that understands Images, Audio and Video.

Welcome to Neural Bits. Each week, I send one article that helps you understand and build AI/ML Systems from the ground up, to upskill as an AI/ML Engineer.
If you want to learn and master AI/ML, join and build alongside a rapidly growing community of 4,100+ AI/ML Engineers.
This article covers an overview of the new open-source course I’ve built in collaboration with
(from The Neural Maze). We’ll cover the major components and describe the design decisions and iterations we had to follow to build an efficient and robust system, not just a very basic demo.We called it Kubrick: An Agent that can Process Multimodal Data.

The Kubrick Course is structured as a comprehensive course, split into modules on building and coupling together Agents, Tool Calling via MCP Servers, Multimodal Data Pipelines, Engineering, LLMOps, and more.
Here’s a glimpse of what Kubrick can do 👇
The course will be structured in 6 modules, where you will learn about:
Video Processing Pipelines and Multimodal RAG.
Building MCP Servers with FastMCP, past the basic Claude Desktop Examples.
Building a Tool Calling Agent from Scratch, without frameworks.
Connecting multiple components into an AI System.
Table of contents:
Kubrick course overview
The Multimodal Processing Core
Using Pixeltable as Multimodal Data Infrastructure
The Video Processing MCP Server
The Agent API
Design iterations that we did
Opik, LLMOps, and the best practices we’ve followed
The Kubrick UI
Kubrick Course Overview
The majority of GenAI Systems focus on only one modality: Text.
When we started planning the outline of this project, we iterated over multiple components and ideas and ended up with a clear direction in mind: Make it multimodal such that we don’t process only Text, but expand the capabilities to Audio, Images, and Videos - all at once.
