



Python flexibility and C++ performance in one language — Mojo
The new Mojo Programming Language. LLVM and MLIR as core compiler frameworks. How to test Llama 2 in pure Mojo.

Abstract
In this article, we’ll cover Mojo [1], the new programming language for AI workloads.
This article doesn’t aim to sell you on Mojo, but it will give you an overview on it so you could decide if it deserves your attention now or in the future.
We’ll describe the core principles of Mojo and also cover the underlying Compiler Frameworks, LLVM [2], and MLIR [3] which power Tensorflow, Rust, JAX, Julia, Numba, and more.
We’ll also talk about why Mojo is considered a super-set of Python, and compare it against Python on a Matrix Multiplication benchmark, that yields up to 15.000x speed-up in GFLOPs.
Bonus: For the hands-on part, we’ll also run Llama2 in pure Mojo implementation.

Table of contents
1. The Mojo Programming Language
2. Previous alternatives to speeding-up Python
3. LLVM and MLIR Compiler Frameworks
4. Key Principles of Mojo
5. Installing Mojo on Linux/Mac
6. Short overview of Matrix.mojo implementation
7. Benchmarking Python vs Mojo
8. Running LLama 2 in pure MojoThe Mojo Programming Language
Mojo [1] is a programming language within the Python family publicly announced in September 2023.
The main aim of Mojo is to create a language that offers the best of both worlds: the ease of use and readability that Python is known for, along with the speed and low-level control associated with languages like C++ and Rust
The language is developed by Modular Inc, which recently raised 100M $ for their efforts to build a programming language that addresses the high-performance execution runtimes that AI development requires.
The key people behind it are Chris Lattner and Tim Davis. Chris Lattner is the mind behind LLVM and Swift, the programming language that replaced Objective C for Apple, and is used to build applications on iOS and MacOS.
Previous alternatives to speeding-up Python
Mojo isn’t the only effort to address Python’s performance and deployment issues; Julia, Jax, Numba, and Cython are other notable approaches.

Julia [4], for example, offers many advantages similar to Mojo but suffers from a large runtime due to its use of garbage collection and a complex multi-dispatch system.
Jax [5] creates a domain-specific language within Python, translating it into XLA, but inherits Python’s limitations and adds complexity without the benefits of a new language.
Numba [6] and Cython [7] improve performance by compiling Python code to machine code or C, but they are limited in scope, often acting as bandaid solutions rather than complete language solutions.
Unlike the other approaches, Mojo is designed as a complete language that allows developers to write everything — from application servers to model architectures — in one consistent language.
LLVM and MLIR Compiler
LLVM [2], short for Low-Level Virtual Machine, is a robust and flexible framework designed for developing compiler technologies. It provides the building blocks to create both frontends and backends for any programming language or instruction set architecture (ISA).
The LLVM Intermediate Representation (IR) is a key component of the LLVM framework. It’s a type of portable, language-agnostic, high-level assembly language that serves as a bridge between different phases of compilation.

LLVM Backends
Backends are responsible for translating the optimized IR into machine code specific to a target architecture. Here are a few examples:
x86–64: The 64-bit version of the x86 architecture, widely used in modern CPUs.
ARM architecture: A family of RISC architectures used extensively in mobile devices, embedded systems, and more recently on Macbooks starting with the M1 chip version.
NVIDIA PTX (Parallel Thread Execution): A low-level virtual machine and instruction set for parallel computing on NVIDIA’s GPUs. When the NVCC (Cuda Compiler) compiles the code, it transforms it to NVPTX.
AMD RDNA: The architecture that powers the newer AMD GPU models.
LLVM Frontends
Frontends in LLVM convert source code written in a specific programming language into LLVM IR. Here are a few examples:
Clang: for C, C++, and Objective-C. It is one of the most mature and widely used LLVM frontends.
Rustc: The Rust compiler (
rustc) uses LLVM as its backend, benefiting from LLVM’s optimizations and portability.
What is MLIR
MLIR [3] is a sub-project of LLVM and stands for multi-level intermediate representation aiming to unify a software framework for compiler development. Its power is that it can optimally use various computing platforms — GPUs, DPUs, and TPUs, as well as AI ASICs.

Chris initially kicked off the research and development around MLIR while still at Google, that’s why Tensorflow [7] compile modes convert code to low-level MLIR.

The key element of the MLIR is called a ‘MLIR Dialect [8]’, which is a collection of operations and optimizations. For instance, a mathdialect provides everything related to mathematical operations, an amdgpu dialect provides operations that specifically target the AMD GPU processors.

