



What Does an MLOps Engineer Do?
Practical MLOps example using AzureML. The progression of ML roles and multiple faces of MLOps.

Reading this article, you’ll learn about:
Short progression of roles in ML, from DS, MLE, DE, MLOps
Few key responsibilities of an MLOps Engineer
MLOps, AIOps, DLOps or LLMOps - are all the same concept
Hands-on tutorial on the core components of AzureML Python SDK
The Machine Learning field, much like the other ones that refer to technology, has followed a progression, a cycle.
In the early 2010s, the profession of Data Scientist emerged and quickly became one of the hottest ones in the field of AI and ML. Data scientists were expected to work with machine learning algorithms, focusing primarily on classical methods such as decision trees, random forests, and early applications of neural networks.
Next, in the 2010s-2015s, the Deep Learning subfield of ML gained momentum with notable work such as AlexNet, a Convolutional Neural Network for Image Recognition, and large-scale datasets such as ImageNet, MS-COCO (Microsoft Common Objects in Context) or Open Images which provided new grounds in Computer Vision and Deep Learning research applications.
With the rise of Big Data availability and successful applications of Deep Learning, new roles started to appear:
Machine Learning Engineers - while Data Scientists focused on research and prototyping, ML Engineers had the responsibility of deploying and maintaining ML models in production.
Deep Learning Engineers - working on Deep Neural Network architectures, designing and optimizing models, working on compilers or GPU kernels.
Data Engineers - as the architectures were growing in size, from simple Neural Networks to complex Deep Learning Architectures - the Data size was also growing, and required specialised roles to create and maintain data pipelines and data quality.
NLP Engineers - working with Deep Learning on systems that process and analyse human language.
In the 2017+ time window, after the Deep Learning Transformers architecture started to gain traction, and Large Language Models started surging, following the same cycle, new roles appeared, LLM Engineer, AI Engineer, Prompt Engineer, etc.
Although many of these might seem confusing, each with different takes and varying responsibilities, a separation between the roles makes sense, such that we don’t end up with ML Engineers’ job descriptions becoming novels.
Transitioning to ML Operations
Broadly in the 2020s, the “MLOps” term became well-known as businesses looked to handle ML Operational difficulties.
The term was coined in 2015 in a paper called "Hidden technical debt in machine learning systems," which outlined the challenges inherent in dealing with large volumes of data and how to use DevOps processes to instill better ML practices.
Much like the applied ML roles discussed above, MLOps serves as an umbrella term for the processes and tools used to develop, release, and maintain machine learning capabilities. Soon after, specific niches started to appear, defining various use-cases such as:
AIOps - AI for IT Operations, which aimed to keep IT systems always up and running, delivering optimal performance with minimal intervention.
 - VMware Cloud Blog")
DLOps - Or deep learning operations aimed to answer the unique operational challenges that deep learning poses, from unstructured data management to complex model architectures and optimizations.

LLMOps - Or large language model operations, refers to the practices and processes involved in managing and operating large language models (LLMs).

All these specialisations stand on the same foundation but are niched down to specific use-cases, which might be confusing at times. Given that, a good rule of thumb is to refer to MLOps as the core principle with the niche as an extension, for instance, MLOperations for Deep Learning, MLOperations for Generative AI, etc.
For a detailed analysis of the impact of MLOps in the Industry, please see:

The Role of an MLOps Engineer
An MLOps Engineer sits between Machine Learning, Software/Data Engineering, and DevOps, combining good practices from all to enable successful deployment and management of machine learning models in prod environments.

In short, the general responsibilities of an MLOps Engineer focus on:
Deployment: deploy models, making them accessible to applications and users, and managing their lifecycle.
Automation: automate deployment, retraining, and CI/CD pipelines to handle data, code, and model changes efficiently.
Monitoring and Maintenance - set up monitoring tools to track performance, resource utilization, error rates, and other metrics.
Infrastructure - containerization and cloud platforms, ensuring models run reliably at scale.
Collaboration - work closely with other related roles, DS, SWE, DevOps, MLE, etc.
Governance and Versioning - establishing versioning and lineage, data governance, tracking experiments, and general reproducibility.
Troubleshooting - analyzes logs, system metrics, and monitoring data.
Documentation - common for every role.
