

The Future of Agentic AI is Small.
How NVIDIA’s Nemotron Nano V2 SLM built for long-context reasoning and fast inference can compete with models 4–5× its size.

Welcome to Neural Bits. Each week, I write about practical, production-ready AI/ML Engineering. Join over 7000+ engineers and learn to build real-world AI Systems.
As you already know, I love technical deep dives.
This is Part I of a small 2-part series where I unpack the new NVIDIA Nemotron models
In this first piece, I’m focusing on the text-only side of the family, the Nemotron Nano v2 Transformer-Hybrid models, which outcompete other popular and powerful open models on a large set of reasoning Benchmarks.
In Part II of this series, I’ll be covering the latest addition, the Nemotron Nano 2 VL 12B, which is a powerful VLM for multi-image, long video reasoning, and document understanding.
In this mini-series:
→ ✅ Part I - The Nano 2 Family of SLMs for best-in-class Reasoning Models.
→ Part II - The Nano 2 VL Model for Agentic AI capabilities on Vision Tasks
If you’re building agents, research workflows, or anything that relies on “thinking steps,” Nemotron Nano v2 is one of the most interesting architectures you can study right now.
(To navigate the topics, please use the Table of Contents on the left)
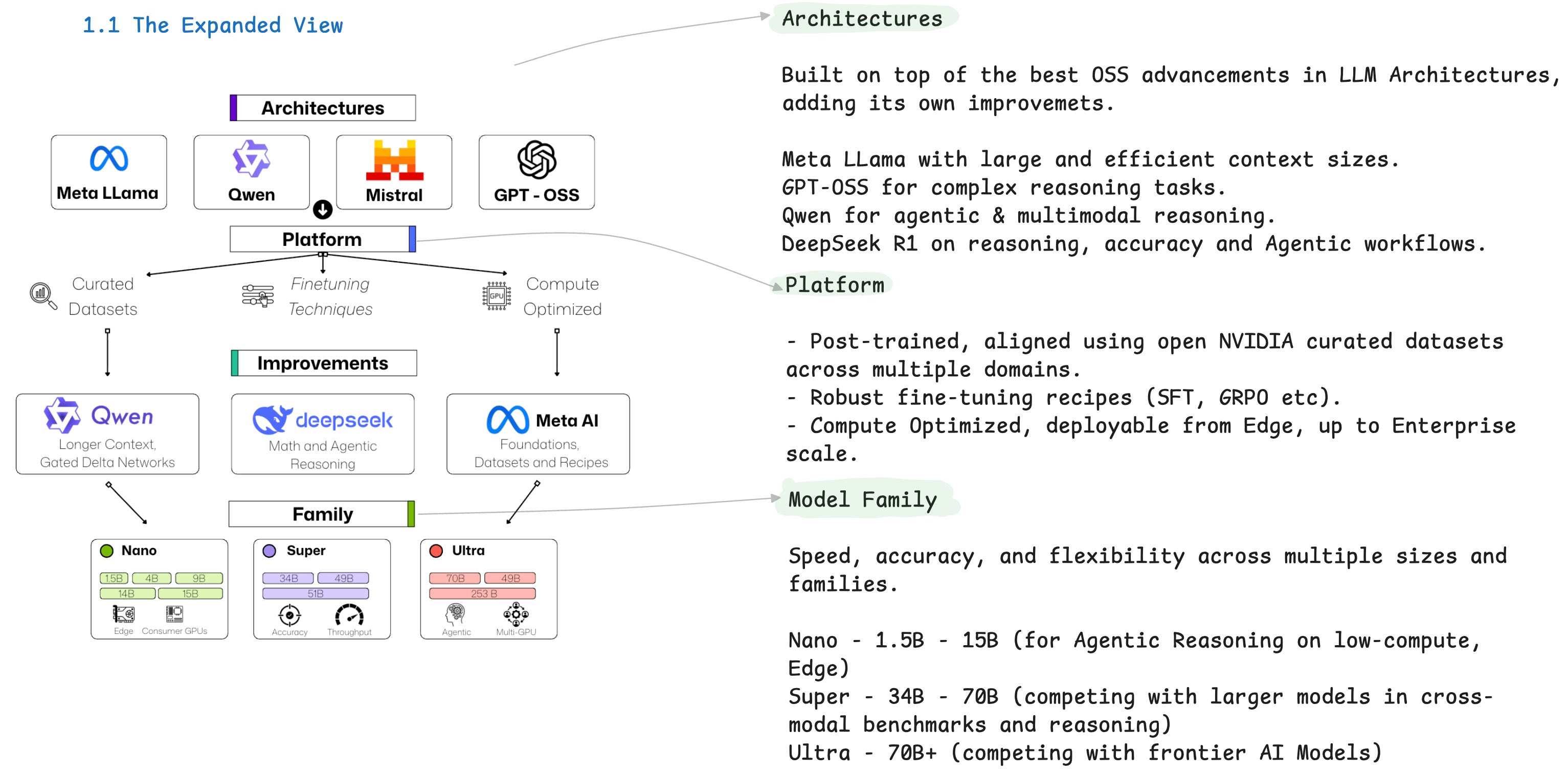
The NVIDIA Nemotron Family: Open Models for Agentic AI
NVIDIA Nemotron is not only a model architecture, although it might seem so.
It’s a family of models, curated datasets, and finetuning recipes, all open-source following NVIDIA’s license, allowing developers to build efficient and specialized AI Systems.
Note: A training recipe describes the step by step workflow of finetuning a model. For instance, starting with SFT (Supervised Finetuning), then iterations of Reinforcement Learning steps using Group Relative Policy Optimization (GRPO).
Nemotron models are openly available and integrated across the AI ecosystem so they can be deployed anywhere - from edge to cloud. These are a result of NVIDIA’s direction to create fully transparent models, helping developers build domain-specific AI agents and own the explainability of their outputs.
Unpacking the Nemotron Model Family
We can summarize the key details in 3 major components, as shown in Figure 1.
Competing with Frontier Models
One notable example is Llama-3_3-Nemotron-Super-49B-v1_5, which builds on top of Meta Llama 3.3 and is optimized for advanced reasoning and agentic AI tasks. At only 49B parameters, it ranks higher than Qwen3-32B MoE, and it overthrows the previous Llama-Nemotron-Ultra-253B, a model 5x its size, across a large set of reasoning and scientific benchmarks.

To put that in balance, the Llama-Nemotron-Ultra-253B competes with Frontier Models such as Gemini 2.5 Pro, OpenAI o3-mini, and takes the lead on the popular DeepSeek R1, a 650B+ reasoning model, the latest Llama 4 Maverick, GPT4-o, and others, on the GPQA Benchmark as shown in Figure 3.
