
Stop using Python Dataclasses - start using Pydantic Models
Add data schemas and sanity to your data models. See how easily will Pydantic models streamline your data validation and serialization workflows.

With the latest advancements in LLMs, RAGs — new frontiers of data-intensive applications have opened, focusing on ingesting, parsing, contextualizing, and storing as an underline for RAG systems.
When talking about data validations, there is no one-fits-all tool to streamline the whole data parsing and validation workflow — but here’s why using Pydantic to configure and structure your data exchange models might be the way to go.
Table of Contents
1. What is Python Pydantic
2. Advantages
3. Pydantic Attributes
4. Example Workflow
5. Conclusion
What is Python Pydantic
Pydantic is the most widely used data validation library for Python.
It’s a Python package that can offer simple data validation and manipulation. It was developed to improve the data validation process for developers.
As an API for defining and validating data that is flexible and easy to use, and it integrates seamlessly with Python’s data structures.
Developers can specify the Pydantic data validation rules and the data and the library will then automatically validate incoming data and raise errors if any rules are unmet.
Advantages
I first found out about Pydantic when working with FastAPI for Python backend development — and I couldn’t notice all the benefits and key issues it solves when one requires static-typed data models.
The dynamic nature of Python serves as both an advantage and a drawback. On one side, it offers developers the flexibility to mold the code base into any desired form, enabling the creation of innovative abstractions. However, this same flexibility can lead to disorganized code structures, often referred to humorously as code lasagna, code spaghetti, and other varieties of ‘code pasta.’
With the vast amount of data sources and formats, ML/Data Engineers have to pay attention to ensure the structure follows a specific blueprint that is fail-safe when communicating with various services or APIs.
By adding type annotations to your class attributes, you can ensure your inputs are checked right when your program starts
Here’s a list of key points I love about Pydantic:
Type Safety: At its core, Pydantic uses Python’s type hints to validate data. This ensures that your ML models are fed data that are correctly typed, reducing runtime errors.
Easy to Use: Defining a data schema with Pydantic is straightforward and intuitive, making your data validation code easily understandable.
Automatic Data Conversion: It automatically tries to cast types when specifying fields of expected data type.
e.g In this use case,lr(learning rate) is expected to be a float type.
class HypStructure(BaseModel):
lr: float
optimizer_name: str4. Rich Validation Support: Beyond simple type checks, it allows for a wide range of validations, including string lengths, numeric ranges, and even complex custom validations.
5. Custom Validation Logic: One could add custom logic for field validation. In this example, fields needed different validation rules, and having custom cleaning methods targeting specific fields allows for generic parsing maintaining data quality and consistency.
6. Error Reporting: When data validation fails, it provides detailed and clear error reports.
class MLFeatureSet(BaseModel):
age: int = Field(..., gt=0, lt=120)
income: float = Field(..., lt=100)
-------
MLFeatureSet(age=0, income=5000)
-------
2 validation errors for RequestModel
age
ensure this value is greater than 0 (type=value_error.number.not_gt; limit_value=0)
income
ensure this value is lower than 100 (type=value_error.number.not_lt)7. Seamless Serialization and Deserialization: One could easily extend the BaseModels to serialize into any format.
Pydantic Attributes
To fully grasp the power and extensibility of Pydantic, let’s go over the key attributes that you should know about:
BaseModel
A class that defines what your data looks like and the validation requirements it needs to pass to be valid.
from pydantic import BaseModel
class MyNewDataModel(BaseModel):
...2. Field
from pydantic import BaseModel, Field
class ModelParameters(BaseModel):
# The ... (ellipsis) in field, means it is a required field
# If the key is not instantiated, it will yield a validation error
learning_rate: float = Field(..., gt=0.0001, le=1.0)
batch_size: int = Field(gt=0, lt=1024)A function that allows you to add extra information and constraints to model attributes, such as validation, default values, and metadata. This can be extended with datatype , bounds (greater-than, lower-than) , regex and more.