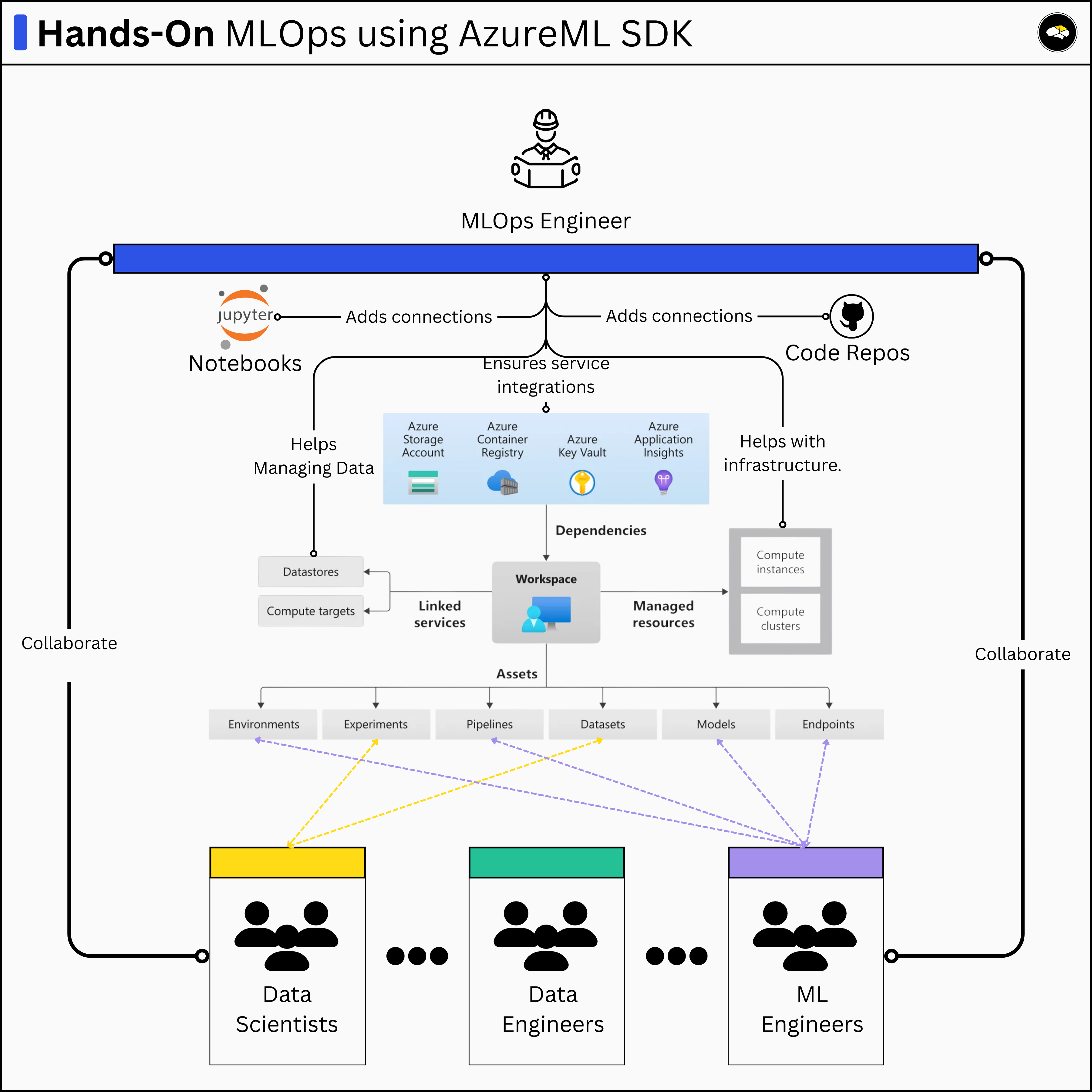
An MLOps engineer works across the entire lifecycle of an ML project and collaborates closely with various roles to remove friction and ensure a streamlined, efficient development and deployment process.
For Data Scientists, MLOps engineers set up environments for experimentation and model development. They could participate in managing access controls, compute resources, and reproducible environments to support iterative workflows with DevOps or IT Security teams.
For Data Engineers, MLOps engineers help establish data management and governance frameworks. This includes automating data lifecycle processes such as cleaning up stale data and enabling tiered storage strategies (e.g., Hot Tier, Cold Tier, Archive) to optimize cost and performance.
For ML Engineers, MLOps engineers provide CI/CD pipelines that automate model building, testing, and deployment. They also set up experiment tracking, artifact management platforms, and ensure isolated, consistent environments alongside scalable compute resources.
For LLM Engineers, MLOps engineers would participate in creating robust, large-scale compute infrastructure to support model fine-tuning and training, for instance. They integrate prompt monitoring, version control, and manage environments for iterative evaluation and feedback loops.
Across all teams involved in ML projects, MLOps engineers are responsible for building monitoring and alerting systems for deployed models and creating pipelines that enable continuous evaluation and maintenance post-deployment.
There are multiple tools, managed ones and open source ones that’ll help MLOps Engineers in their work. A few examples span across:
Data Pipelines with Airflow, Dagster, Kestra.
Data Visualization with Grafana, Tableau.
Data Management with DVC, lakeFS.
Model Lifecycle with CometML, MLFlow, Weights and Biases.
Model Serving with BentoML, Triton Inference Server, and Seldon.
Model Optimization with Accelerate, ONNX, TensorRT.
ML Pipelines with Flyte, Kubeflow, MetaFlow, ZenML.
ML Platforms such as AzureML, AWS SageMaker, or Google VertexAI.
The pool of frameworks and tools to choose from is large, and there’s no clear distinction on which set to use. Companies end up more or less building and managing a custom solution with open-source options, or going with a managed MLOps solution such as VertexAI, SageMaker, or AzureML.
In the following sections, we’ll do a hands-on walkthrough on the Azure Machine Learning platform, and cover the topics a MLOps Engineer would need to know when working with AzureML.
An MLOps Engineer’s work on Azure ML
AzureML, similar to Sagemaker or VertexAI, is a managed ML Platform as a Service. It encompasses all the tooling needed for an end-to-end ML Project workflow by automating and building abstractions over components that an MLOps Engineer needs to work on.
As a good mental model to have, every workflow that runs in the cloud has the same pattern:
Environment Isolation - where components are containerised as Docker, Podman containers.
Data Access - where data sits on GCS (Google Cloud Storage), S3 Buckets, or Azure Blobs.
Infrastructure Provisioning - with IaC (infrastructure as Code) being abstracted and easy to spin up or roll down.
CI/CD - with Artifact and Container Registries.