Imagine you have a movie scene you want to “talk to” or you want to view a specific dialogue, event, or be able to “talk” and ask questions about that particular scene.
For example, the STAY scene in Interstellar, when Cooper is trapped inside Gargantua’s Tesseract and talks with Murph, or the famous T800 thumbs up scene in Terminator 2 - Kubrick will process and will be able to answer your questions.
In our research, we’ve gone through TTS (Text to Speech), STT (Speech to Text), LLMs (Large Language Models), VLMs (Vision Language Models), research papers such Video-RAG, to see how would we integrate multiple AI Components into a single, unified project - and after months of work, we’ve done it with Kubrick.
Our approach focused on three major pillars for building this System:
1. Handle Multimodal Data Efficiently
2. Build an AI Agent workflow from Scratch, on top of this data.
3. Engineer and integrate the Software Components (UI, Backend, Services)
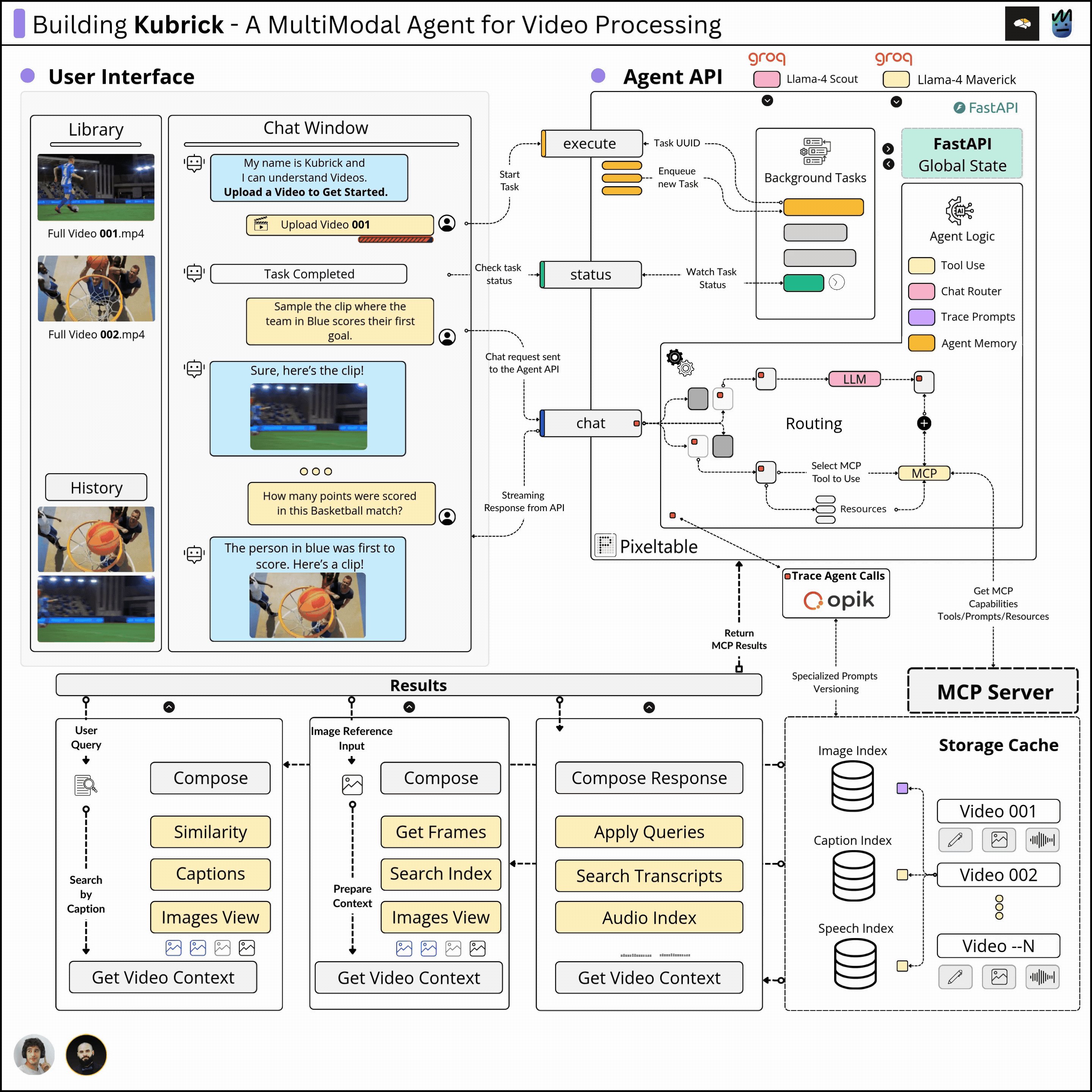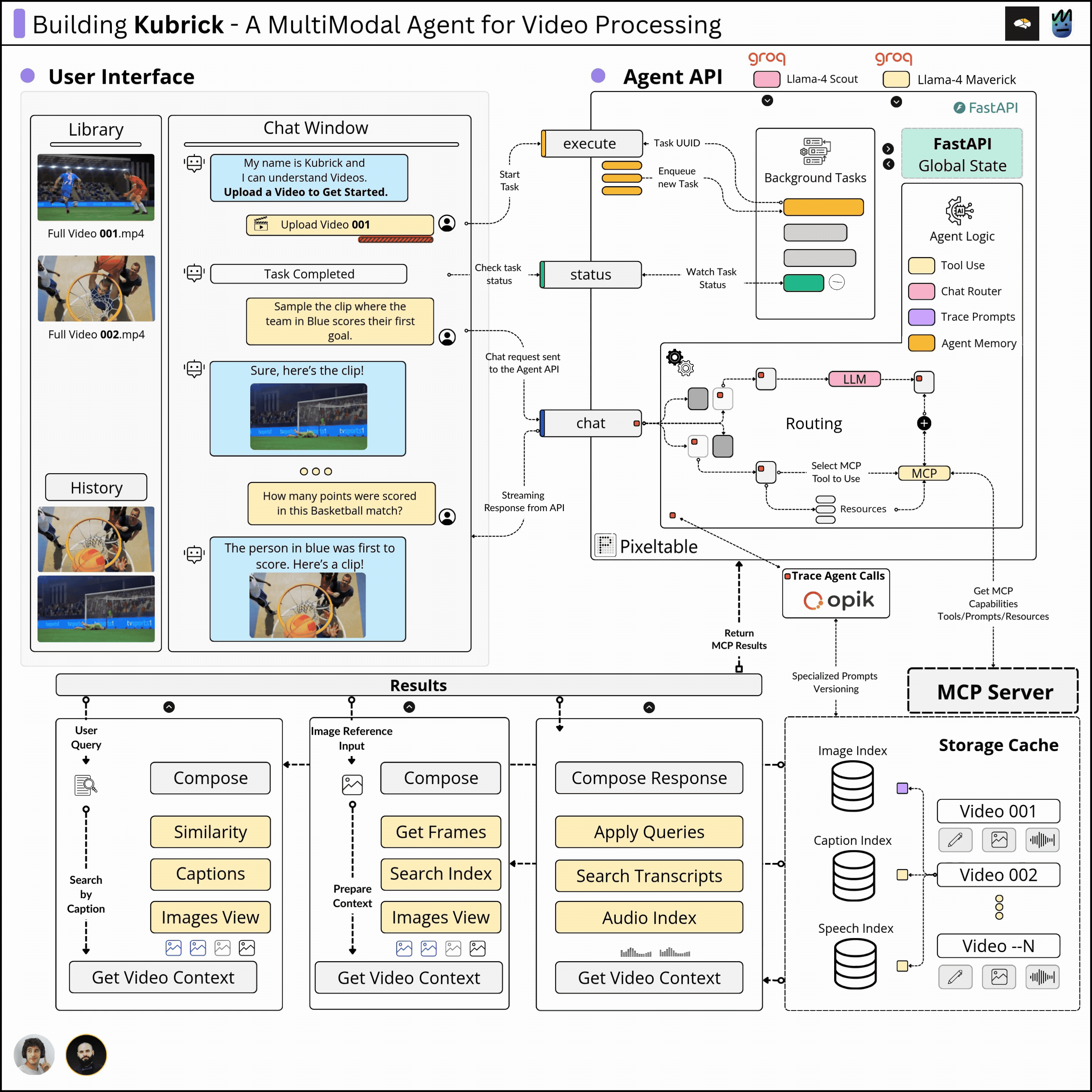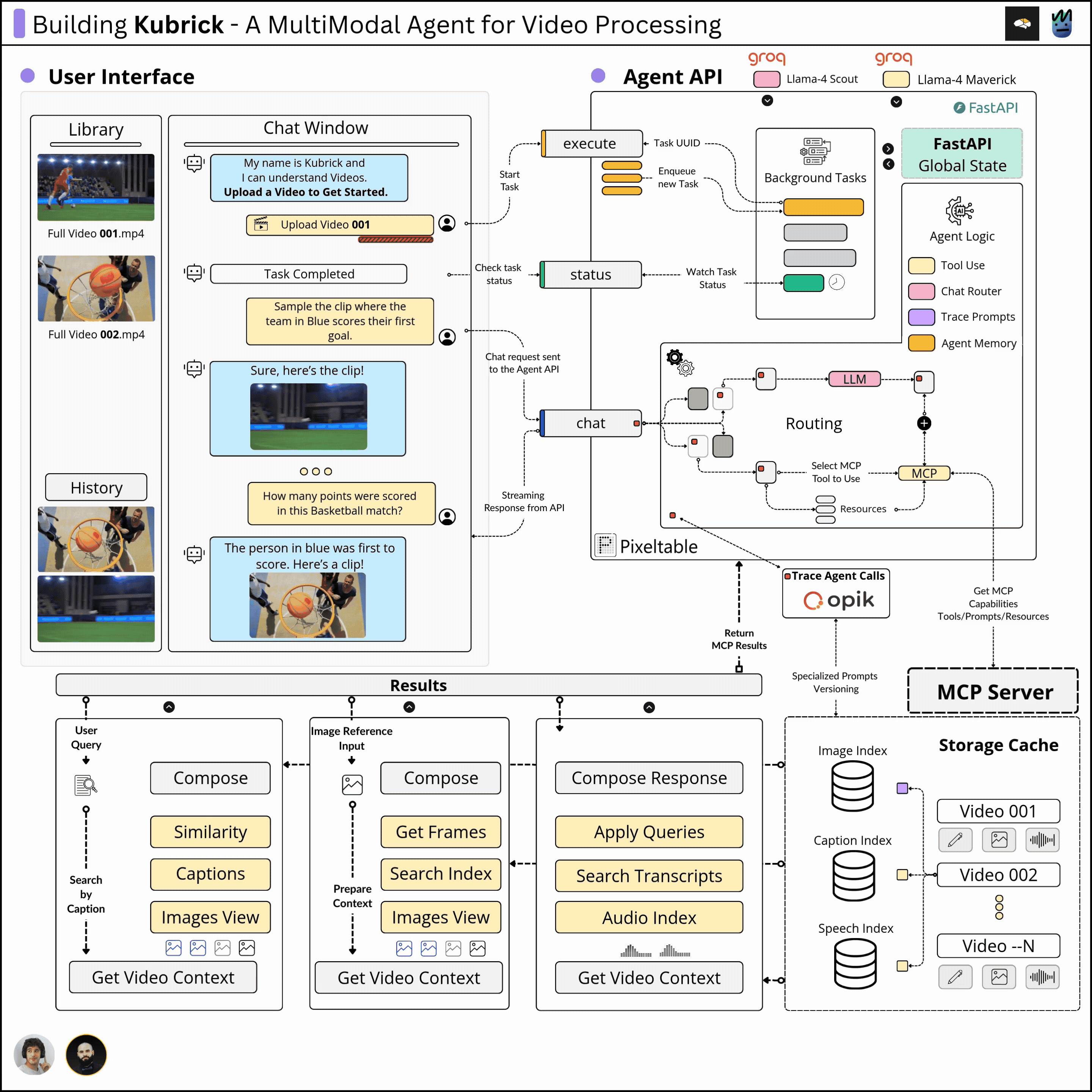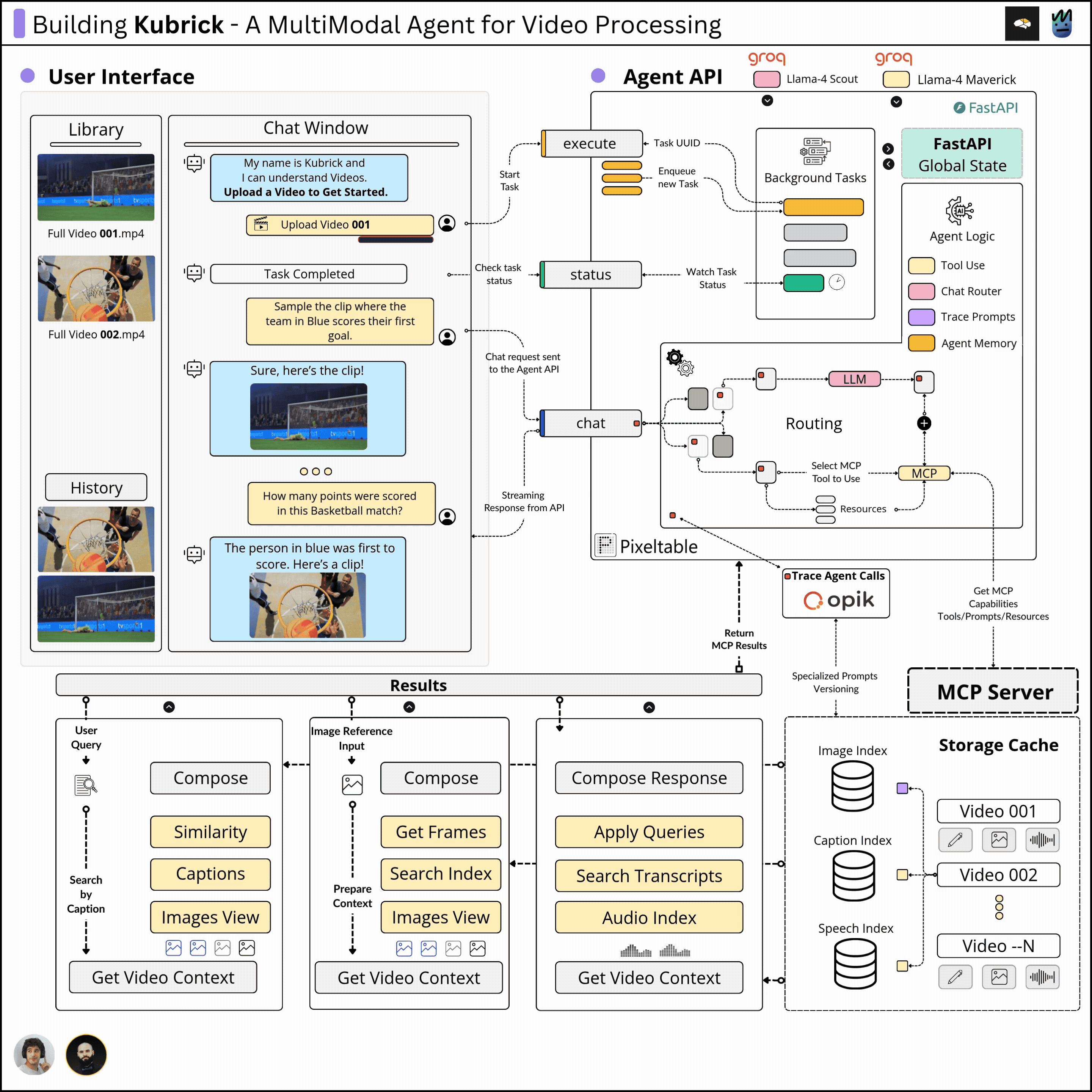
With that in sight, we’ve implemented:
1. A robust Multimodal Data workflow and exposed the capabilities via an MCP Server.
2. A tool-calling Agent, built from scratch in Python.
3. An efficient FastAPI Backend to serve the Agent and connect to an interactive UI.
In this course, we plan to unpack each of these steps, going through design, tooling, and implementation of the end-to-end System, helping you understand and learn by doing.
Although these topics might seem complex at first, with Agents, Tool Calling, MCP, Video Processing - don’t worry, we’ll make it comprehensive and easy to follow.