3. Field Validator:
A decorator to define custom validation functions for your model attributes, offering flexibility to implement complex validations that can’t be covered by standard type hints and Field constraints.
from pydantic import BaseModel, field_validator
class DatasetConfig(BaseModel):
dataset_path: str
batch_size: int
@field_validator('batch_size')
def batch_size_must_be_power_of_two(cls, v):
if (v & (v - 1)) == 0 and v != 0:
return v
raise ValueError('batch_size must be a power of 2')The bonus point here is that you can pass multiple fields to the same validator:
from pydantic import BaseModel, field_validator
class DatasetConfig(BaseModel):
dataset_path: str
train_batch_size: int
val_batch_size: int
test_batch_size: int
@field_validator('batch_size', 'val_batch_size', 'test_batch_size')
def batch_size_must_be_power_of_two(cls, v):
if (v & (v - 1)) == 0 and v != 0:
return v
raise ValueError('batch_size must be a power of 2')4. Default Factory
Allows setting dynamic default values for model fields using a callable, useful when defaults need to be generated at runtime (e.g., current time, unique identifiers).
import os
from pydantic import BaseModel, Field
from datetime import datetime
def current_time():
return datetime.now()
def train_experiment_id():
return os.environ.get("LAST_EXPERIMENT_ID")
class TrainingJobMetadata(BaseModel):
start_time: datetime = Field(default_factory=current_time)
exp_id: str = Field(default_factory=train_experiment_id)5. Recursive Models:
Pydantic models can be nested, allowing for complex hierarchical structures that mirror deeply nested JSON, for example.
from pydantic import BaseModel
from typing import List
class TrainingJobRun(BaseModel):
name: str
description: str = None
exp_tracking_runid: str = Field(..., default_factory=lambda: str(uuid4(()))
class PreviousTrainingExperiments(BaseModel):
history: List[TrainingJobRun]6. Aliases:
You can define alternate names for model fields that may not match the Python variable naming conventions, useful when working with data sources that have different naming conventions.
from pydantic import BaseModel, Field
class ExternalData(BaseModel):
external_id: int = Field(..., alias='id')
data_value: str = Field(..., alias='value')7. Custom Data Types:
Pydantic supports creating custom data types with their own validation logic, useful for defining specific data types like Email, URL, or even domain-specific types like ImageURL or ModelName.
from pydantic import BaseModel
def to_uppercase(string: str) -> str:
return string.upper()
class UppercaseStr(str):
@classmethod
def __get_validators__(cls):
yield to_uppercase
class Item(BaseModel):
name: UppercaseStr8. Settings Management:
