

6 advanced concepts to use with FastAPI & Pydantic
Understand how and when to use lifespan to load ML Models, state management, dependency injection and pydantic settings.

Reading this article, you’ll learn about:
Global state management in FastAPI
When to use dependency injection with Depends()
How to group environment configurations
PydanticSettings advanced concepts
Pre-build validations for DSNs in Pydantic
Advanced tips on using Pydantic
Working with Python, most probably you’ve heard about FastAPI for building web applications. Let’s use FastAPI first and build our understanding of what Pydantic is and its powers.
As an AI/ML Engineer, you have definitely worked on deploying a customer/user-facing model. User-facing AI workloads in production usually end up in one of these categories:
Serving via APIs, the simplest and most relevant example to AI Engineering is the OpenAI API Schema that the majority of LLM providers use as a standard, with endpoints such as `/response` or `/chat/completions`.
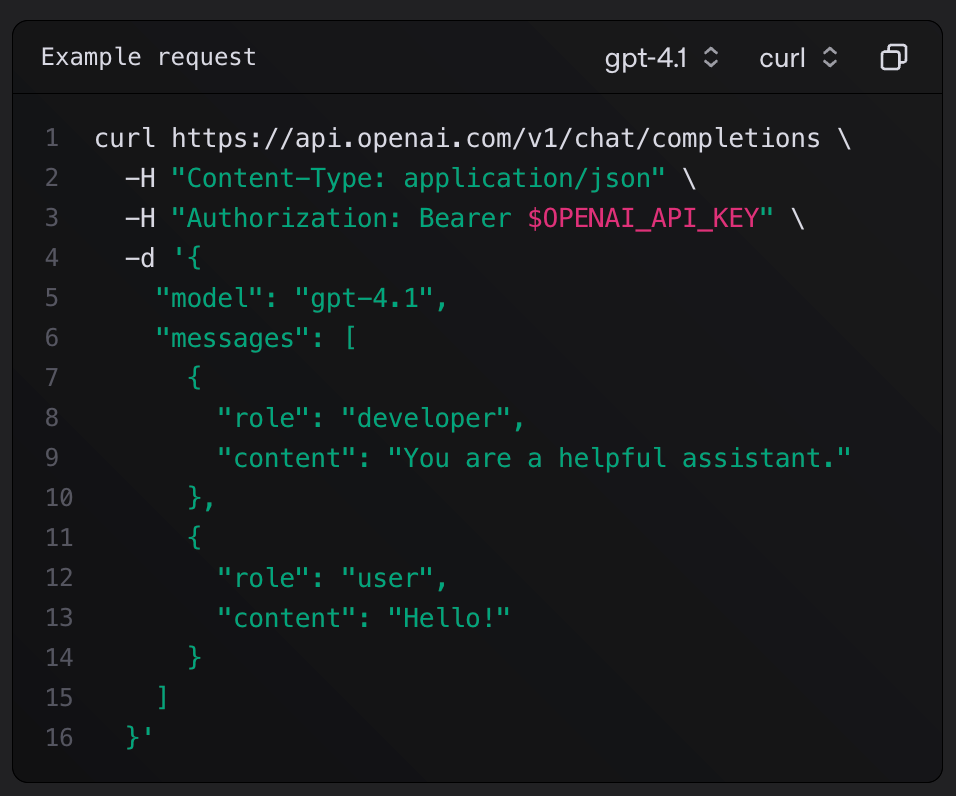
OpenAI API specification for the /chat/completions endpoint. Screenshot from OAI API Schema. Serving at the Edge, where AI workloads are processing data close to the source and then push results to event-listener streams.