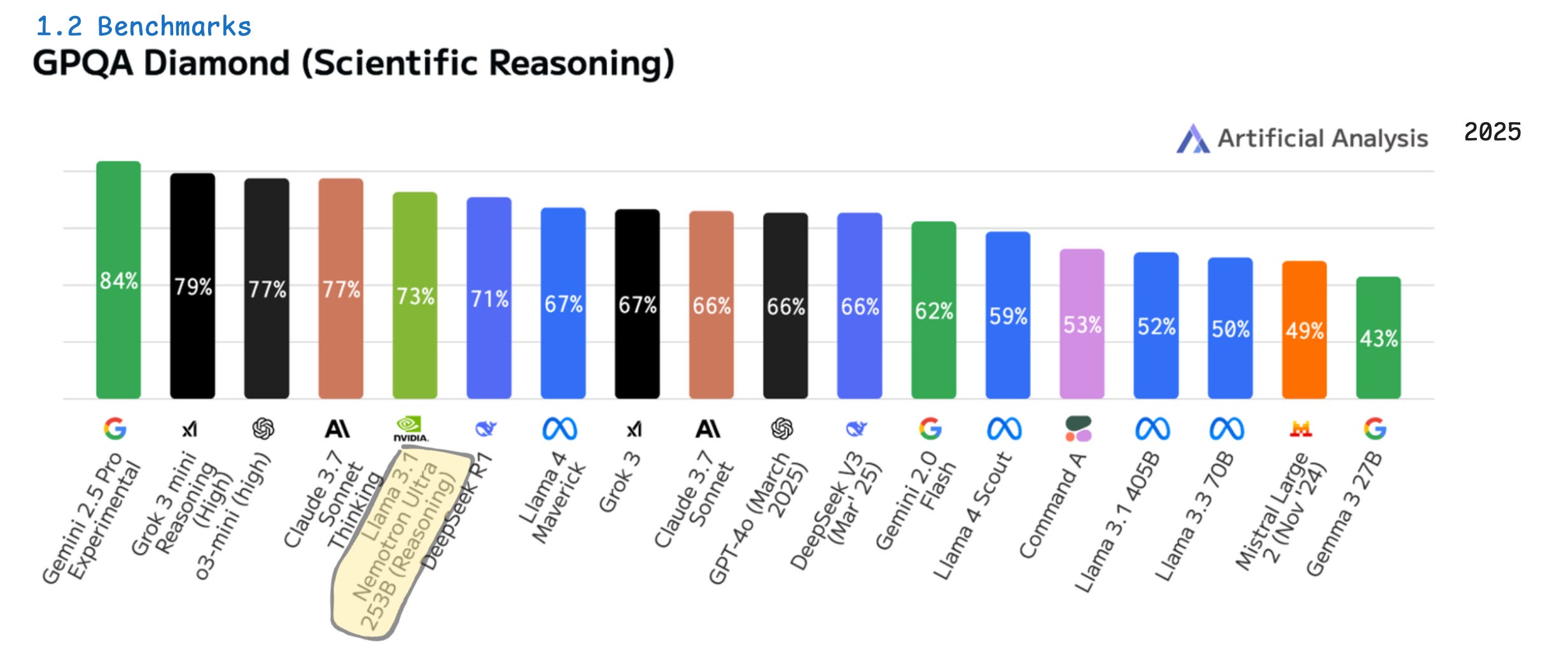
Note: GPQA is a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. The questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are “Google-proof”).
These are the text-only models, capable of advanced reasoning, deep research, tool calling, and overall Agentic AI-related tasks. They are designed for enterprise-grade accuracy and performance, compatible with popular Inference Frameworks (TGI, vLLM, TensorRT-LLM) or prebuilt as Inference Microservices (NVIDIA NIM) for large-scale deployment.
Companies such as CrowdStrike, ServiceNow, and DataRobot already use Nemotron in their products, and even NVIDIA uses it internally to help with new GPU Chip Designs. [3]
The Nemotron Nano V2
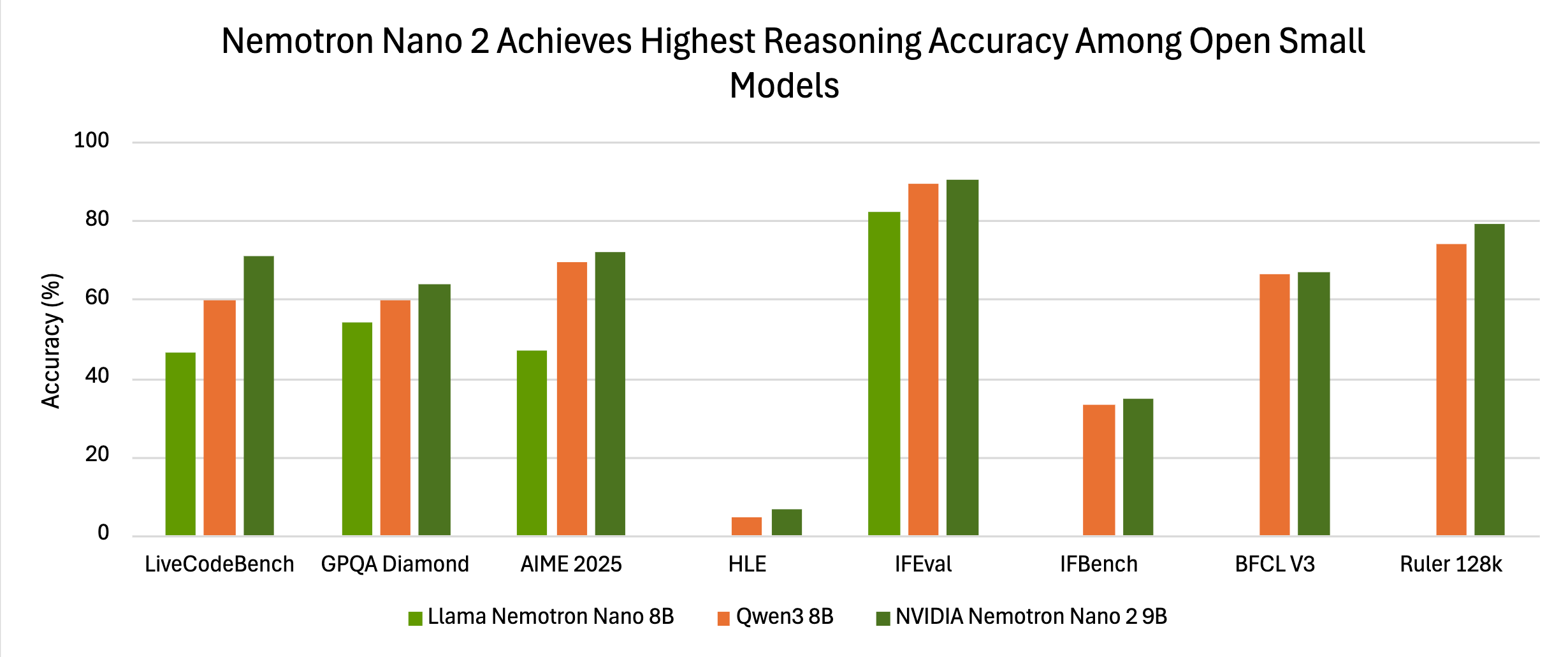
If the older generation of models were using known architectures, the Nemotron V2 iteration was built from the ground up, achieving not only higher accuracy compared to similar models in the SLM (Small Language Model) branch, but up to 6-7x times higher throughput on long sequences with reasoning mode active.