Pipeline Provisioning - with Kubeflow, Metaflow, Airflow.
Security & Role Management - with specific teams having access to closed components, data sources, monitoring dashboards, or compute resources.
In the following sections, we’ll unpack and explain each of these items with examples.
The Workflow
In simple terms, the workflow of a job run in AzureML involves the AzureML Workspace, which is created in Azure Cloud, and the azureml-sdk to communicate and access the workspace from your IDE.
We’ll dive into the SDK later on, but wanted to mention it as it provides context to the image below.

If it looks complicated, don’t worry, we’ll dive into each component step by step.
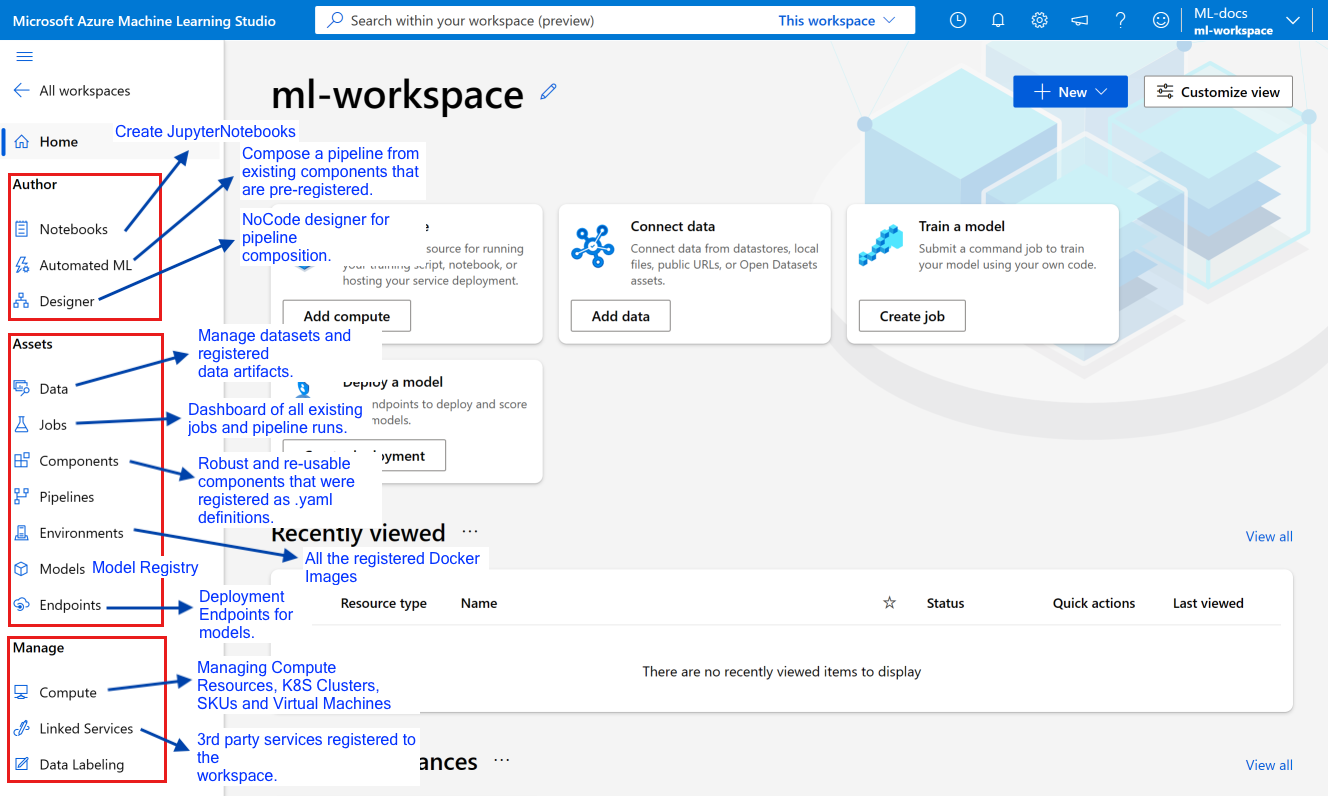
1. The Azure ML Workspace
The workspace is the top-level resource and centralized hub. It organizes and manages ML assets such as datasets, experiments, models, compute resources, and pipelines within a specific Azure region and resource group.
When you create a new AzureML Workspace, it’ll automatically create the following sub-components:
An ACR (Azure Container Registry) where it’ll manage and version Docker environments.
An Azure Storage Account where it’ll store metadata from each job or pipeline run, alongside any artifact produced by a job run.
2. The MLClient SDK
We install the SDK using the `azure-ai-ml` Python package. Alongside the SDK, we need the `azure-identity` package to create an Identity object with our credentials that’ll be used by the MLClient.
uv init my-azure-app
uv add azure-ai-ml azure-identityAlongside the SDK, we need to install the `az cli` tool and run `az login` which will prompt us to the Microsoft Login Page interactively.
Once logged in, the Credential will be auto-populated when used by the SDK.
Now, we connect to our Workspace from Python using the MLClient. As arguments, we need the SubscriptionID, ResourceGroup, Workspace, and credentials. In this example, we use the DefaultAzureCredential as it automatically fetches credentials we have on our system.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
) With the `ml_client`, we have access to `.environments`, `.compute`, `.jobs`, `.artifacts`, and everything else our Workspace shows in the UI.
3. The Environment
An environment refers to a custom schema that simply hosts the Docker environment metadata. AzureML uses JSON schemas to validate each component that’s part of a job run, including Environments, Compute, DataAccess, and more.