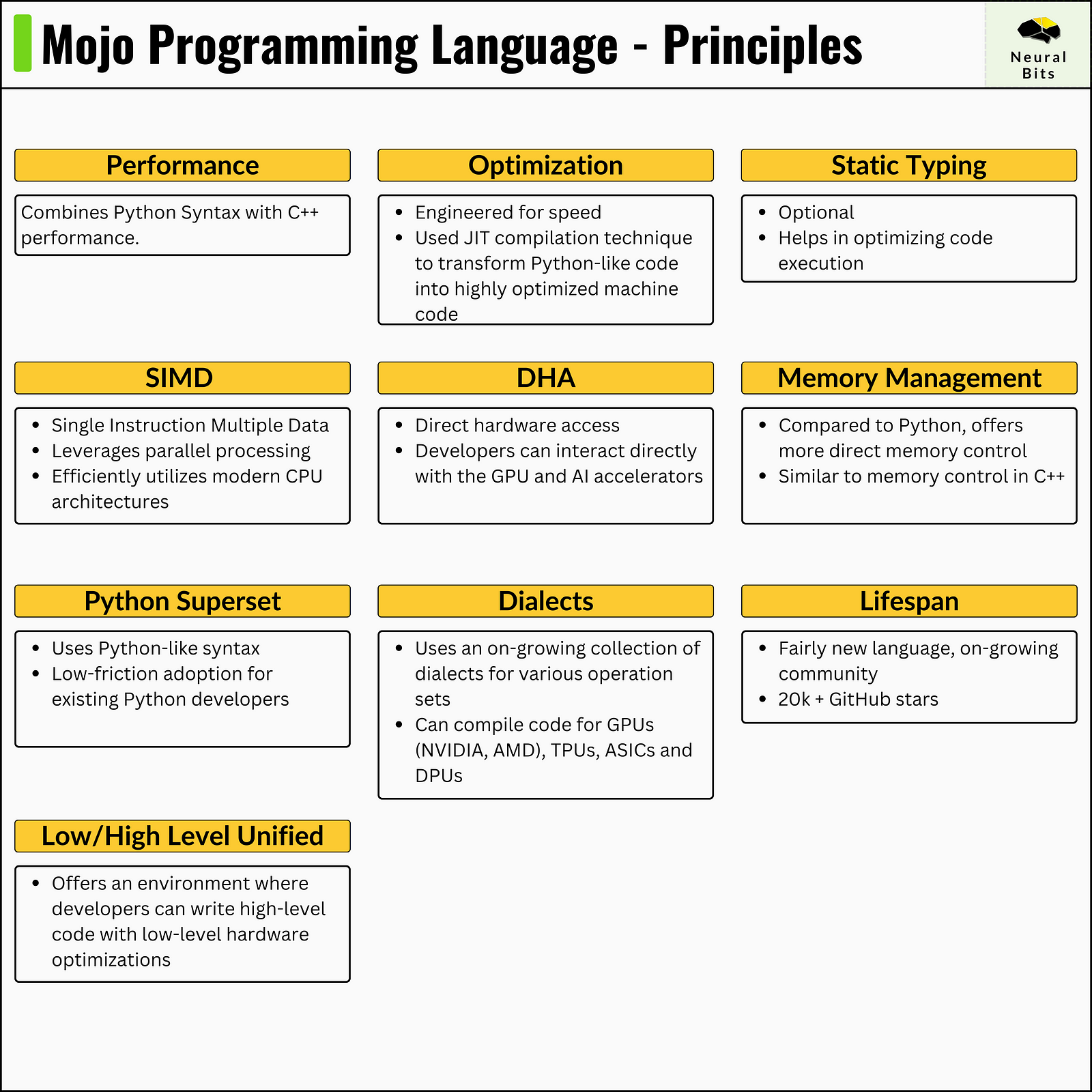
Key Principles of Mojo
Mojo was designed to close the gap between research and production by combining metaprogramming and systems programming characteristics with Python’s ecosystem and syntax.
Jeremy Howard wrote an initial review of Mojo on the Fast.ai Blog [9], and that “Mojo might be the biggest programming language advance in decades”.
Installing Mojo on Linux/Mac
⭐ Start by cloning the Mojo vs Python repo from the NeuralBits Hub [12].
Next, depending on the platform you’re on run one of the following:
# Mac
make install_mac
# Linux
make install_linux
Short overview of Matrix.mojo implementation
Let’s unpack and explain the implementation of a Matrix class in mojo, and uncover key elements such as DTypePointer, and SIMD.
S.I.M.D has the ability to perform math in a fast way, because operations can be performed on multiple numbers at the same time.