The Nano V2 versions, 12B and 9B both feature improvements on:
Architecture: a hybrid Transformer‑Mamba backbone where most layers are Mamba‑2 state‑space modules with a few attention ones.
Thinking budgets: allowing you to control how many reasoning tokens does the model spend.
Context: longer context windows, up to 128K tokens.
Performance: higher inference throughput, especially on long-sequence tasks.
This can be seen in more detail in the following Figure, comparing Nemotron Nano v2 B with Qwen3-8B, across various reasoning benchmarks, and throughput on long input and output sequences. In the figure, to interpret the numbers, the ISL stands for (Input Sequence Long) and OSL stands for (Output Sequence Long).
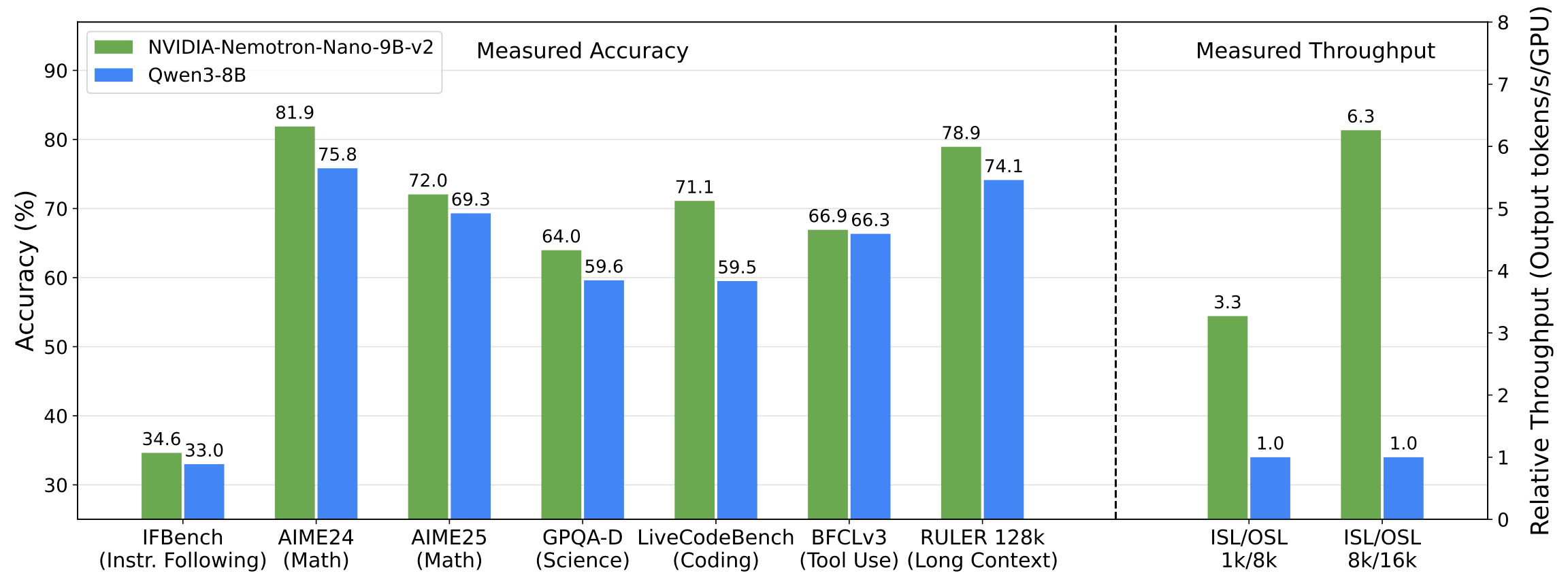
One more important feature that the Nano V2 brings is the ability to control the “Thinking Budget” at runtime. During inference, the user can specify how many tokens the model is allowed to “think”, allowing for controlled flow of Agentic AI tasks, notably if building Deep Research Agents, or Multi-Agent systems that involve step-by-step reasoning.
That considerable jump in inference throughput comes from the Transformer-H Hybrid architecture, which replaces a large chunk of the Attention Layers with Mamba 2 Layers, an interesting concept and an overall newer approach to Transformer models that we’ll unpack in the next section.
The Transformer-H Architecture and Mamba-2 Layers
The original Transformer architecture is built around self-attention plus feed-forward sub-layers, which has been the backbone of nearly all current large language models.
Because of the attention mechanism, each token can incorporate information from any other token in the sequence, as when we compute attention scores, we have a large MatMul between Queries, Keys, and Values that gives very good in-context learning, as each token “looks” at each other token.
But the attention mechanism has quadratic cost O(n²) in vanilla form, and the KV-cache in decoding can grow large. Although there are multiple methods to compute attention, as we’ll see in the following Figure, the MxN matrix will still grow with each token being added to the sequence.
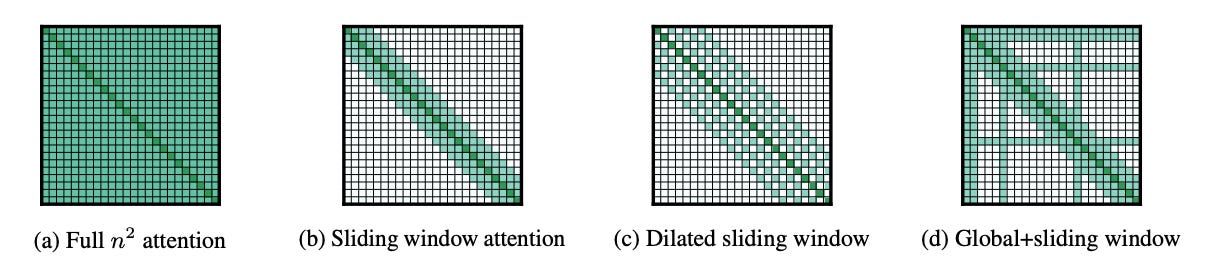
The Mamba-2 layers introduce a different approach to this problem by keeping an internal hidden state that evolves, driven by the tokens added to the sequence instead of maintaining full attention between all tokens.
The original Mamba, introduced in “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,” demonstrated that State Space Models (SSMs) can compete with Transformers while scaling much more efficiently due to their linear computation cost.
However, transformers are better at tasks requiring precise recall of specific input elements, a capability that SSMs can struggle with because their compressed state is fixed and may lose details.
A great in-depth article on how Mamba and SSM work was written by Maarten Grootendorst in his Exploring Language Models Newsletter. Below is an attached animation from that article.