Beyond data validation, Pydantic can be used to manage application settings, leveraging environment variables and .env files for configuration.
import os
from pydantic_settings import SettingsConfigDict, BaseSettings
# Get the root path such that we can use it to load the .env file
dir_path = os.path.dirname(os.path.realpath(__file__))
class Settings(BaseSettings):
model_config = SettingsConfigDict(
env_file=os.path.join(dir_path, "..", "../.env"), env_file_encoding="utf-8"
)
# These will be available via settings as default values
EU_BLOB_NAME: str = "myeublob"
# These will be inherited from the .env file
EU_BLOB_STORAGE_CONNECTION_STRING: str
US_BLOB_STORAGE_CONNECTION_STRING: str
settings = Settings()Example Workflows
There have been multiple instances where I’ve had pipelines raise exceptions or crash silently due to edge cases when parsing payloads.
I used to do these validations poorly and repetitively until I started to use Pydantic.
Here’s an example of using Pydantic in one of my projects, where the aim was to streamline a common structure between multiple news article payload formats.
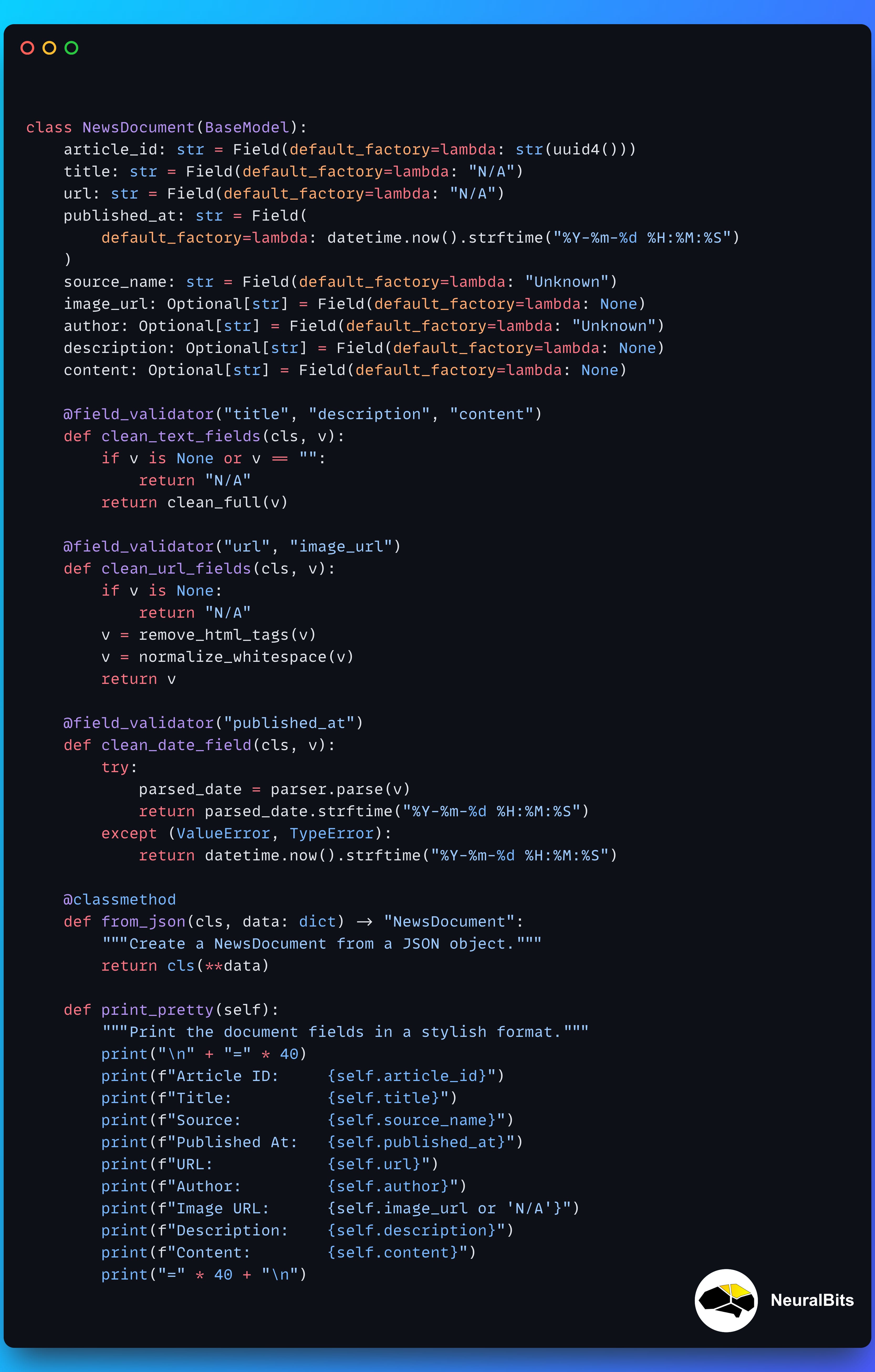
Let’s unpack it:
Using default_factory to assign a value when not available.
Using custom text cleaning methods on key fields title, description and content
Using custom data validation logic for published_at field.
Using a serializer method from_json to instantiate this model directly from JSON.
Custom URL cleaner methods for URL and image_url fields.
And to outline an example:
# app/core/models.py
from core.models import NewsDocument
dummy data = {
"title": "Python data validation with Pydantic",
"url": "https://example.com/article/1",
"published_at": "2024-09-17 12:30:00",
"source_name": "Sample text",
"description": "This is a breaking news article.",
"content": "Full content of the article goes here."
}
news_doc = NewsDocument.from_json(dummy_data)
news_doc.print_pretty()
--- Result ---
========================================
Article ID: 2c2006b3-c112-4f79-a62c-fcc41df2e855
Title: Breaking News
Source: Example News
Published At: 2024-09-17 12:30:00
URL: https://example.com/article/1
Author: Unknown
Image URL: N/A
Description: This is a breaking news article.
Content: Full content of the article goes here.
========================================This is just a small glimpse of what can be done with Pydantic.
In my case, by using Pydantic models for each payload, I was able to streamline the article ingestion from various News APIs, which come in different formats and field names, to a common NewsArticle document that was further serialized and pushed to a serverless Kafka Cluster.
The payloads from Kafka were further consumed by another service which computed embeddings and stored vectors in a Vector Database.