Apart from the functional blocks that handle the workload, we don’t want to keep Kubrick isolated and prone to degrade, and that’s why we also add statefulness, manage memory, build a scalable API, and touch on Agentic Patterns, LLMOps, and more topics that are mandatory components in all Agentic AI Systems.
With that in mind, let’s outline the Kubrick milestones!
The Multimodal Processing Core
Multimodal processing is complex and resource-intensive. Once the audio/image modalities are included, the throughput of the system can drop significantly if the design and implementation don’t fit.
With this component, we want to answer the following question:
“How should we build a component to isolate the complex processing from the Agent logic?”
We could’ve handled this entire system as a monolith; it would’ve been easier to understand and work on, but that wouldn’t stand the test of robustness, scale, and efficiency.
That’s why we isolated the Agentic logic from the intensive processing steps by using MCP (Model Context Protocol). MCP allowed us to define the video processing, computing embeddings, captioning video frames, and processing the Audio channel behind a strict API - and expose these functionalities for the Agent to access.
In short, MCP is a communication protocol that standardizes how an LLM can securely access third-party resources. It’s treated as a standard, and it’s currently being adopted in a large majority of AI projects that involve Agentic workflows.
Why MCP?
Imagine you want an AI agent to book a flight on your behalf.
We know that LLMs “hallucinate” and occasionally “make things up,” and you don’t want it to “hallucinate” the date, destination of the flight, or your card details when issuing a payment on your behalf.
To solve that problem, we can guard the `search, book, pay` logic behind a strict protocol where we define the required execution steps, and expose this functionality to our AI Agent as a “tool” or functionality that the Agent could execute with minimal required arguments.
That way, our Agent could use the:
“Identity” Resource - to fetch the required data to ID the person it’s making a booking on behalf of.
“Search” Tool - to call third-party APIs with flights, and find the required flight.
“Book” Tool - to book the flight, filling in all the required details.
“Pay” Tool - to issue a payment on the user’s behalf.
“Status” Resource - to group information and notify the user of the booking status.
That’s what we’ve done. Abstracting the resource-intensive processing on an MCP server and exposing its capabilities to our Agent API.