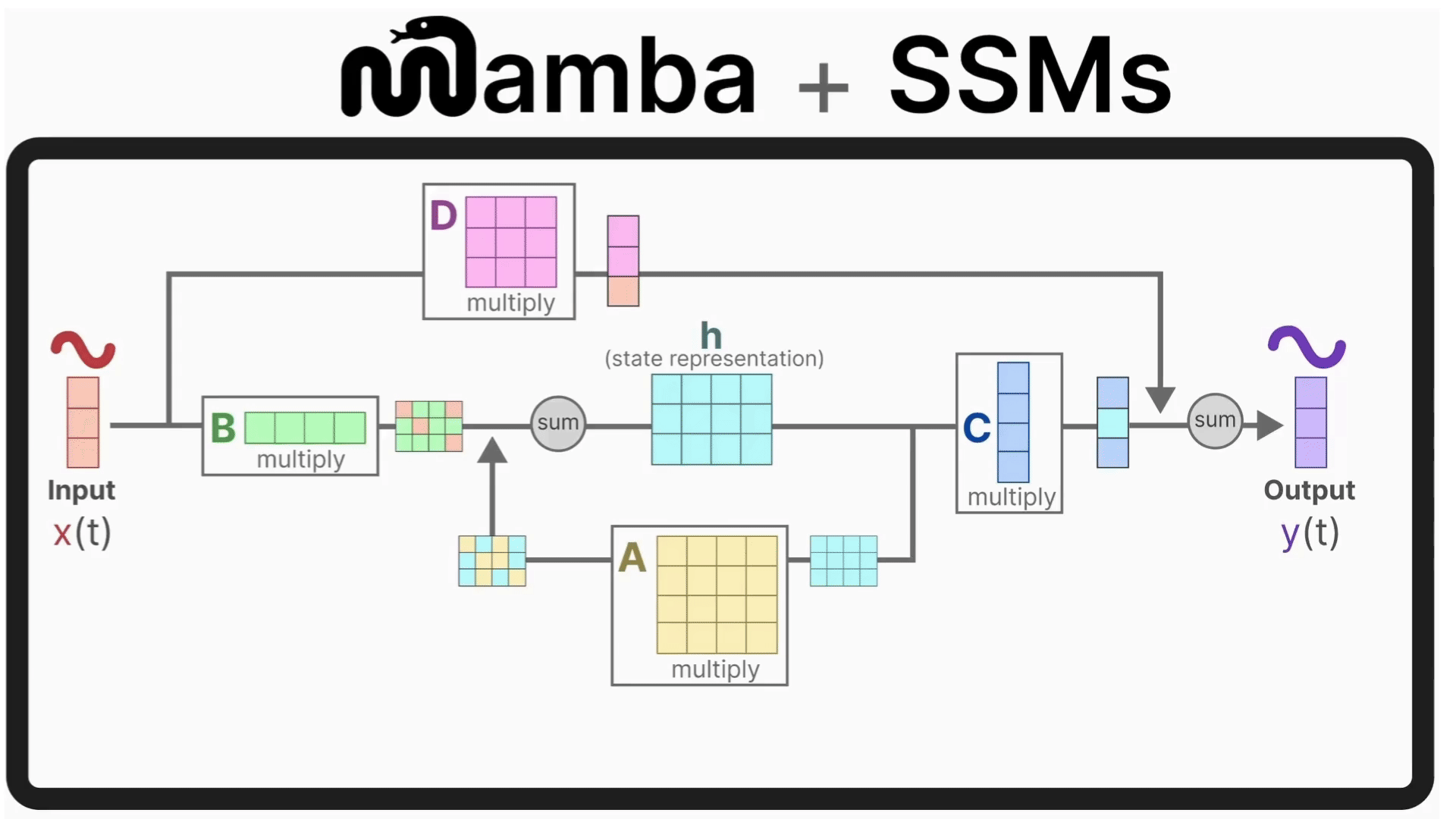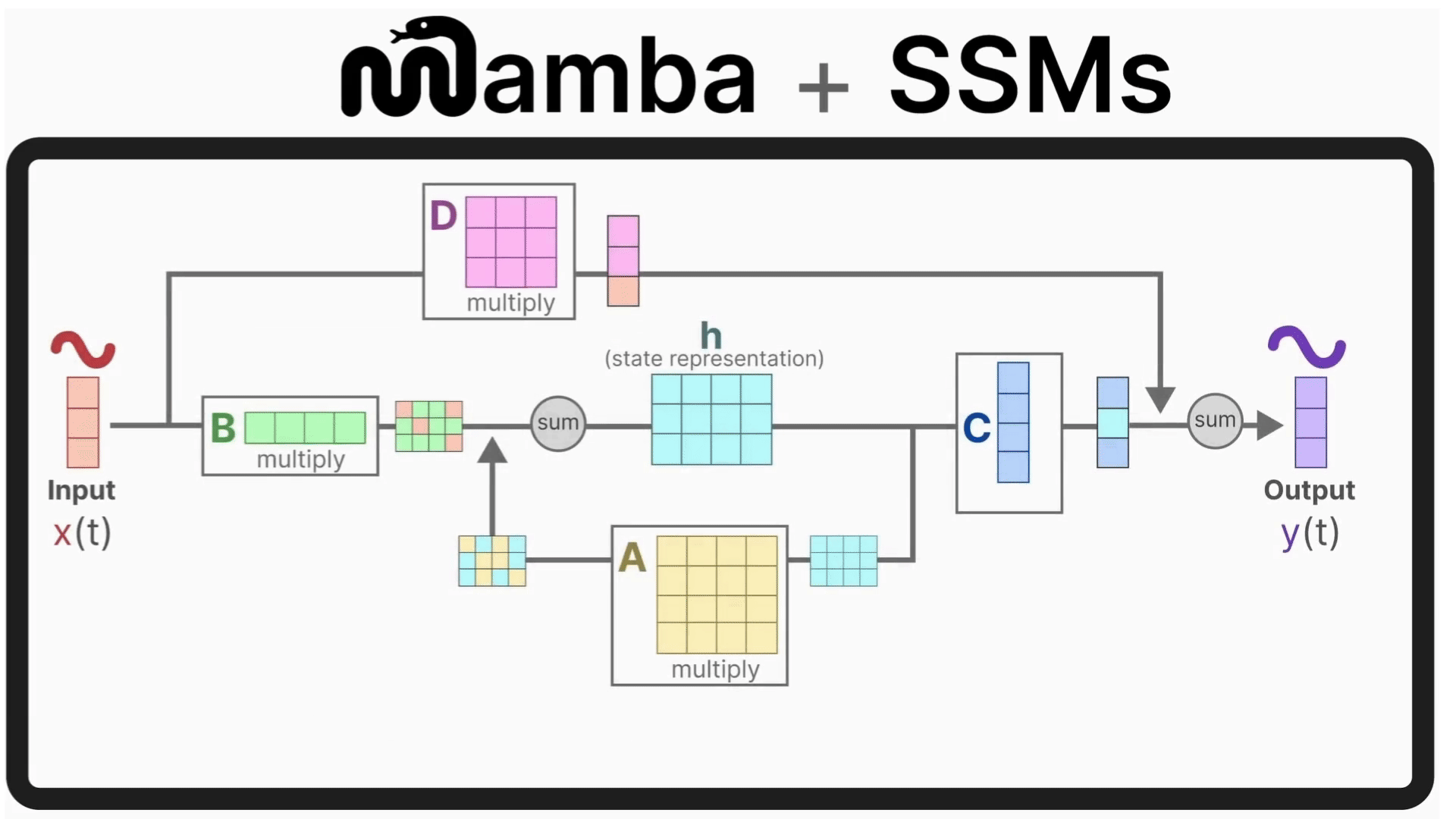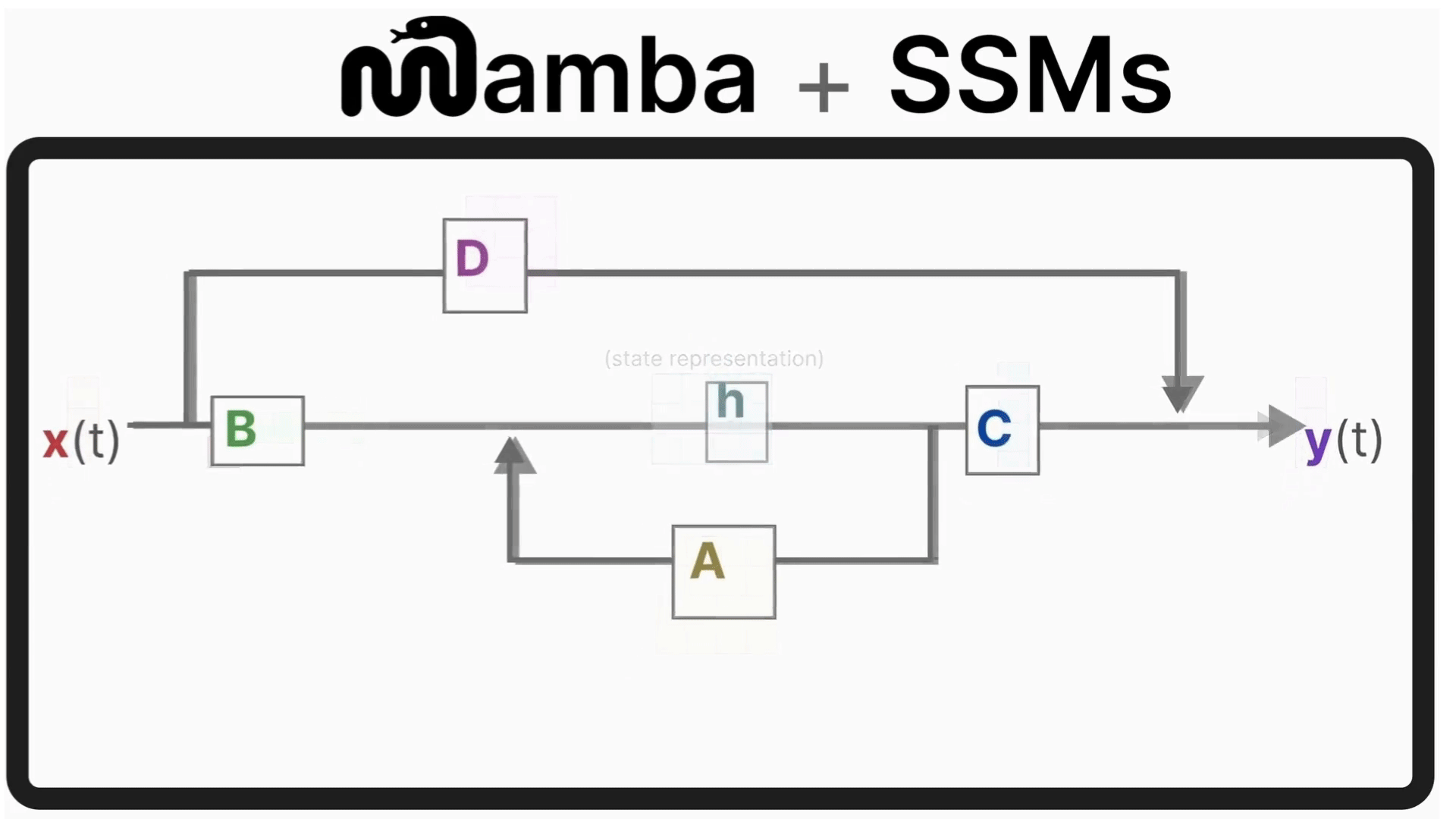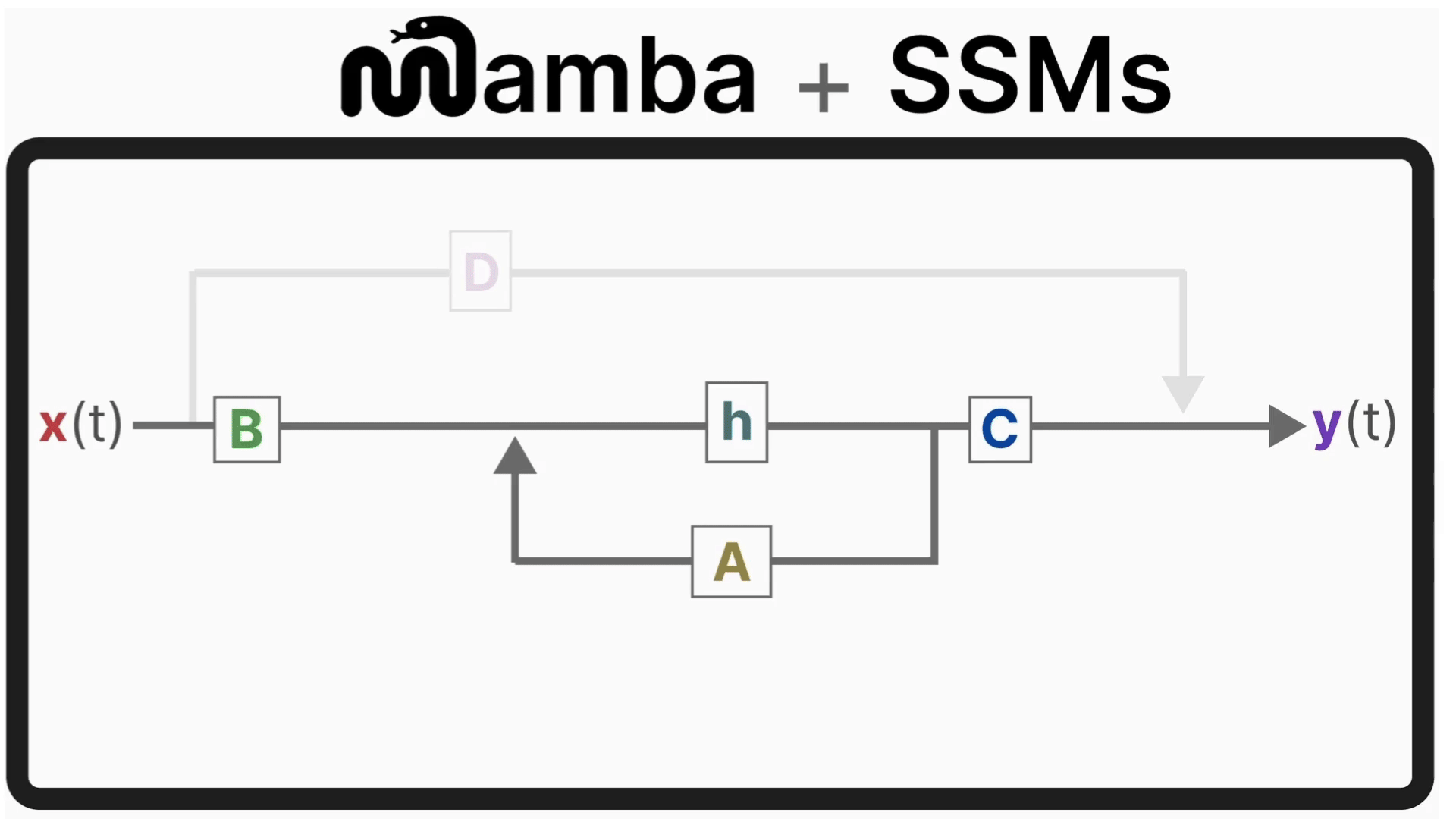
Mamba-2 extends this idea using a theoretical framework called State Space Duality (SSD), which combines the two based on the deep connections between attention mechanisms and SSMs.