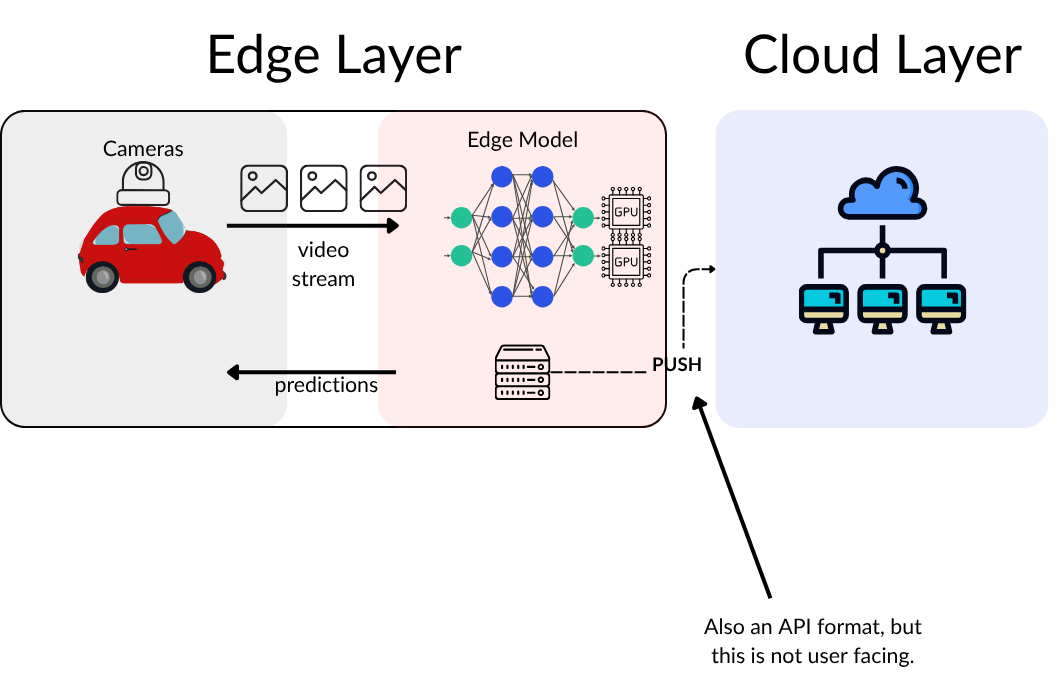
Batch Deployment
Models run inference on large batches of data offline or on a schedule rather than in real time.Streaming Deployment
Models are embedded in streaming data pipelines to perform near-real-time inference on continuous data flows.
The popular one is the first, serving via APIs.
Working mainly with Python, AI Engineers will often choose FastAPI as their web framework to build an API and serve their models. This is true both for simple wrapper solutions, which offload the processing to an LLM Provider API, or for custom ones, where the AI Engineer would fine-tune and optimize a model and then serve it with an inference engine such as vLLM, SGLang, TGI, or TensorRT LLM.
Underneath, FastAPI builds on top of Starlette, which is a lightweight ASGI framework/toolkit, ideal for building async web services, and brings in the power of Pydantic's baked-in data validation features.
Within FastAPI, one could define environment settings, request/response schemas, and data validation workflows fully throughout Pydantic Models.
Now that we’ve come full circle, let’s showcase a few good practices and advanced tips on using Pydantic in any of your Python applications.
1. Better serialization of ConnectionStrings
The first one on the list is serializing connection strings. If you’re like me, before finding out about this Pydantic trick, I used to do this:
# .env
MONGO_CONN = mongodb+srv://user:pwd@cluster0.mongodb.net/some_dbAnd then in Python, I would do this:
import os
import dotenv
import pymongo
dotenv.load_dotenv()
client = pymongo.MongoClient(os.getenv("MONGO_CONN"))This works, but it’s unsafe because if MONGO_CONN is badly formatted, it’ll fail when trying to instantiate the MongoClient, although it should fail before that, when loading the MONGO_CONN string.