How does an MCP Server enhance Kubrick?
In our system, the Agent sits behind an API that processes user requests, and depending on the intent extracted from the user prompt, which could span from extracting a specific clip, explain a scene, filter by an image, or answer a question, the Agent will decide if it should use any capability it’s been given access to fulfill the request.
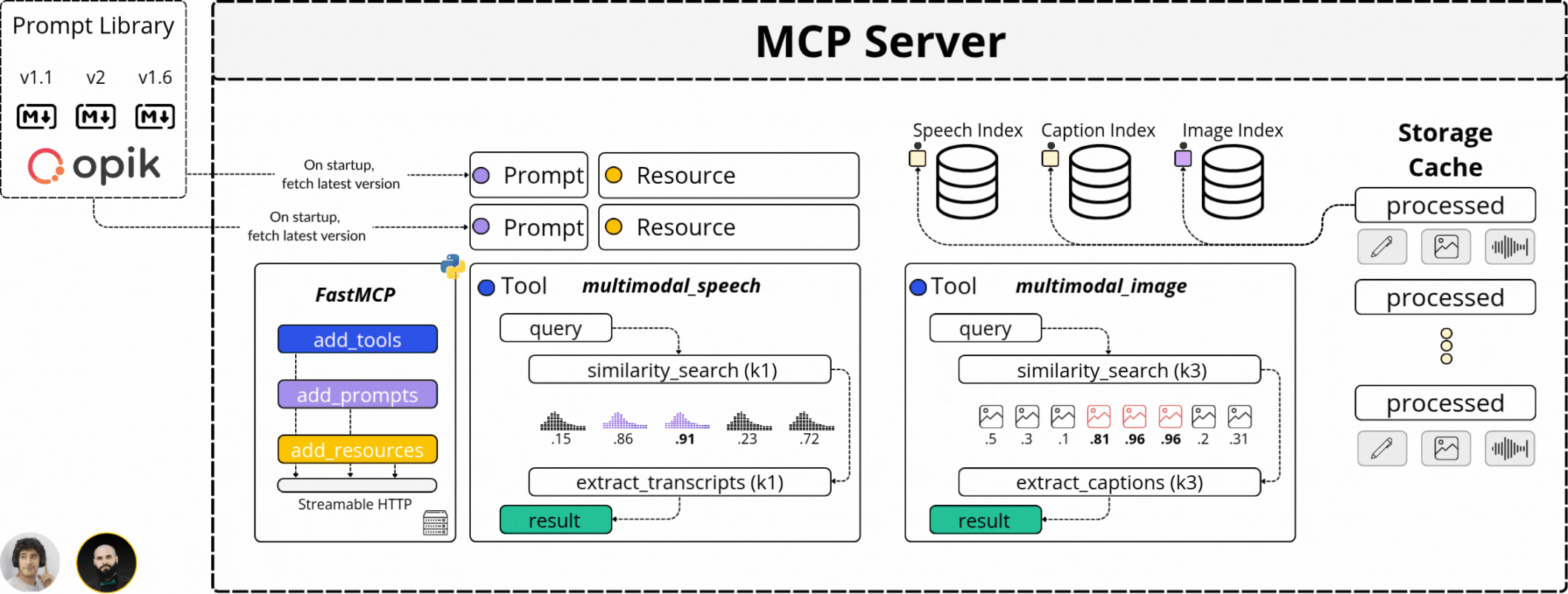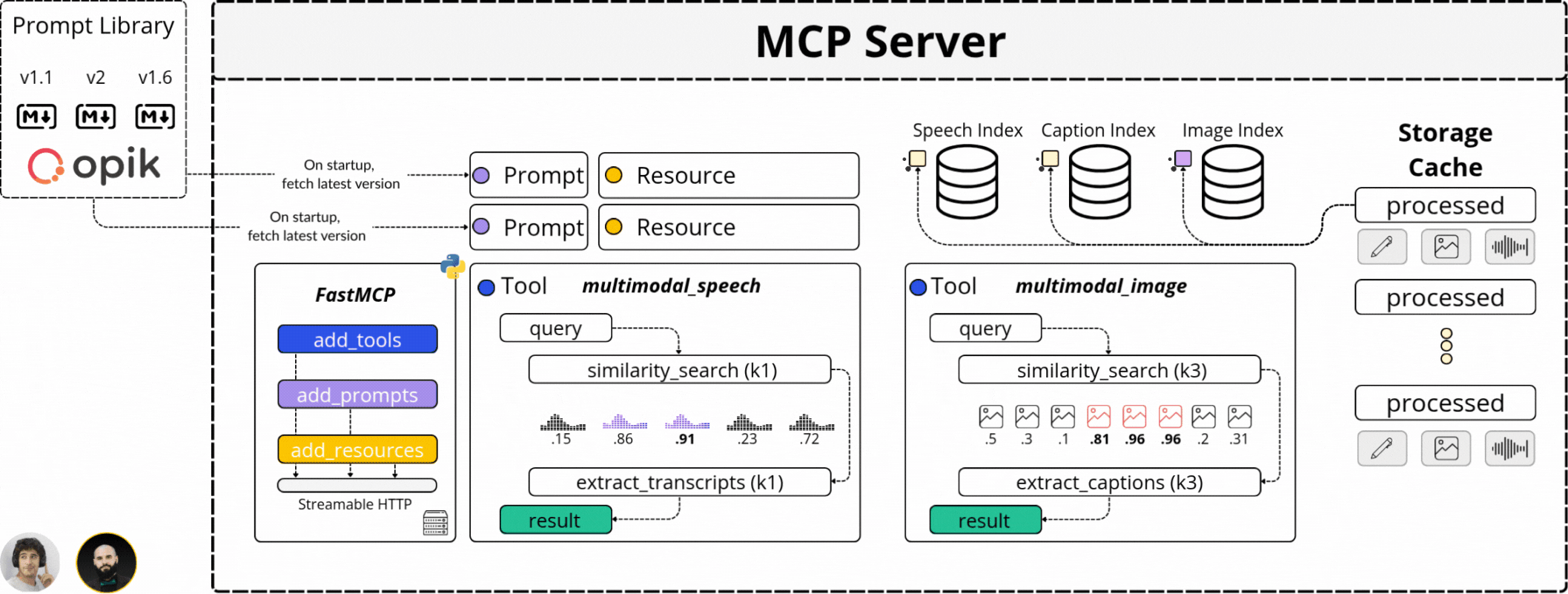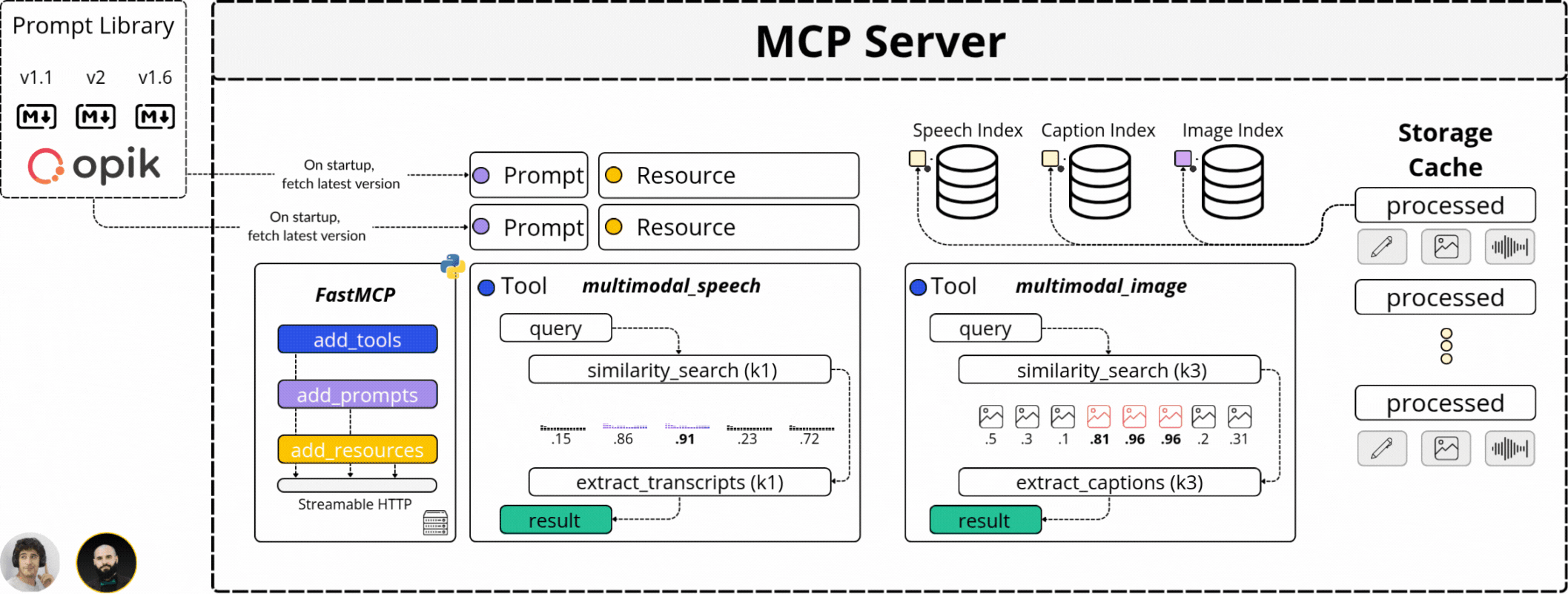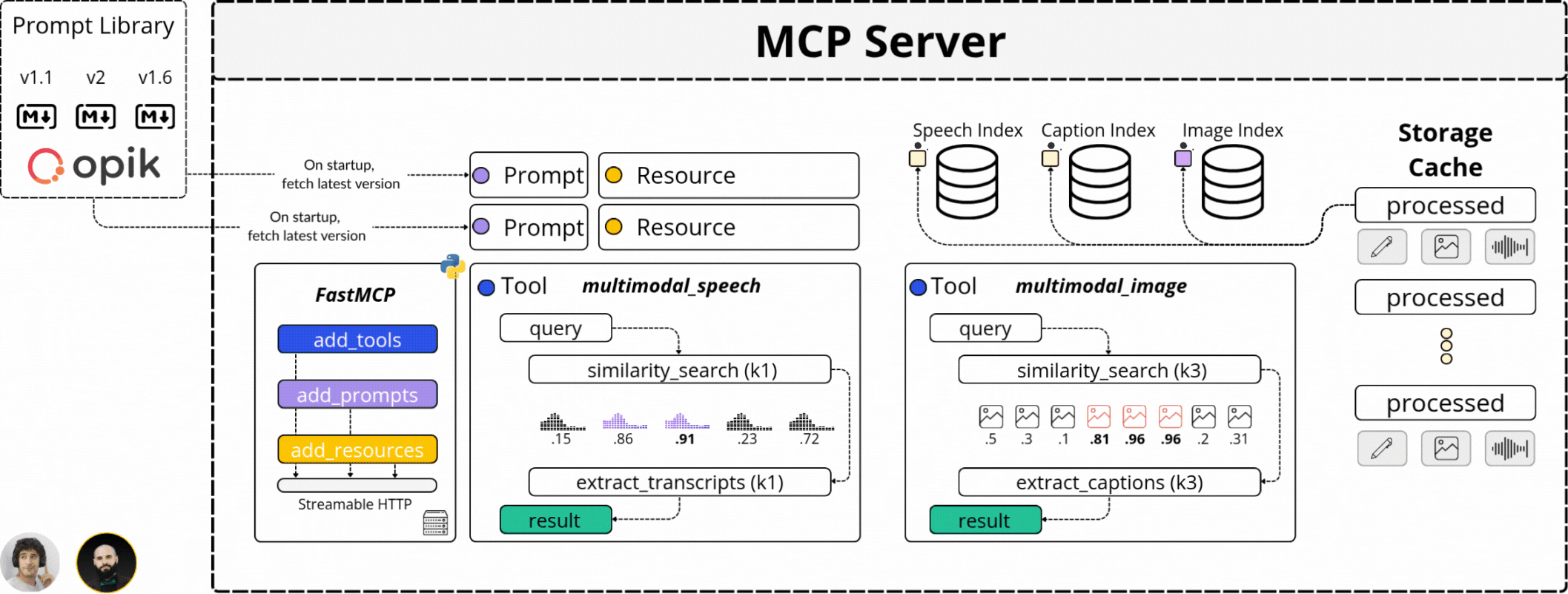
Our MCP Server covers the following functionality:
It can “search the audio transcripts” for a specific sentence, word, or phrase.
It can “search for an image” from a video or provide similar images.
It can “extract key video sequences” based on a user request.
It can “answer questions” regarding what’s happening in a video.
All these capabilities are exposed as `Tools` for the Agent. However, since our system is stateful, we also expose curated `Prompt` templates that we load from a Prompt Library and `Resources` that allow the Agent to know what videos it has processed before.
However, what we’ve discussed above represents the Top Layer of our MCP Server. The processing pipeline that powers these capabilities is more complex, as multimodal processing is 10x the difficulty of just processing Text.
How does it handle all this complex processing?
The answer to that is the Video Search Engine component we’ve built with Pixeltable.
To put things in perspective, to build a pipeline from scratch, that can:
Process a video and split it into individual frames.
Split and synchronize the Image and Audio channels to extract the audio track.
Chunk audio segments and transcribe audio to text via STT (Speech to Text)
Caption and explain images using VLMs (Vision Language Models)
Compute Image, Speech, Video embeddings for Multimodal RAG.
Keep everything incremental, tracked, structured, and resource-efficient!
It would have taken us hundreds of lines of code, complex classes, boilerplate implementations, way more development time, and a ton of edge cases.
📌 Pixeltable is a Declarative Data Infrastructure for Multimodal AI Apps. It’s the only Python framework that provides incremental storage, transformation, indexing, and orchestration of your multimodal data.
With Pixeltable, we’ve defined our multimodal processing workflow as a Table schema, adding a built-in component for each major processing step, from Video, to Audio, Image, and Text to Embedding Models, Indexes, and Storage.