The Mamba-2 layer acts as a state-space operator:
It maintains a continuous hidden state;
Updates this state token-by-token using learned transition dynamics;
Produces outputs that capture long-range dependencies without needing explicit attention maps.
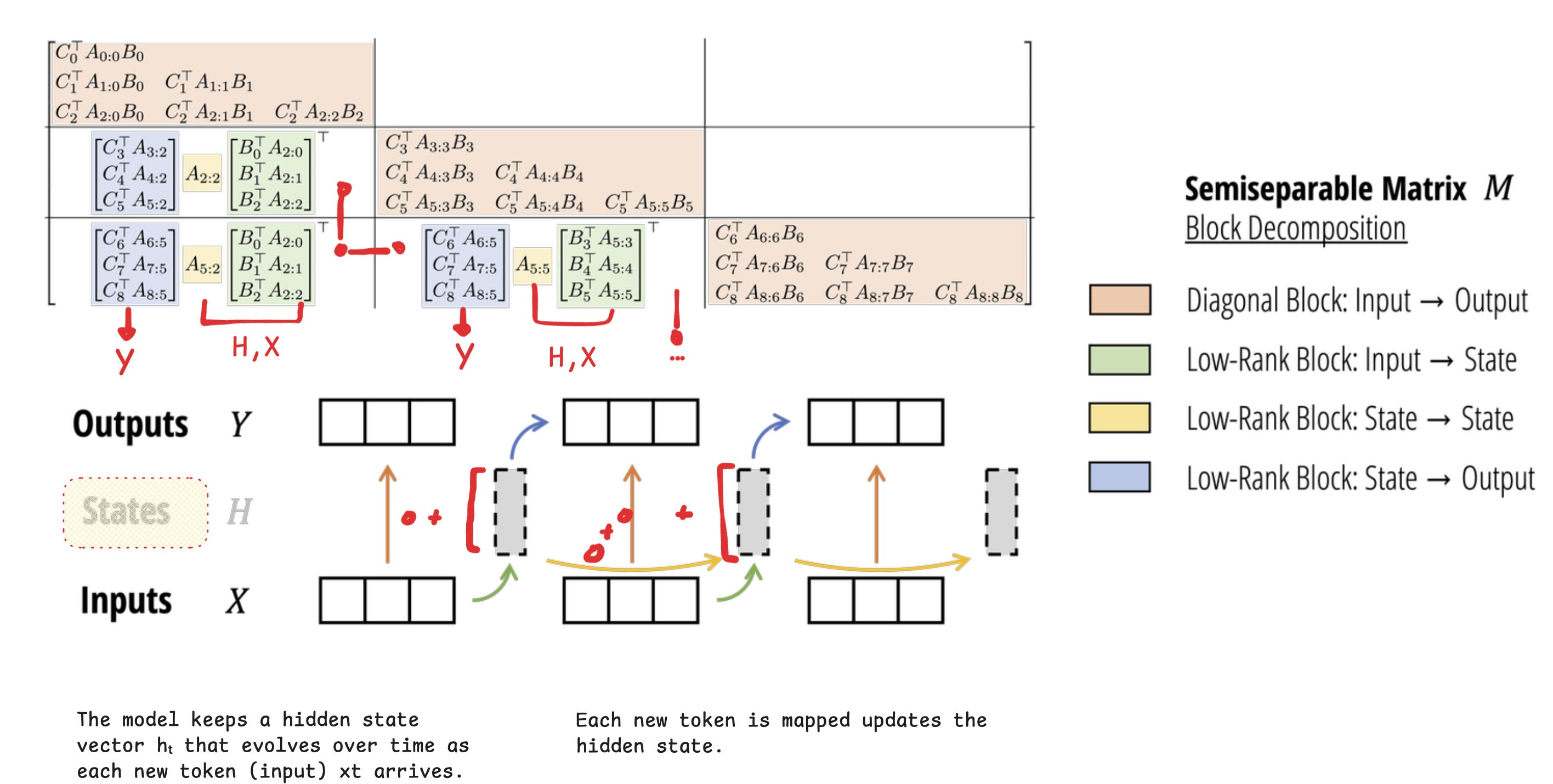
At each step, the new state = a scaled version of the previous state plus the new input. In Mamba-2, this SSM idea is refined into the Structured State Space Duality (SSD) layer, a design that shows SSMs and attention are mathematically linked.
The SSD layer can run in two ways (thus the Duality)
- A linear, recurrent mode (inference)
- A matrix-based “attention” mode (efficient for training).
The Nemotron Nano V2 Architecture
To dive a bit more into the architecture details, this model combines Mamba-2 Layers with Attention and FFN layers, trimming most of the Attention layers, and replacing them with Mamba-2 Layers.
As presented in the “NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model” research paper, if we extract the Model Architecture, we can see the exact configuration of layers being used.

Specifically, in the Nano V2 architecture, there are 62 total layers, with 28/28 split between FFN and Mamba Layers and 6 Attention Layers. That is described in the paper directly, in the Model Architecture section, where I’ve outlined them with yellow.

We can’t completely remove Attention layers, as they provide global context, something that Mamba-2 layers could be struggling as the longer a sequence grows, the hidden state update might loose information, as each new token added to the sequence updates the new hidden state.
The Reason for doing that is that Attention layers provide global context, whereas Mamba-2 layers handle state transitions more cheaply than full attention, which largely increases the throughput of the model during inference.