For instance, the environment schema contains multiple fields such as name, version, image, tags, description, conda_file, and others. The simplest setup with required fields only includes name, version, and image.
In code, using the SDK, we can define an environment as follows:
from azure.ai.ml.entities import Environment
env = Environment(
name="custom_env",
version="1.0",
description="Some env",
image="python3:10",
)
env = ml_client.environments.create_or_update(env)Furthermore, we could specify a `conda_file` argument when creating the Environment, and it’ll automatically build and version our custom Docker image. Once an environment is created, it’ll appear on the Environments tab in MLStudio UI.

4. The Compute Resources
Compute refers to individual Virtual Machines (VMs), Compute Clusters (Elastic, Managed Clusters), Serverless Compute, or Kubernetes Clusters.
Same as with the Environment, following the cluster resource schema and instance resource schema, we can create a VM Instance:
from azure.ai.ml.entities import ComputeInstance
vm = ComputeInstance(
name="my-compute-instance",
size="Standard_DS3_v2",
description="Simple VM"
)
compute = ml_client.compute.begin_create_or_update(vm).result()
print(f"Created compute instance: {compute.name}")
Or a compute cluster:
from azure.ai.ml.entities import AmlCompute
cluster = AmlCompute(
name="my-cluster,
size="STANDARD_D2_V2",
min_instances=0,
max_instances=4,
idle_time_before_scale_down=120
)