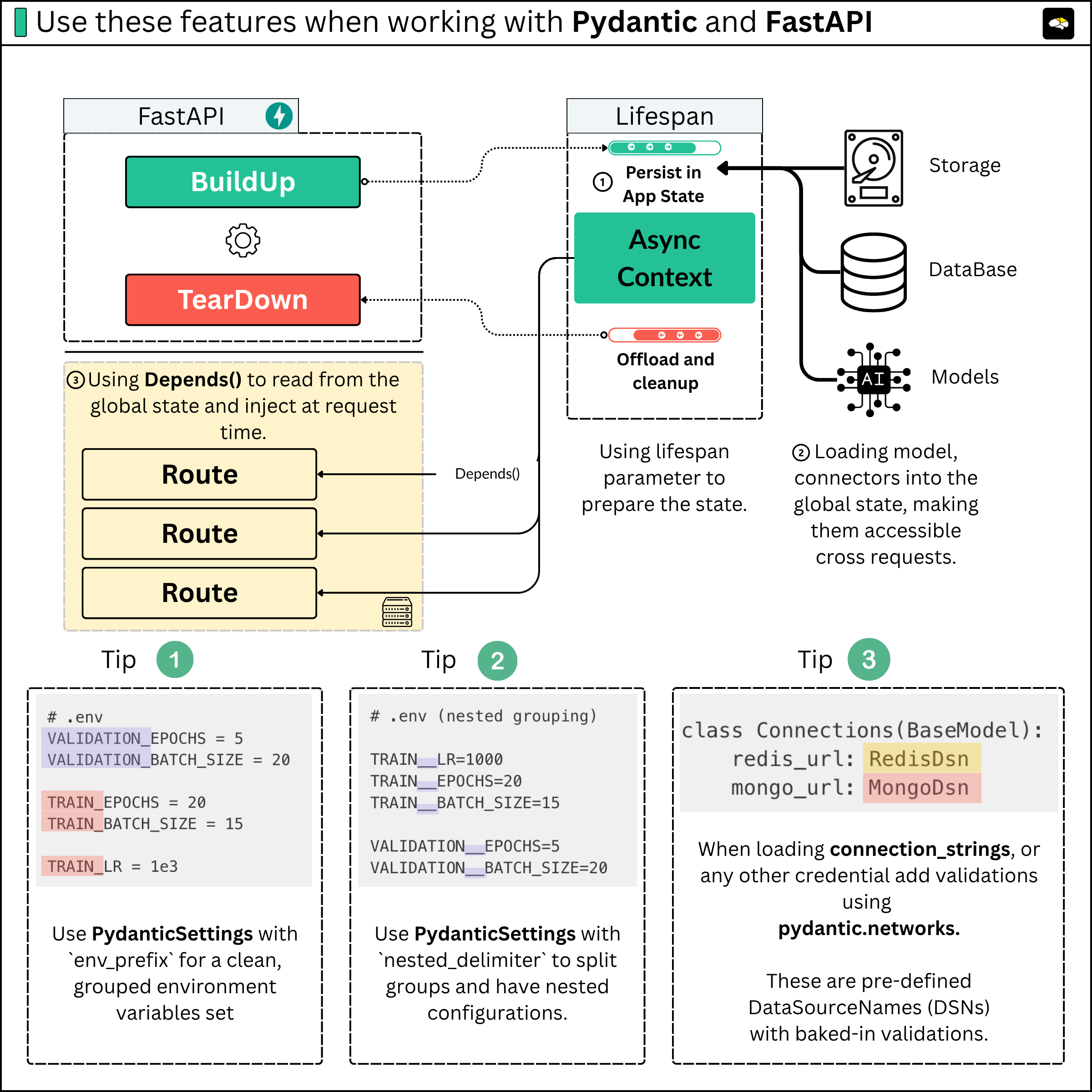
With Pydantic, we could fix that fairly quickly using network_types Data Source Names (DSNs).
from pydantic import BaseModel
from pydantic.networks import MongoDsn, RedisDsn
class Connections(BaseModel):
redis_url: RedisDsn
mongo_url: MongoDsn
settings = ConnectionSettings(
redis_url="redis://localhost:6379/0",
mongo_url="mongodb://user:pass@localhost:27017/db"
)With this, whenever a URL doesn’t follow the specific schema, it’ll raise a Validation Error:
pydantic_core._pydantic_core.ValidationError: 1 validation error for ConnectionSettings
redis_url
Input should be a valid URL, invalid port number [type=url_parsing, input_value='redis://xxx:xxx/0', input_type=str]2. Better management of your app Environment
Environment variables are key to every application. In Python, you might’ve loaded them using the dotenv package, but Pydantic Settings does a better job, allowing for extensibility and runtime validation. Let’s see how:
Prefixing and Grouping
By overriding the model_config, we can specify an `env_prefix` which, when loading the Env variables, will filter and serialize only the ones that have the prefix.