If we inspect the Nano v2 architecture using the HuggingFace Safetensors Explorer, we notice the exact details mentioned above. In this next Safetensors view, we look directly at the tensors structure and how they’re mapped by the HuggingFace Transformers Library when composing the model and loading it’s weights.
We see 62 layers, but notice the `mixer` component in the layer’s name as this is something specific to Mamba-2 layers:
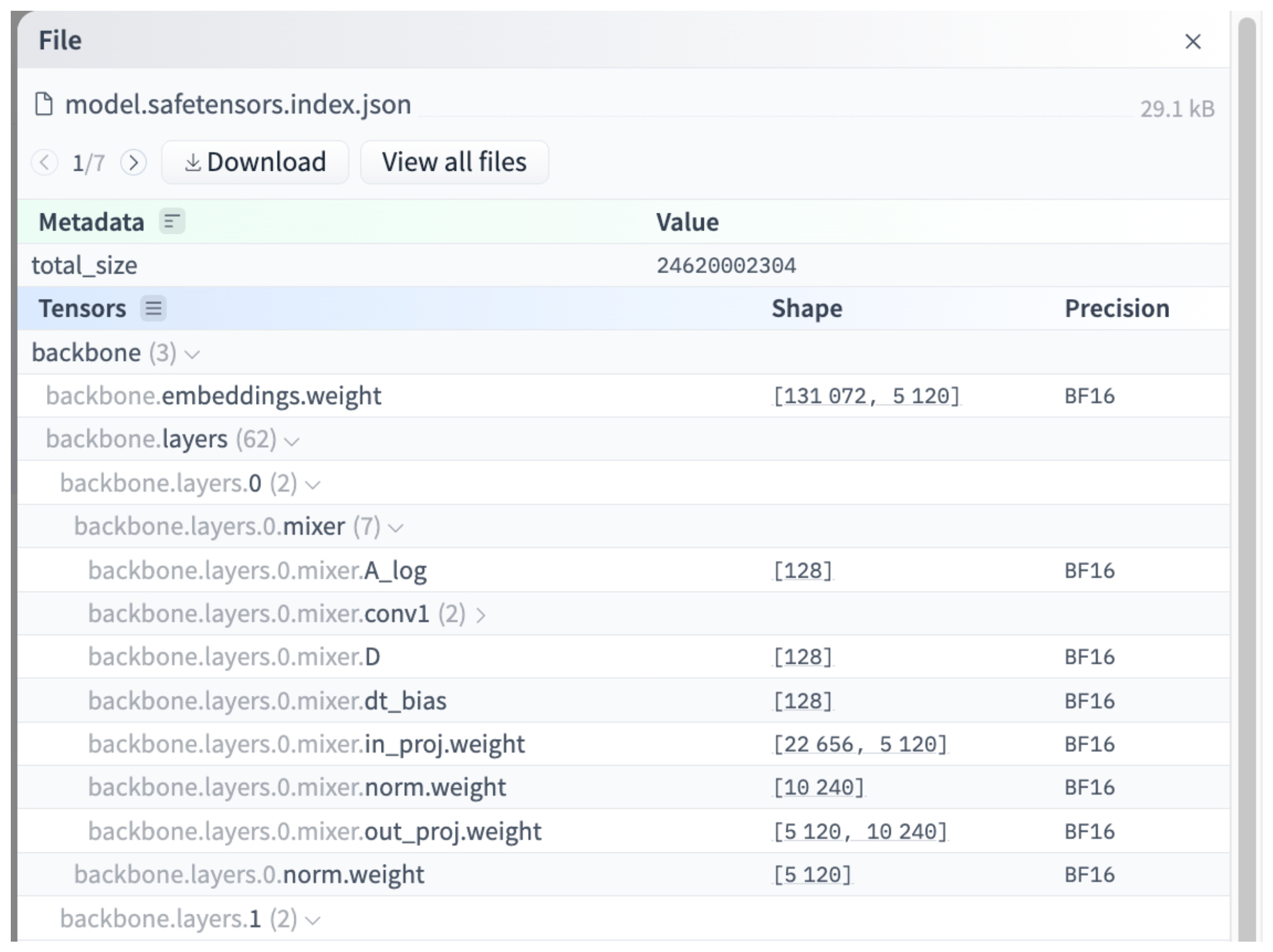
In the context of Mamba / Mamba-2, the “mixer” refers to the module that processes the token sequence dimension via SSM mechanisms rather than (or alongside) standard attention. In practice, the difference between Attention and using SSM is better noticed at inference time.
Comparing Attention with Mamba-SSM
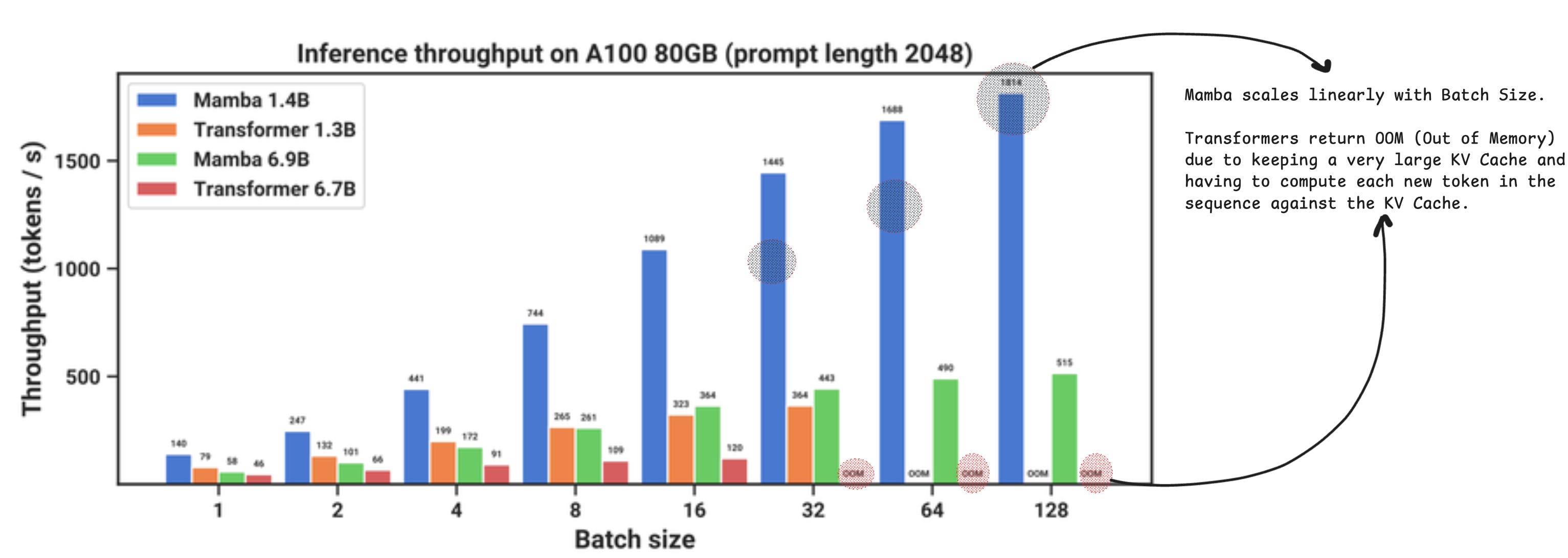
Because Mamba keeps an internal state, the throughput scales linearly with the sequence length, as each new token in the sequence acts as a signal to update the hidden state.