compute = ml_client.compute.begin_create_or_update(cluster).result()
print(f"Created compute cluster: {compute.name}")5. Creating Data Assets
A data asset object created using the SDK follows this schema and is a reference to datasets stored in Azure Blob storage, which could be either a single file `uri_file` or a folder `uri_folder`. Once created, it’ll be versioned and tracked in the workspace.
from azure.ai.ml.entities import Data
data_asset = Data(
name="my_dataset",
description="Sample data asset",
version="1",
path="./data/sample_data.csv",
type="uri_file"
)
data = ml_client.data.create_or_update(data_asset)6. Submit a Job Run
A Job Run uses the `command` component from the SDK and follows the command schema. With this, we’ll have to define the:
Code Path - all the files under this path will be packaged and uploaded to our AzureML job run as code_resources.
Command - the command to run inside our environment container.
Inputs - a mapping specifying the job inputs, could be Data Asset to mount to the running job. For a pipeline, this could be also be the output of a previous job.
Outputs - the output mapping of the current job.
Environment - the environment object or name.
Compute - the compute resource name.
from azure.ai.ml import command
job = command(
code="./src",
command="python train.py --data-path ${{inputs.data}}",
inputs={"data": "azureml:my-dataset:1"},
environment="custom_env:1.0",
compute="my-compute-cluster",
experiment_name="my-experiment"