Further, each video we’ve added to our Table was versioned and processed automatically following the same workflow, just as we can see in the diagram below, where we extract audio, transcribe, sample images, and compute embeddings across multimodal indexes:
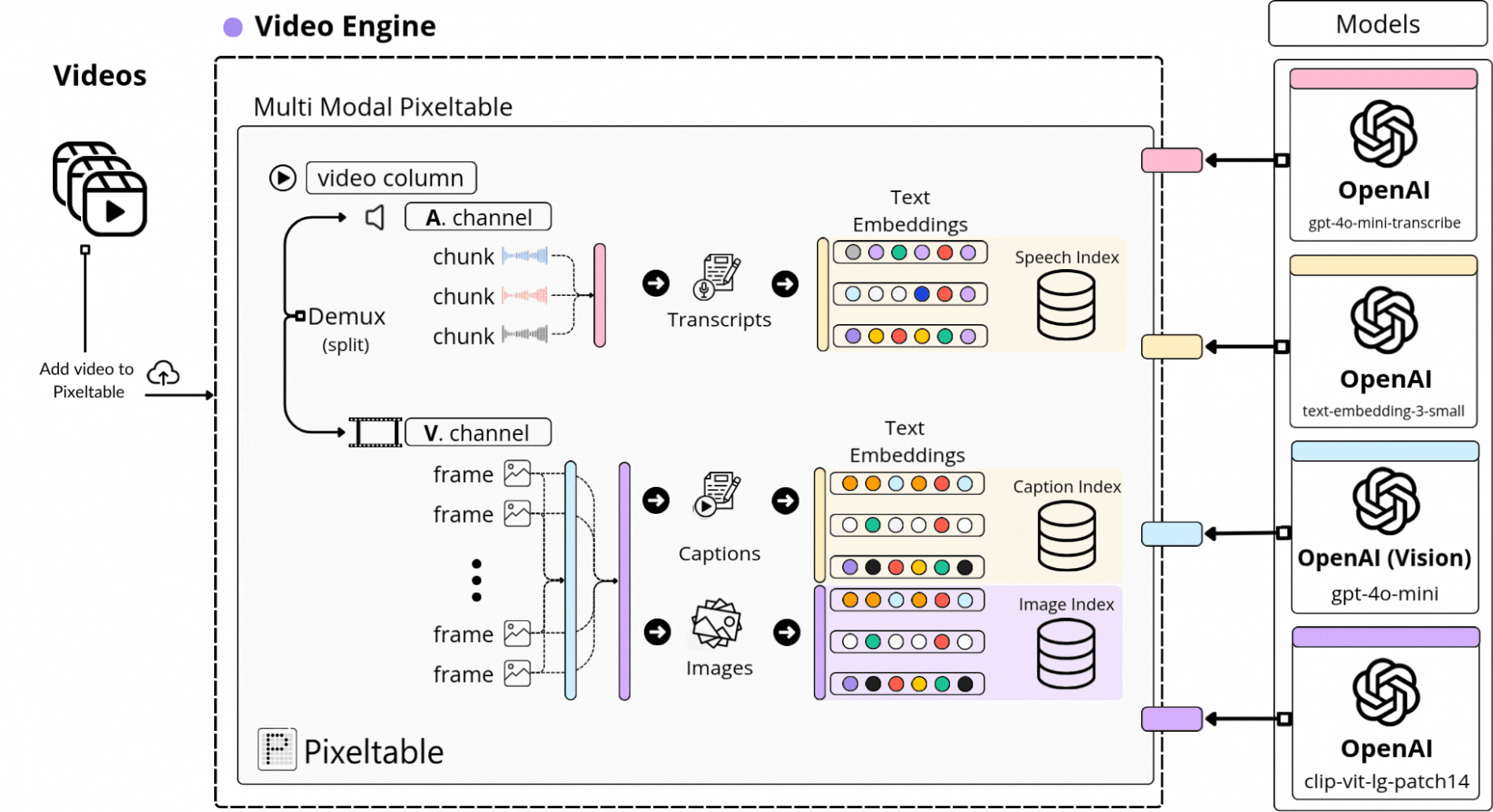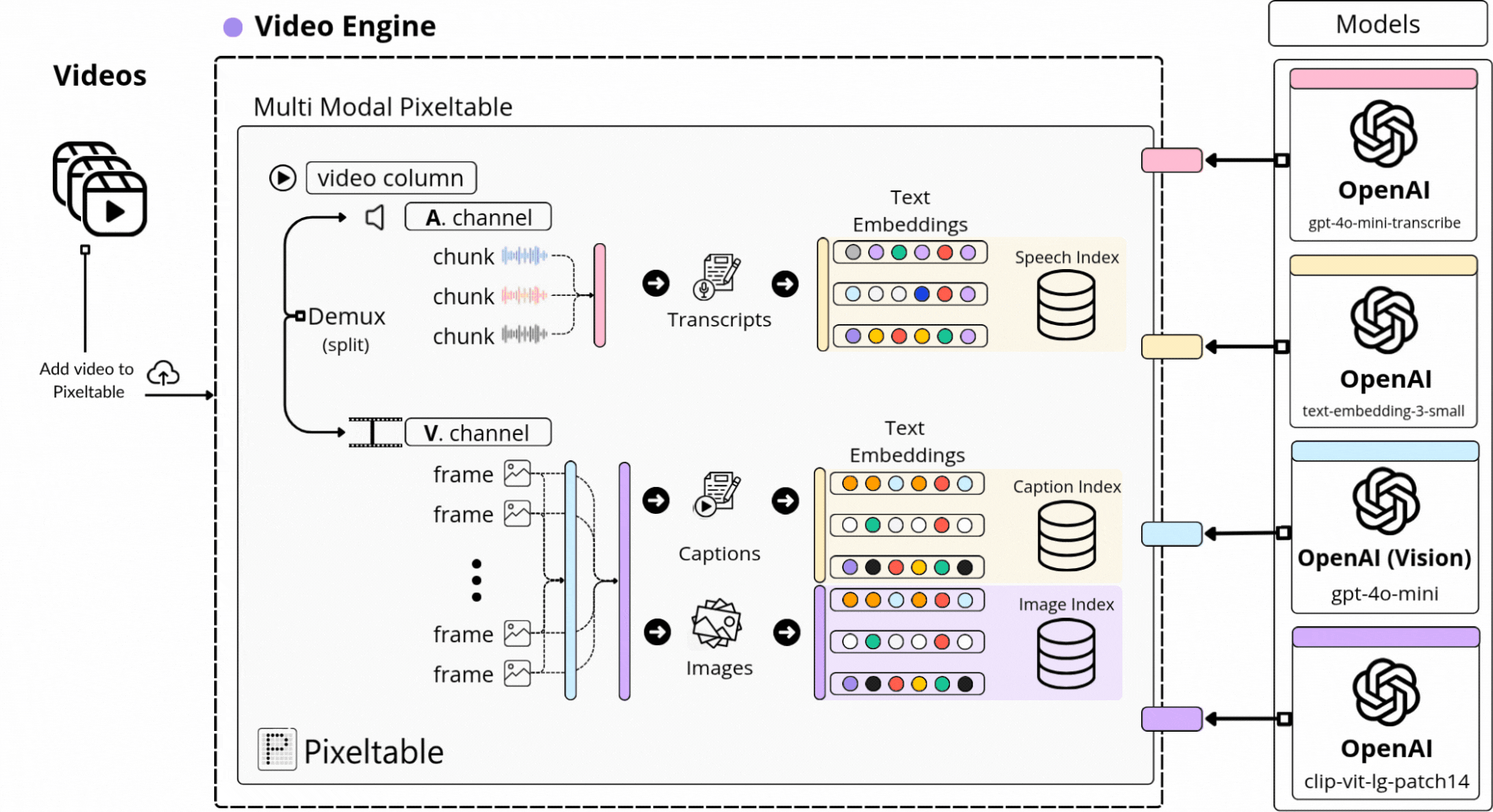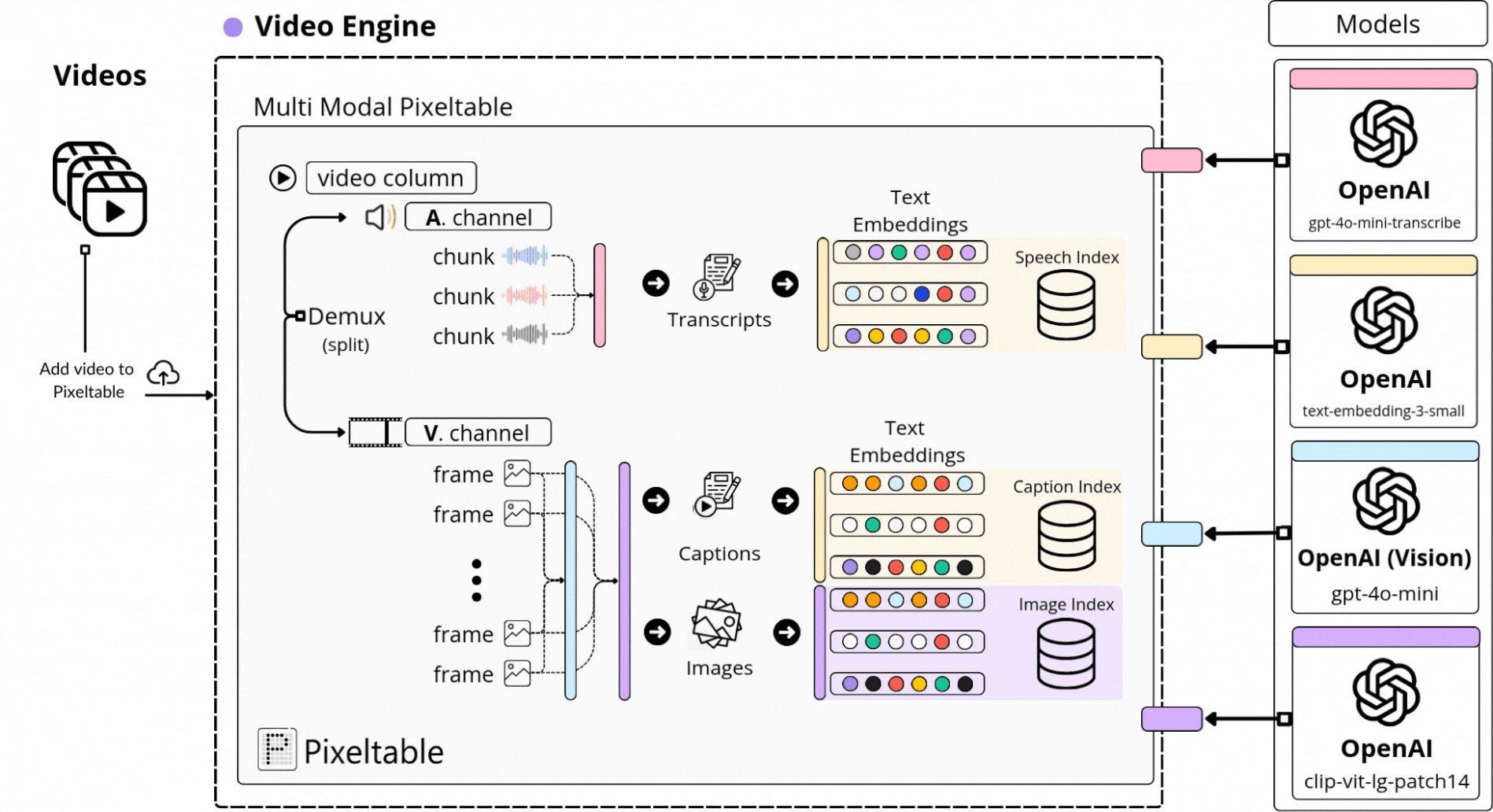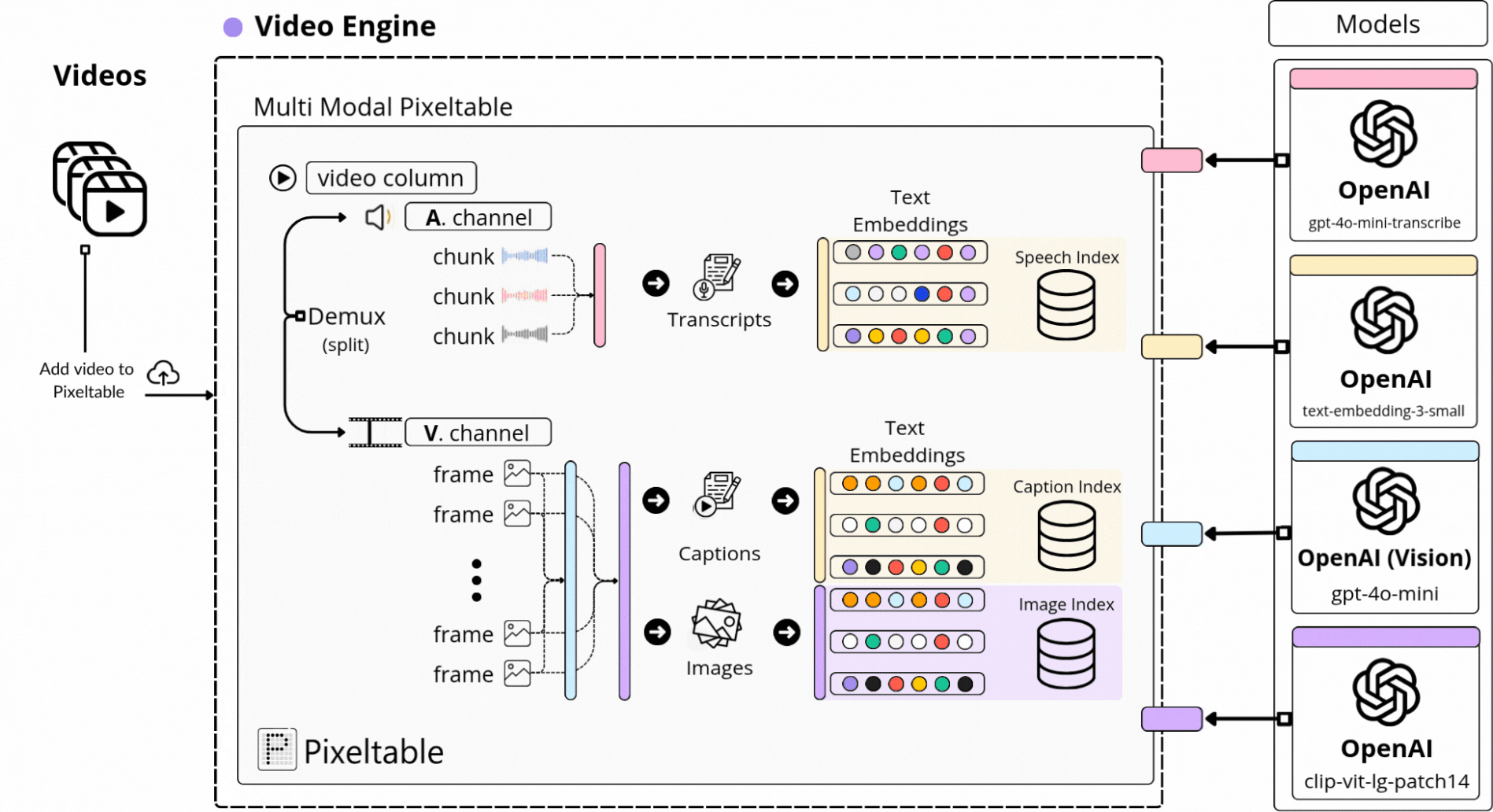
If it looks or sounds complicated, don’t worry, as in further lessons we’ll dive into the exact implementation step by step, and it’ll be easier to understand!
With the Video Search Engine powered by Pixeltable and the MCP Server that exposes all this functionality to our Agent, let’s see how this interacts with the Agent API.
The Kubrick Agent API
Being an AI/ML Engineer is not just about calling APIs and interpreting the responses; that’s just gluing/scripting components together, and involves little to no engineering.
For basic projects, that might work just fine, but AI Systems involve a lot more engineering than you might’ve thought.
How did it start?
With this component, we initially started with a basic FastAPI that was connecting to our MCP Server via a FastMCP client and accessing its capabilities, no big deal - around 50 lines of code.
While testing that setup, you won’t imagine how many roadblocks came up. Here are some important questions that popped up while we were building the API:
“Do we connect to the MCP just once and store the connection? What if the server dies and we want to use a tool - that’s a big error.”
“Is the execution of an MCP tool fast enough? How do we persist a state while doing it async such that the user won’t notice the waiting time?”
“When do we instantiate the Agent Client? How do we add and access the memory of past conversations?”
“Do we inject the required dependencies when a User Request arrives, or do we need global state for that?”