from pydantic import Field
from pydantic_settings import BaseSettings, SettingsConfigDict
class SFTTrainerSettings(BaseSettings):
model_config = SettingsConfigDict(env_prefix='TRAIN_')
lr: float = Field(..., description="Learning Rate")
batch_size: int = Field(default=8)
epochs: int = Field(..., description="Number of epochs")
settings = SFTTrainerSettings()For example, if in our .env file we have:
# .env
VALIDATION_EPOCHS = 5
VALIDATION_BATCH_SIZE = 20
TRAIN_EPOCHS = 20
TRAIN_BATCH_SIZE = 15
TRAIN_LR = 1e3The SFTTrainerSettings class will serialize only the ones with TRAIN_, and the rest will still be preset in os.environ, but not accessible through our class instance.
Grouping and Nesting
In the example above, we’ve discussed the prefix argument, but we could also have nested settings groups via delimiters. Let’s split the Train and Validation settings into their specific groups, while keeping all variables in .env.
# .env (nested grouping)
TRAIN__LR=1000
TRAIN__EPOCHS=20
TRAIN__BATCH_SIZE=15
VALIDATION__EPOCHS=5
VALIDATION__BATCH_SIZE=20from pydantic import Field
from pydantic_settings import BaseSettings, SettingsConfigDict
class SFTTrainerSettings(BaseSettings):
lr: float = Field(..., description="Learning Rate")
batch_size: int = Field(default=8)
epochs: int = Field(..., description="Number of epochs")
class ValidationSettings(BaseSettings):
epochs: int = Field(..., description="Validation epochs")
batch_size: int = Field(..., description="Validation batch size")
class Settings(BaseSettings):
model_config = SettingsConfigDict(
nested_delimiter="__",
env_file=".env",
case_sensitive=False,
)
train: SFTTrainerSettings
validation: ValidationSettings
settings = Settings()Now, via the `settings` object, we will be able to access these groups separately. This feature of Pydantic saved me a lot of time and brought structure to my code. I strongly recommend you use it.
3. Serialization Aliases
This example works best if you think about this use case.
Let’s say you have a frontend React+TypeScript app that sends data using camelCase keys, like userId and userPrompt. In your backend FastAPI service, you used snake_case throughout the code. So, you’d have to map userId, userPrompt like user_id and user_prompt for readability and Python conventions.
Moreover, let’s say you want to store some data in MongoDB and you want to keep the original camelCase keys (userId, userPrompt to maintain consistency with other systems or frontend expectations.
With Pydantic, you could simply use the serialization_alias that’ll handle all this internally within the BaseModel.
from pydantic import BaseModel, Field
from pydantic import ConfigDict
class ChatSessionPayload(BaseModel):
user_id: str = Field(..., serialization_alias="userId")
user_prompt: str = Field(..., serialization_alias="userPrompt")
model_config = ConfigDict(populate_by_name=True)
from_react = {
"userId": "user_a2c91",
"userPrompt": "Hello, how are you?"
}
# Validate the Input
payload = ChatSessionPayload.model_validate(from_react)
print(f"user_id: {payload.user_id}")
print(f"user_prompt: {payload.user_prompt}")
# Serialize to Mongo
document = payload.model_dump(by_alias=True)
collection.insert_one(
mongo_collection="user_sessions",
doc=document)Here, we get the raw input with `userId`, `userPrompt`, we serialize it in the BaseModel, and can use it with `user_id` or `user_prompt`. Next, we can dump the model, passing the `by_alias` flag, and we’ll get the raw model back.
Now that we’ve covered Pydantic, let’s jump to 2 expert insights on using FastAPI that’ll make your code cleaner and more robust.
Managing FastAPI State
When building APIs for AI workloads, you need to persist key resources. For example, if you serve a large language model (LLM) using Ollama or vLLM on an on-prem server and wrap it with an API, the connection object to the Ollama server must persist across all requests. You don’t want to create a new connection for every request.
The same applies to third-party integrations like vector databases or cloud storage—you want to maintain persistent connections rather than reconnecting each time.
The FastAPI Lifespan Parameter
FastAPI offers a lifespan parameter when creating your app, letting you define startup and shutdown logic.