For transformers, that token is added to the MxN Attention Matrix, and its attention score is computed w.r.t all the other tokens in the sequence.
The underlying result is that once the sequence grows, Attention will yield OOM Errors, whereas Mamba scales linearly.
Getting Started with the Nemotron Nano V2
As a hands-on approach, let’s try to serve Nemotron Nano V2 model and then build a client in Python, to try out the Thinking Budgets approach that these models introduce.
As with any model on HuggingFace, you can use and test it directly with the Transformers library plug-and-play.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(”nvidia/NVIDIA-Nemotron-Nano-9B-v2”)
model = AutoModelForCausalLM.from_pretrained(
“nvidia/NVIDIA-Nemotron-Nano-9B-v2”,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=”auto”
)
messages = [
{”role”: “system”, “content”: “/think”},
{”role”: “user”, “content”: “Tell me a story about Mamba-2”},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors=”pt”
).to(model.device)
outputs = model.generate(
tokenized_chat,
max_new_tokens=32,
eos_token_id=tokenizer.eos_token_id
)
print(tokenizer.decode(outputs[0]))The model, in BF16 Precision would require 12-16GB VRAM if you’re planning to load and run it on a GPU.
This call will parse the repository, load the tokenizer, and unpack the Safetensors checkpoint shards, loading them into memory and constructing the Model Graph, which is composed of Tensor Types, Precision Types, Layers etc.
This process of parsing a model, loading the weights, and preparing the Model Graph is the same in all Inference Engines, from vLLM, TGI, Transformers, llama.cpp and more.
Using Thinking Budget Client with vLLM
With vLLM, you’d start a Server to host the model, and then build a Client in Python that connects to the Server and sends requests.
Starting the Server - you also need to pass `mamba_ssm_cache` as this model uses the Transformer-H Architecture with Mamba-2 layers.
pip install -U “vllm>=0.10.1” vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \ --trust-remote-code \ --max-num-seqs 64 \ --mamba_ssm_cache_dtype float32Build the Client in Python
from typing import Any, Dict, List import openai from transformers import AutoTokenizer class ThinkingBudgetClient: def __init__(self, base_url: str, api_key: str, tok_path: str): self.base_url = base_url self.api_key = api_key self.tokenizer = AutoTokenizer.from_pretrained(tok_path) self.client = openai.OpenAI(self.base_url, self.api_key) def chat_completion( self, model: str, messages: List[Dict[str, Any]], max_thinking_budget: int = 512, max_tokens: int = 1024, **kwargs, ) -> Dict[str, Any]: assert ( max_tokens > max_thinking_budget ), f”thinking budget must be smaller than maximum new tokens. Given {max_tokens=} and {max_thinking_budget=}” # 1. first call chat completion to get reasoning content response = self.client.chat.completions.create( model=model, messages=messages, max_tokens=max_thinking_budget, **kwargs ) content = response.choices[0].message.content reasoning_content = content if not “</think>” in reasoning_content: # reasoning content is too long, closed with a period (.) reasoning_content = f”{reasoning_content}.\n</think>\n\n” reasoning_tokens_len = len( self.tokenizer.encode(reasoning_content, add_special_tokens=False) ) remaining_tokens = max_tokens - reasoning_tokens_len assert ( remaining_tokens > 0 ), f”remaining tokens must be positive. Given {remaining_tokens=}. Increase the max_tokens or lower the max_thinking_budget.” # 2. append reasoning content to messages and call completion messages.append({”role”: “assistant”, “content”: reasoning_content}) prompt = self.tokenizer.apply_chat_template( messages, tokenize=False, continue_final_message=True, ) response = self.client.completions.create( model=model, prompt=prompt, max_tokens=remaining_tokens, **kwargs ) response_data = { “reasoning_content”: reasoning_content.strip().strip(”</think>”).strip(), “content”: response.choices[0].text, “finish_reason”: response.choices[0].finish_reason, } return response_data
Sending the Request - limiting to 32 thinking tokens only.
tok_path = “nvidia/NVIDIA-Nemotron-Nano-9B-v2” client = ThinkingBudgetClient( base_url=”http://localhost:8000/v1”, api_key=”EMPTY”, tok_path=tok_path, ) messages=[ {”role”: “system”, “content”: “You are a helpful assistant. /think”}, {”role”: “user”, “content”: “What is 2+2?”}, ], result = client.chat_completion( model=”nvidia/NVIDIA-Nemotron-Nano-9B-v2”, messages=messages, max_thinking_budget=32, max_tokens=512, temperature=0.6, top_p=0.95, ) print(result)
You should see a response similar to, limited by our max_thinking_budget:
{’reasoning_content’: “Okay, the user asked, What is 2+2? Let me think. Well, 2 plus 2 equals 4.”, ‘content’: ‘2 + 2 equals **4**.\n’, ‘finish_reason’: ‘stop’}Conclusion
In Part I of this mini-series, we’ve started with an overview on the NVIDIA Nemotron Family of Models, Datasets, and Training recipes, covering the improvements that Nemotron Models bring, the datasets and techniques they’ve been trained with and how they rank on popular reasoning benchmarks for Agentic AI tasks.
In short, the Nemotron line of models from NVIDIA is aimed to be small, capable, Agentic AI-ready models that run fast, require low compute, and can be deployed at scale from cloud to Edge.
Also in this article, we’ve covered the most notable architecture improvement, replacing traditional Attention Layers with SSM (State Space Models), notably Mamba-2 layers, and have explained the differences, benefits, and impact this has on Inference Throughput.
In Part II of this series, we’ll cover the Nemotron Nano 2 VL 12B, a model that has the same powers as the Nano 2, but adds the Vision Modality, leading to the OCRBenchv2, a very complex Benchmark on Document Understanding and Multi-Image Reasoning.
Thanks for reading, don’t miss the next article!
References:
[1] NVIDIA. (2025). Nemotron Nano V2 Reasoning Benchmarks. HuggingFace.
https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2
[2] NVIDIA. (2025). Nemotron Nano 2 VL Model Card. HuggingFace.
https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-12B-v2-VL-BF16
[3] Nemotron’s Open Secret: Accelerating AI Development with Open Models, Data, and Recipes. (2025). HuggingFace.co.
https://huggingface.co/blog/nvidia/nemotron-open-models-data
[4] (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. ArXiv.org. https://arxiv.org/abs/2311.12022
[5] NVIDIA Research. (2025). Nemotron Nano 2: Hybrid Mamba-Transformer Architecture.
https://arxiv.org/abs/2508.14444
[6] Gu & Dao. (2024). Mamba: Linear-Time State-Space Models.
https://arxiv.org/abs/2405.21060