)
result = ml_client.jobs.create_or_update(job)
print(f"Submitted job with ID: {returned_job.name}")7. Inspecting Results
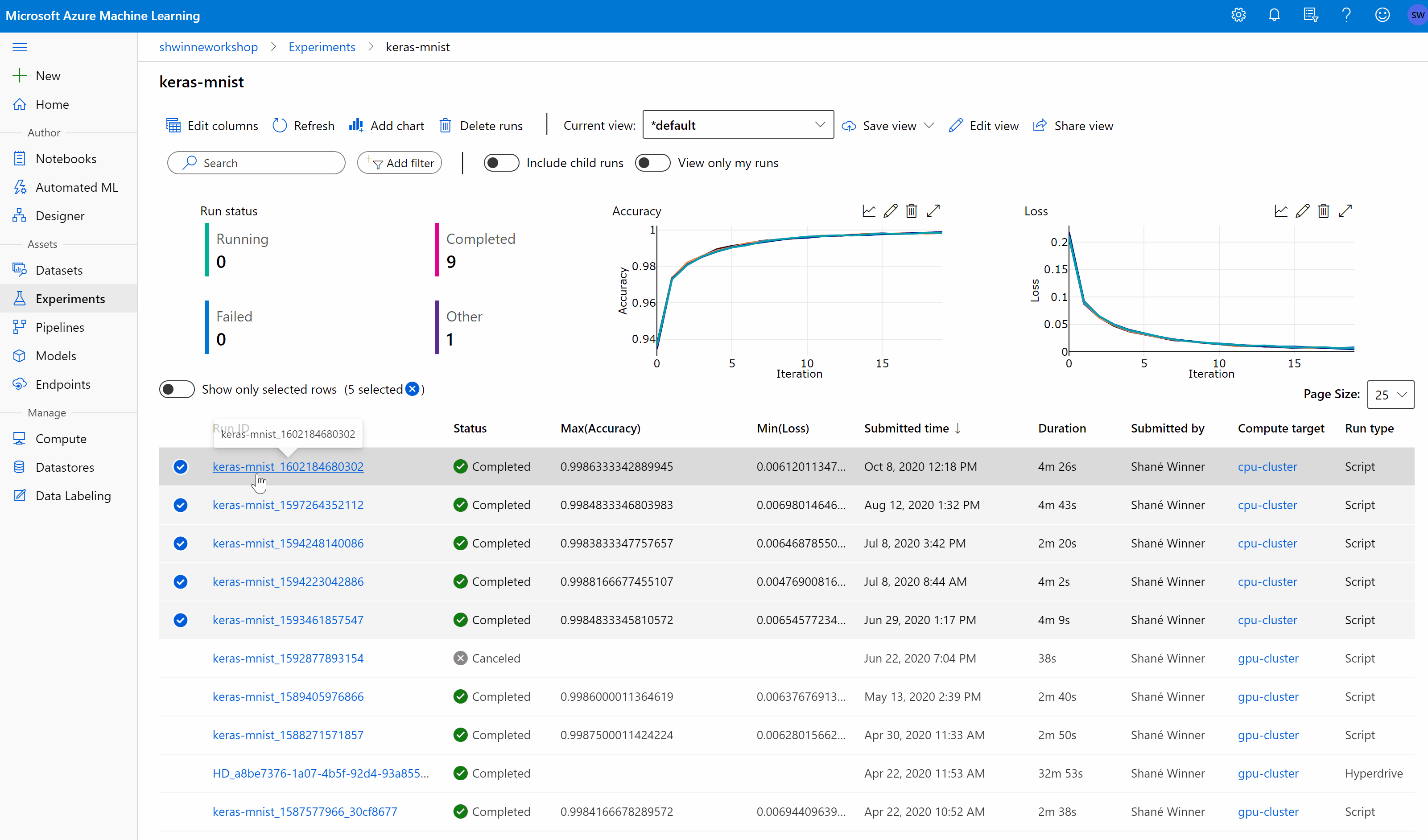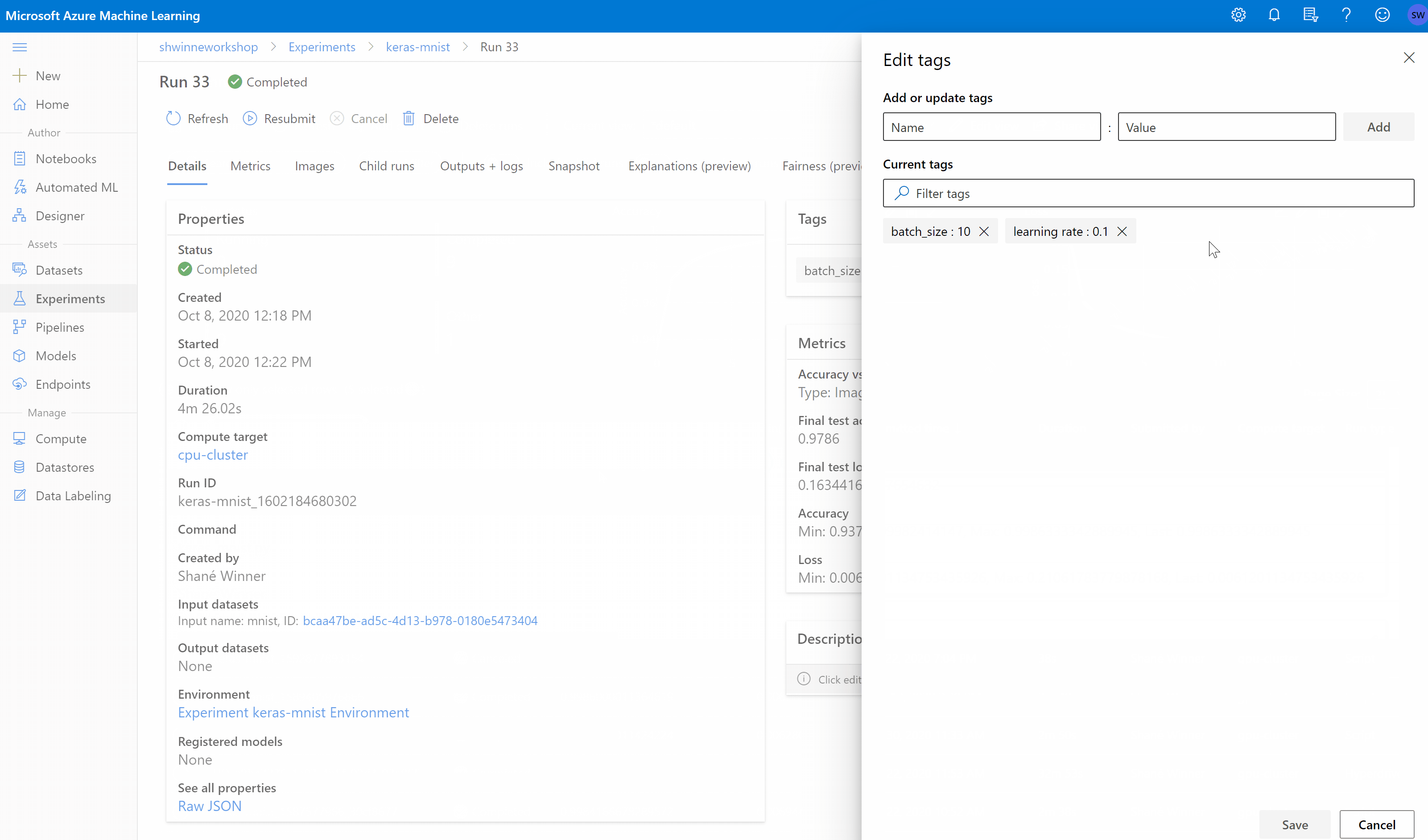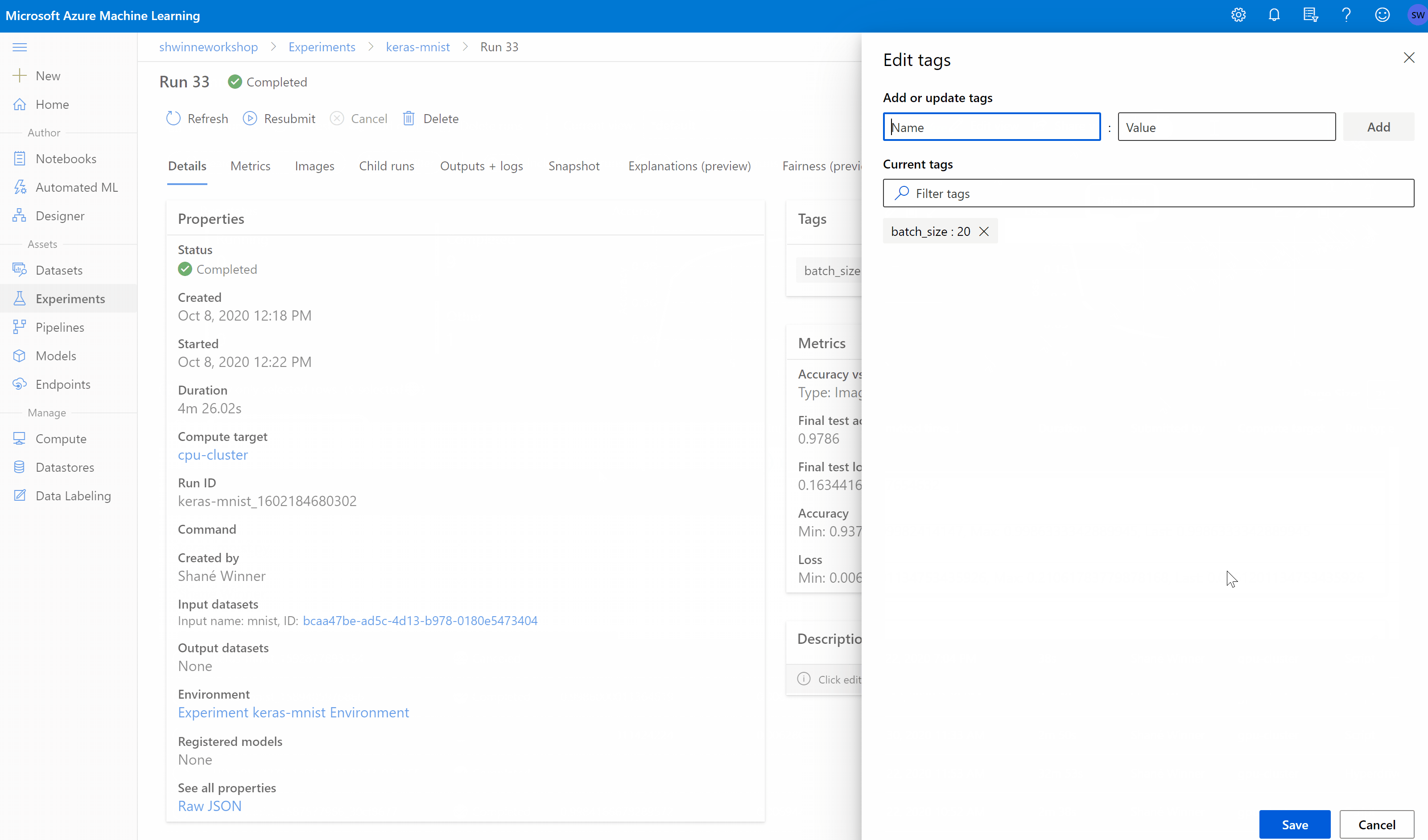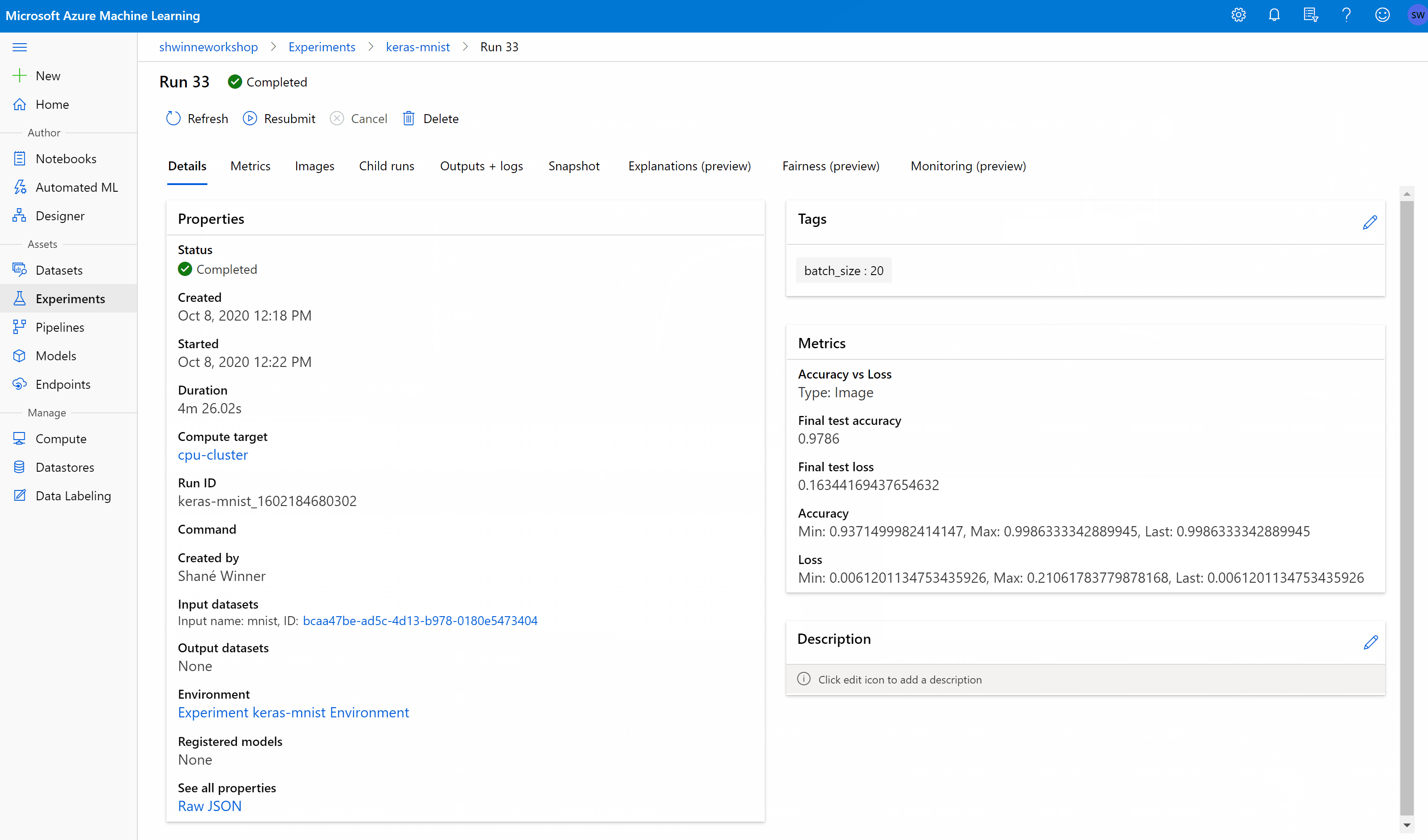
After we trigger a job, in the UI, on our workspace, we could see its status alongside a detailed overview.
Composing a complete Pipeline
Now that we’ve covered the core steps to follow when running jobs in AzureML, let’s walk through a full example of a pipeline.
The AzureML DSL (Domain-Specific Language) syntax simplifies the way we can connect multiple commands into a structured ML pipeline. It standardises and configurates the input-output mechanisms between components automatically.
For instance, here’s a pipeline example using the SDK:
from azure.ai.ml import dsl, command, Input
@dsl.pipeline(description="Image Classification Pipeline")
def image_classification_pipeline(dataset: Input):
prep_data = command(
name="prepare_data_node",
code="./prep_data",
command="python prep_data.py \
--input_data ${{inputs.input_data}} \
--training_data ${{outputs.training_data}}
--test_data ${{outputs.test_data}}",
inputs={"input_data": dataset},
outputs={
"training_data": Output(type="uri_folder"),
"test_data": Output(type="uri_folder")
},
environment="prep-env:1"
)
train = command(
name="train_node",
code="./train",
command="python train.py \
--input_data ${{inputs.training_data}}