In the older versions of FastAPI, these were defined using the on_event decorator, which became Deprecated.
@app.on_event("startup")
async def start()
--- your logic ---
@app.on_event("shutdown")
async def stop()
--- your logic ---The current approach in newer versions is to use the `@asynccontextmanager` as a decorator to the lifespan method, to handle the build-up and tear-down context of the running app.
Within the lifespan context, we could establish and store connections or load models once, saving them in FastAPI’s global state. This state is then accessible throughout the app’s lifetime and across all requests.
Startup code runs once before the app starts handling requests, and shutdown code runs once when the app is closing, ensuring proper resource cleanup after serving many requests. This approach optimizes performance and resource management for AI-powered APIs.
The Global Application State
Coupling lifespan with the global application state, we could do something similar to this, where we instantiate an LLM client to communicate with our served LLM model via vLLM.
from fastapi import FastAPI
from contextlib import asynccontextmanager
from vllm import LLM
@asynccontextmanager
async def lifespan(app: FastAPI):
llm = LLM(model="microsoft/phi-3")
app.state.llm = llm
yield
# <logic for teardown>
app = FastAPI(lifespan=lifespan)Next, on an incoming request on a route we’ve defined, we could access the application state and use our LLM client, accessing it directly from the state:
@app.post("/generate")
async def generate(request: Request, prompt: str):
llm = request.app.state.llm
outputs = llm.generate([prompt], max_tokens=100)
text = outputs.outputs.text
return {"completion": text}Although this works, we could go one step further and use Dependency Injection to isolate the state access outside our route methods.
Using request-time Dependencies
Apart from the application state explained above, in FastAPI, we could use dependency injection via Depends(), which takes a callable as input. This allows for cleaner, more testable, and modular code.
During development, we might want to mock or substitute different objects loaded in the Application state, and we don’t want to modify the code that processes our route request, but rather inject the required state into the request and handle the logic elsewhere.
from fastapi import FastAPI, Depends, Request
from contextlib import asynccontextmanager
from vllm import LLM
@asynccontextmanager
async def lifespan(app: FastAPI):
llm = LLM(model="microsoft/phi-2")
app.state.llm = llm
yield
app = FastAPI(lifespan=lifespan)
def get_llm(request: Request) -> LLM:
return request.app.state.llm
@app.post("/generate")
async def generate(prompt: str, llm: LLM = Depends(get_llm)):
outputs = llm.generate([prompt], max_tokens=100)
text = outputs.outputs.text
return {"completion": text}Same functionality, but with this one, we don’t access the app state in the generate() method like we did before. Rather, we define a custom get_llm(request) method that handles the dependency and injects it.
These two tips will help you better structure your FastAPI code, keeping it cleaner and modular.
Conclusion
Summarizing the techniques discussed in this article, we’ve covered the difference and advantages of using the lifespan method when starting our FastAPI application, and efficient ways to manage the global application state, both using `app.state` directly or using Dependency Injection at the request time with `Depends()` method.
Next, we’ve covered 3 tips on how to use Pydantic Settings efficiently to group, parse complex Environment configurations, with prefixed variables and the `env_prefix` flag, and nested variables configurations with the `nested_delimiter`parameter.
As part of the job of AI/ML engineers is deploying their AI models, the topics discussed in this article provide you with good practices around state management and parsing environment setups, maintaining a clean codebase, and a strict separation of concerns.
Stay Updated

Follow Neural Bits on: GitHub | LinkedIn | YouTube
References
Models - Pydantic. (n.d.). https://docs.pydantic.dev/latest/concepts/models/#nested-models
Lifespan events - FastAPI. (n.d.). https://fastapi.tiangolo.com/advanced/events/
Starlette. (n.d.). https://www.starlette.io/
Settings Management - Pydantic. (n.d.). https://docs.pydantic.dev/latest/concepts/pydantic_settings/
Pydantic Settings - Pydantic. (n.d.). https://docs.pydantic.dev/latest/api/pydantic_settings/#pydantic_settings.BaseSettings
All images are created by the author unless otherwise noted.
Amazing ❤️
That's some really good points. I'll use these now. Thanks for introducing settings things, I was totally unaware.