“How do we store prompt versions to evaluate and refine them?”
“How important is latency? How do we optimize? ”
What did we decide to go with?
While working on the Agent API component, we found that we spent more time on designing and optimizing for a robust system than actually writing the code.
To put things in perspective, although the heavy processing is happening on the MCP side, it also plays a role on the API side as we need to keep a state, and queuing multiple tasks such that they can work async.
Just the simple functionality of playing a video involves multiple steps that are computationally expensive and stressful for the CPU. In popular libraries for Image and Video processing, such as OpenCV, once a video is loaded, this happens:
1. Reading the Header
The video file header contains details on format, image resolution, timestamps, and what codecs are used for the Video and Audio channels.
2. Packet Separation (Demuxing)
Then it iterates through the “packets” and decodes them using the codecs read from the video header. An Image packet is decoded using a Video codec, and an Audio packet with an Audio codec.
3. Frame Decoding (CPU-Heavy)
This is the CPU-intensive part. As packets are compressed, both the video and audio decoders have to uncompressed pixel data that composes an image, and the audio sample.
Apart from reading the video and accessing the image frames, we also have to process the audio channel and get transcripts using an STT (speech-to-text), captioning video frames using a VLM (Vision Language Model), etc. Latency is key, and we want to make our system fast while also keeping in mind the UX, and don’t let the user wait for too long, in a blocking session.
Finally, we ended up with a System Design version that is robust, efficient and and non-blocking, as we’ve used advanced built-in components from FastAPI when building the Agent API.