--output_model ${{outputs.output_model}}",
inputs={"training_data": prep_data.outputs.training_data},
outputs={"output_model": Output(type="uri_folder")},
environment="train-env:1"
)
score = command(
name="score_node",
code="./score",
command="python score.py \
--input_data ${{inputs.test_data}}
--input_model ${{inputs.input_model}}
--output_result ${{outputs.output_result}}",
inputs={
"test_data": prep_data.outputs.test_data,
"input_model": train.outputs.output_model
},
outputs={"output_result": Output(type="uri_folder")},
environment="score-env:1"
)
return {"scoring_result": score.outputs.output_result}
dataset_in = Input(path="azureml:my_image_data:1")
pipeline_job = image_classification_pipeline(dataset=dataset_in)
pipeline_run = ml_client.jobs.create_or_update(pipeline_job)In this example, we define three command jobs: prep_data, train, and score. Each command runs as an independent step, but they are chained together through explicit input-output dependencies, which creates a lineage between them.
Specifically, the `train` command uses the output artifact (e.g., processed data) produced by the `prep_data` step as its input. Similarly, the `score` command takes both the output model from the `train` step and the test data output from the `prep_data` step as inputs.
This explicit passing of outputs as inputs between steps is how Azure ML SDK v2 pipelines define dependencies, and the commands will be scheduled to run accordingly.