Here’s an example of a fetched entry from the Vector Database, via vector retrieval:
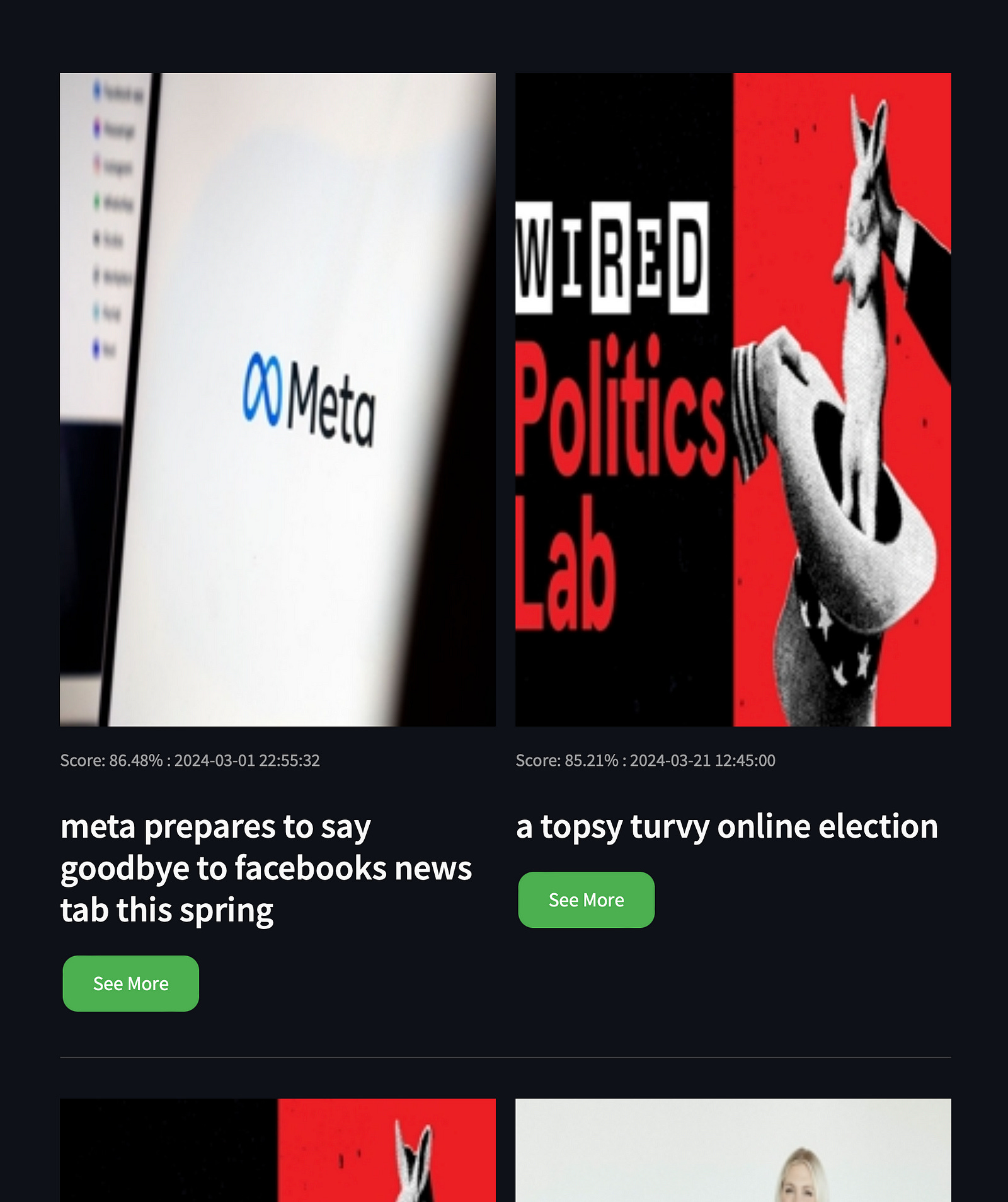
Notice that each card in this UI has a valid Image, Title and PublishedDate . All these fields were stored separately, in the metadata body attached to the actual vector embeddings.
In this context, accurate field validation and standard formatting are key because you wouldn’t want None values or dummy text characters \n, \t, !, ?, <> as part of the fields that are not directly used for embedding context but are still key for the UI representation or retrieval process.
Since you cannot oversee and debug each payload in part, you’ll have to engineer accurate logic to clean and validate each one — and here’s where Pydantic Models shine.
Conclusion
Congrats!
In this article, we went over Pydantic's best practices, advantages, and workflows of when it’s best to use it. Many engineers sleep on Pydantic and continue to validate or exchange data through custom data classes with complex logic or formats like JSON, YAML, and MD.
As a Machine Learning Engineer, I used to implement custom logic in different Python scripts, either as part of a Class or using Dataclasses to ensure my data models were valid and believe me the codebase grew rapidly and I had to document it throughout.
Switching to Pydantic — solved that for me and my team!