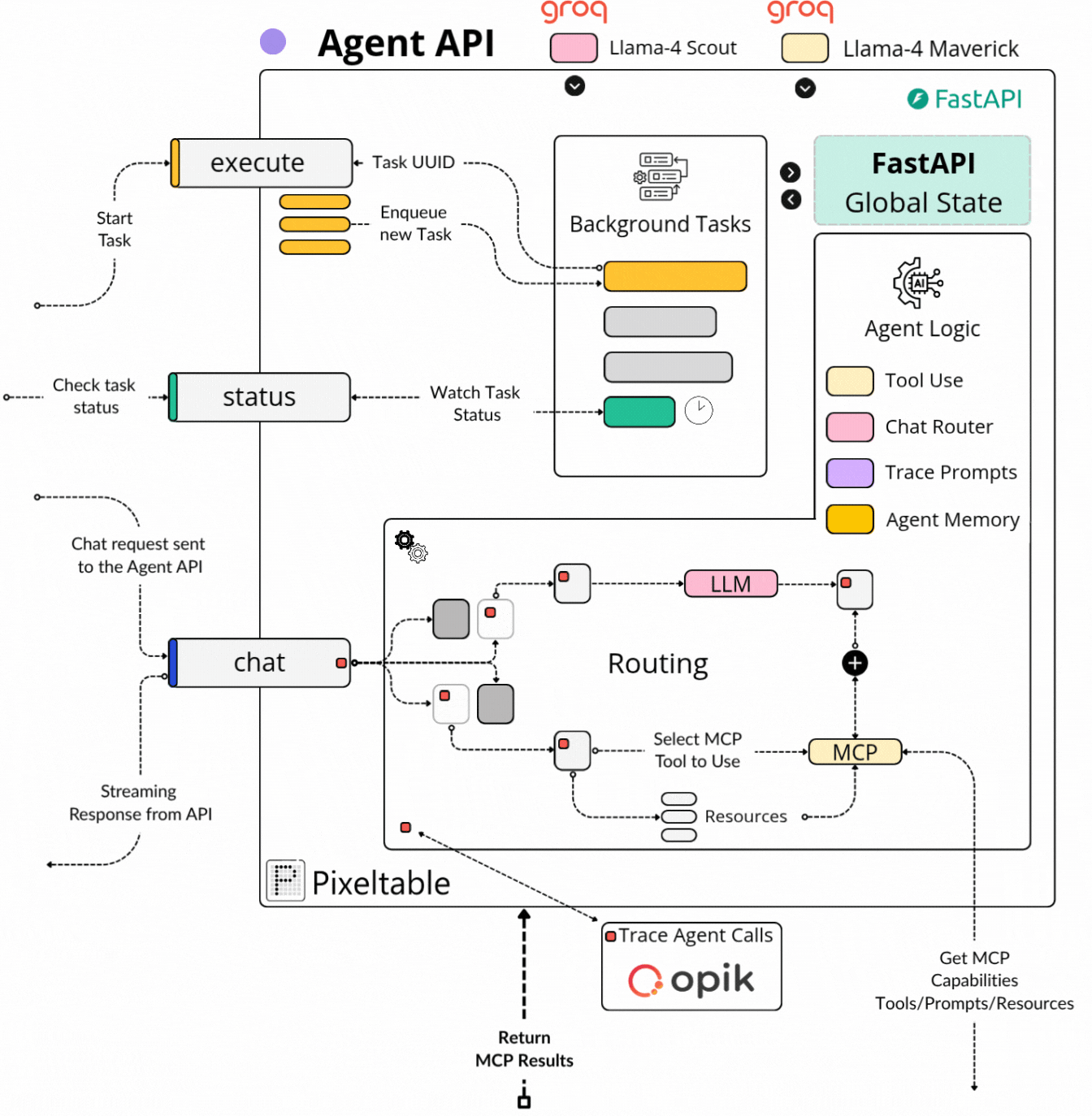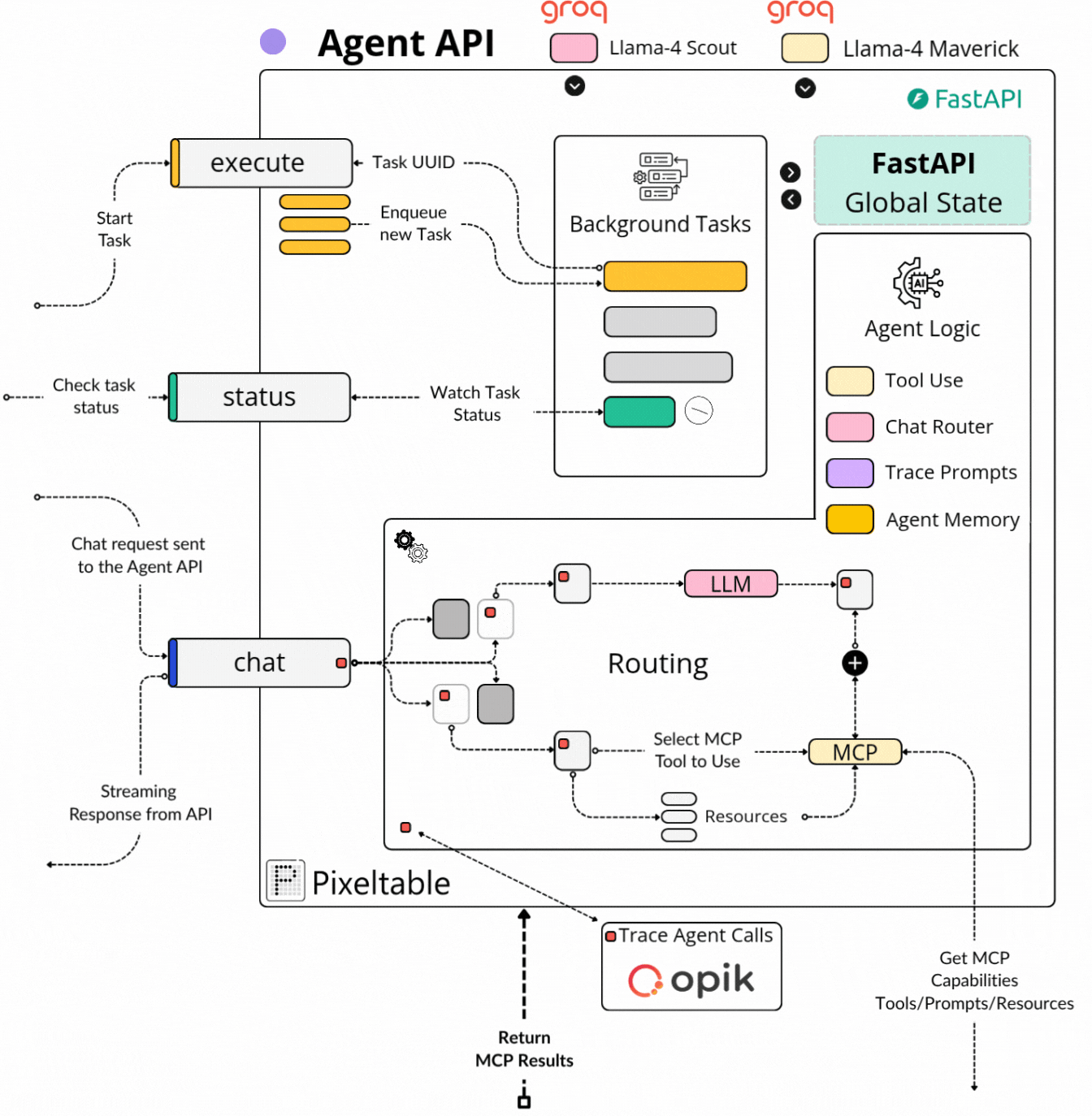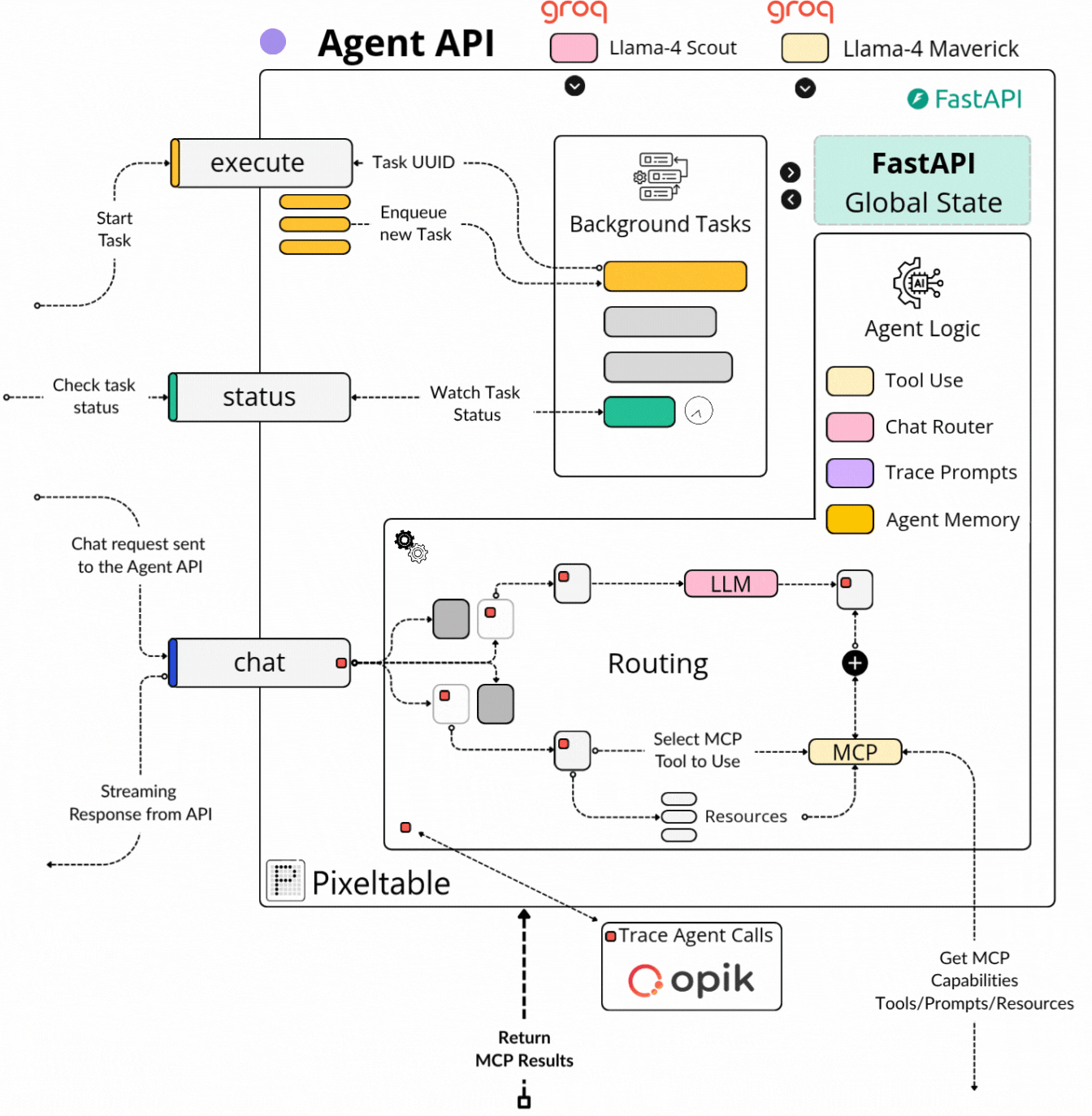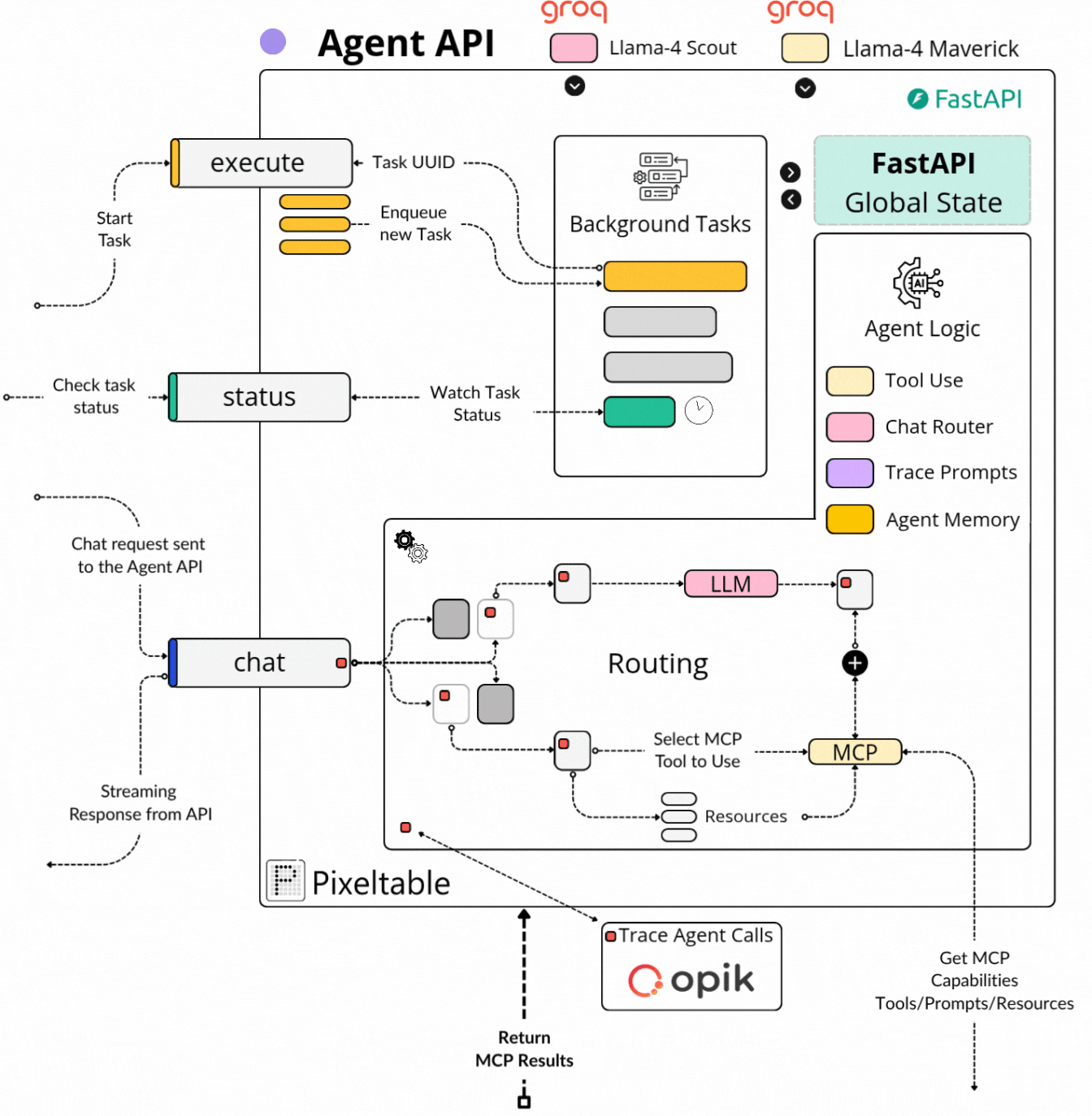
In here, we had to define an efficient processing pipeline, from when the User uploads a video up until the Multimodal processing is done, and the User can interact with it.
We used the best practices recommended by the FastAPI documentation, which include:
Using the FastAPI lifespan to persist connections and resources.
Caching Background Tasks for async processing of CPU-intensive workloads.
Task-queuing to notify the UI when a specific when the processing is done.
Streaming Chat endpoint with Prompt Tracing, Routing, and Tool Use.
Custom Response Models for both UI-API and Agent loops.
A major component that allowed us to build, evaluate, improve the accuracy, and reduce the latency of a `User → Agent → MCP → Agent → User` workflow was using Opik to cross the end-to-end Agent calls, version, and evaluate our prompt iterations.
📌 Opik helps you build, evaluate, and optimize LLM systems that run better, faster, and cheaper, providing comprehensive tracing, evaluations, to improve LLM powered applications in production.
Initially, we planned on using Opik to trace the Agent calls. Further, we found out that instead of fetching the latest prompt versions on the API side, we should do that on the MCP side, and allow the Agent to access the prompts it needs for different tasks.
That made Opik a central component of the entire system, encompassing both the MCP and the Agent.
Moreover, recently, Opik also got a new multimodal feature, which helped us trace video and images that are key to debugging and evaluating beyond the Text Traces, in an end-to-end manner.
Finally, with the MCP component handling the complex multimodal processing pipeline, the Agent API that handles the Agent ←→ MCP interactions - what’s left is the user-facing UI.
Let’s cover that in the following section.
The Kubrick UI
Although we’re going to shortly cover the implementation, we’ve built the UI in React for functionality and have used TailwindCSS for styling.
How did it start?
Initially, we started with Streamlit, which didn’t match the layout, functionality, and callbacks we wanted to add between our UI and API. Then moved to chainlit, which is more friendly at building Chat Native interfaces, but fell into the same category as Streamlit on the UI layout structure.
We also looked into Gradio, since many might be familiar with the UI components rendered through it, but found that it didn’t meet our needs.