In the MLStudio, we will see the following pipeline representation:
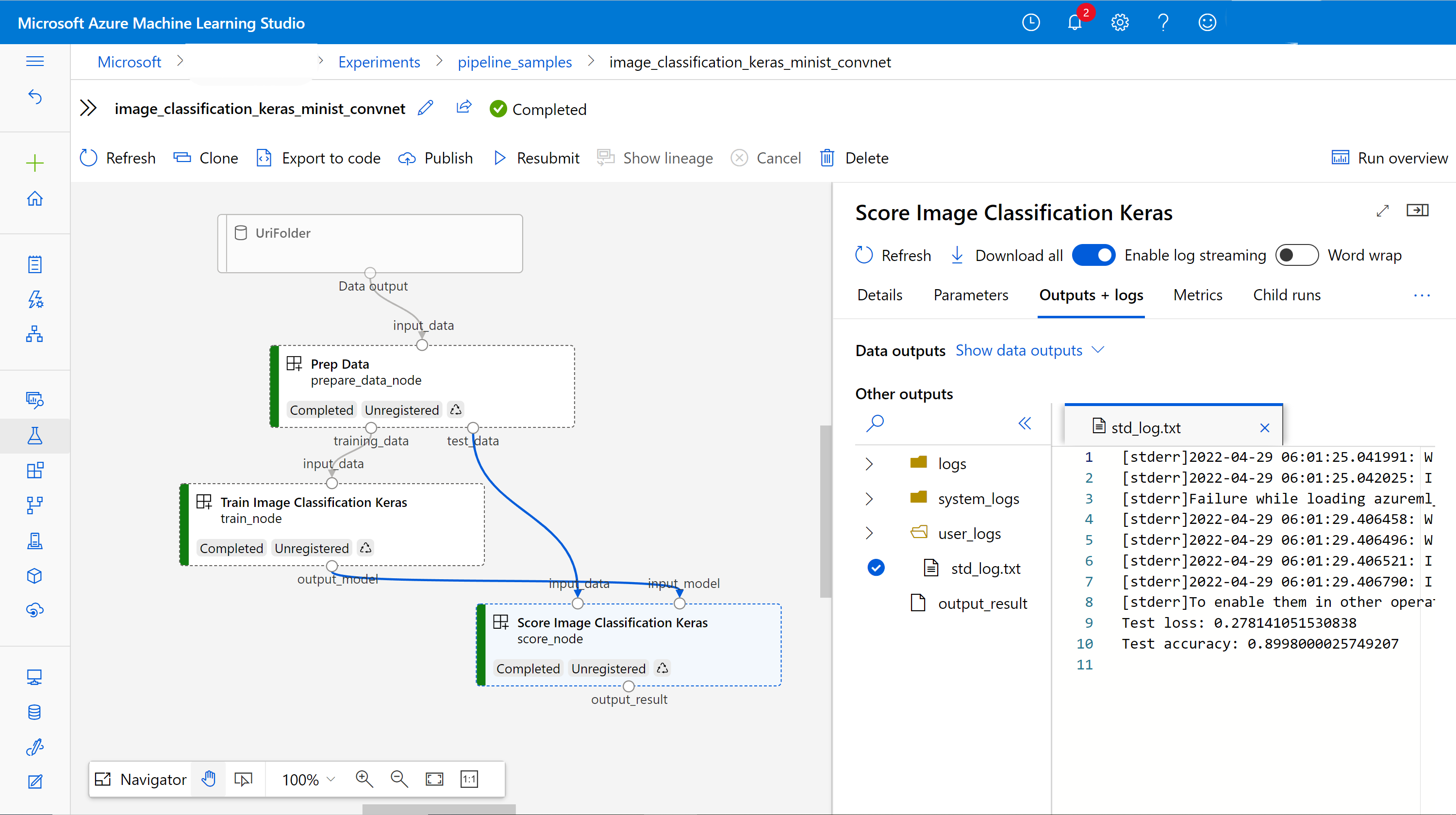
For experiment-tracking, AzureML integrates with MLFlow by default, thus anything logged via MLFlow will be persisted in the job/pipeline job’s artifacts and can be accessed via Parameters/Metrics in the MLStudio UI.
The logging system in AzureML splits logs into system and user, with the former storing health checks and metrics of the compute where the job is running, while the latter contains everything logged by the user.
Conclusion
In this article, we’ve started with a short progression of the ML field regarding the DS, ML Engineer, and AI Engineer roles, to build a context for the MLOps Engineer role.
We highlighted the growing need for MLOps, mainly driven by advances of ML into Deep Learning, Generative AI, and the complex challenges these impose on operationalization, continuing with a few examples of what an MLOps Engineer does, the problem he solves, and the toolsets he might use to accomplish that.
We then explored and explained the basics of Azure Machine Learning, which is a fully-managed solution for end-to-end ML, similar to AWS Sagemaker and Google Vertex AI, and covered every core component one needs to understand to be able to build and run ML pipelines in Azure.
This article, although focused on AzureML, these components are similar to other platforms out there, as all involve Container Isolation, Infrastructure, Data Management, Tracking, and Monitoring.
This makes it a solid starting point to understand the full ML project lifecycle and the core responsibilities of an MLOps Engineer.
References:
Standardize Pipelines with Domain-Specific Languages | Dagster Blog. (n.d.). https://dagster.io/blog/scale-and-standardize-data-pipelines-with-dsl
Dowling, J. (2025, February 25). The 10 Fallacies of MLOps. Hopsworks. https://www.hopsworks.ai/post/the-10-fallacies-of-mlops
Razvant, A. (2024, August 13). MLOps at Big Tech and why 51% of AI projects fail to reach production. Neural Bits.
https://neuralbits.substack.com/p/mlops-at-big-tech-and-why-50-of-ai
DLOPs: MLOPs for deep learning. (n.d.).
https://valohai.com/blog/dlops/
Günthner, J. (2025, April 8). The evolution of machine learning and its roles. PALTRON.
https://www.paltron.com/insights-en/the-evolution-of-machine-learning-and-its-roles
Jeaugey, S., & Jeaugey, S. (2022, August 21). Scaling Deep Learning Training with NCCL. NVIDIA Technical Blog.
https://developer.nvidia.com/blog/scaling-deep-learning-training-nccl/
Sdgilley. (n.d.). Quickstart: Get started with Azure Machine Learning - Azure Machine Learning. Microsoft Learn.
https://learn.microsoft.com/en-us/azure/machine-learning/tutorial-azure-ml-in-a-day?view=azureml-api-2
All images are by the author unless otherwise noted.