What did we decide to go with?
We could’ve added custom JavaScript components in both Chainlit and Streamlit to handle style and page layouts, but decided to go with React in the end.
The UI was inspired by HAL 9000 (Heuristically Programmed Algorithmic Computer) that controlled the Systems of the Discovery One spacecraft in the movie 2001: A Space Odyssey.

With React, we’ve built a Chat Interface that connects to our Chat API endpoint, where the user can interact with the Kubrick Backend. Secondly, we’ve added a Video Library component where the user can upload videos and inspect previously processed ones.
In the main chat window, based on the user's request, the UI will render responses as full text or with an additional Image/Video payload.
The Complete Architecture Overview

In the following lessons, we’ll cover each component step by step, unpacking implementations, structure, and motivations.
What to do next?
Go to GitHub, star the Repo (⭐), and stay tuned for the next lessons!
If you have any questions, feel free to reach us!
Conclusion
In this article, we went through the key components of Kubrick, an open-source, free course on building a multimodal Agent to process Videos.
We shortly touched on a few implementation details across the MCP Server and Agent API, leaving out the code and core logic as we’ll cover that in future lessons.
The next article will focus on the first core component of Kubrick, the multimodal processing pipeline, covering Pixeltable, ffmpeg, Frame Sampling, Video, Image, Audio data, Embedding Indexes, and multiple AI Models.
Stay tuned, see you next week!
Sponsors
This course is free and Open Source - thanks to our sponsors: Pixeltable and Opik!

References
Neural Bits. (n.d.) Github - multi-modal-ai/multimodal-agents-course: An MCP Multimodal AI Agent with eyes and ears! (n.d.). GitHub. https://github.com/multi-modal-ai/multimodal-agents-course
Jeong, S., Kim, K., Baek, J., & Hwang, S. J. (2025, January 10). VideoRAG: Retrieval-Augmented Generation over Video Corpus. arXiv.org. https://arxiv.org/abs/2501.05874
Team, P. (n.d.). PixelTable - AI data infrastructure for multimodal applications. Pixeltable. https://www.pixeltable.com
comet-ml/opik: Debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards. (n.d.). https://github.com/comet-ml/opik
All images are created by the author, if not otherwise stated.
Let's goooo! 🚀🚀🚀
Awesome start, Alex! In section Kubrick Agent API I won't be surprised if one day it evolves into full blown API versioning like system implemented for Kubernetes :-)