In Mojo, a struct is an optimized definition of Python’s class, that is compiled. In our Matrix.mojo implementation, we have the Matrix struct:
from memory import memset_zero
from random import rand, random_float64
alias type = DType.float32
struct Matrix[rows: Int, cols: Int]:
var data: DTypePointer[type]
# Initialize with random values
@staticmethod
fn rand() -> Self:
var data = DTypePointer[type].alloc(rows * cols)
rand(data, rows * cols)
return Self(data)
fn load[nelts: Int](self, y: Int, x: Int) -> SIMD[type, nelts]:
return self.data.load[width=nelts](y * self.cols + x)
fn store[nelts: Int](self, y: Int, x: Int, val: SIMD[type, nelts]):
return self.data.store[width=nelts](y * self.cols + x, val)To understand SIMD, let’s look at these functions:
fnload[nelts: Int] — which specifies that the load operation is performed on [width=nelts] elements at a time, and the number of elements in Memory Layout equals toY x self.cols + x.fnstore [nelts: Int] — which runs on the same principle but rewrites the elements in the Memory Layout.
Mojo functions can be declared with either
fnordef. Thefndeclaration enforces type-checking and memory-safe behaviors (Rust style) and is used in struct definitions, whereas def doesn’t enforce type declarations and has dynamic behaviors (Python style).
Benchmarking Python vs Mojo
Once Mojo is installed, you can run the Matrix Multiplication benchmark, comparing Mojo and Python.
⭐ Start by cloning the Mojo vs Python repo from the NeuralBits Hub [12].
Run the following:
make run_benchOn a successful run on my Macbook Pro M1 Max, I got these results:

Here are the use cases we’ve covered, the code of which can be found in the repository attached to this article:
MatMul Python
def matmul_python(C, A, B):
for m in range(C.rows):
for k in range(A.cols):
for n in range(C.cols):
C[m, n] += A[m, k] * B[k, n]MatMul Mojo — the same as Python, but executed with Mojo.
[StaticTypes] Mojo
fn matmul_naive(C: Matrix, A: Matrix, B: Matrix):
for m in range(C.rows):
for k in range(A.cols):
for n in range(C.cols):
C[m, n] += A[m, k] * B[k, n][Advanced][SIMD] Mojo — here SIMD (single instruction multiple data) is used and the computation is done by iterating on chunks of matrix columns at the same time.
alias nelts = simdwidthof[DType.float32]() * 2
fn matmul_vectorized_0(C: Matrix, A: Matrix, B: Matrix):
for m in range(C.rows):
for k in range(A.cols):
for nv in range(0, C.cols - nelts + 1, nelts):
C.store(m, nv, C.load[nelts](m, nv) + A[m, k] * B.load[nelts](k, nv))
# Handle remaining elements with scalars.
for n in range(nelts * (C.cols // nelts), C.cols):
C[m, n] += A[m, k] * B[k, n][Advanced][Parallel] Mojo — here the
parallelizefunction divides the work of matrix rows across multiple threads, so different rows of the result matrixCare calculated simultaneously. Within each row, SIMD is used such that chunks of the matrix are processed in parallel.
from algorithm import parallelize
fn matmul_parallelized(C: Matrix, A: Matrix, B: Matrix):
@parameter
fn calc_row(m: Int):
for k in range(A.cols):
@parameter
fn dot[nelts : Int](n : Int):
C.store[nelts](m,n, C.load[nelts](m,n) + A[m,k] * B.load[nelts](k,n))
vectorize[dot, nelts, size = C.cols]()
parallelize[calc_row](C.rows, C.rows)Running LLama 2 in pure Mojo
When announced, Mojo had only a few notebook examples of basic operations like Matrix Multiplication, types, or structs classes tutorials.
As an active member of the Mojo community, Aydyn Tairov has ported his llama2.py implementation to pure llama2.mojo [10].
For a more extensive benchmark on an Apple M1 Max, see the Mojo vs 7 other Languages [11] benchmark from Aydyn.

Conclusion
Mojo is far more than a language for AI/ML applications. It’s a version of Python that allows us to write fast, small, easily deployed applications that take advantage of all available cores and accelerators!
In this tutorial, we’ve touched on the concepts behind the Mojo programming language, why is it a superset of Python, and how fast it is compared to naive Python.
This article should provide you with a brief foundation on what Mojo is, how LLVM and MLIR work, and how you can benchmark it against Python to see the speed-ups it brings and also to summarise the principles on which the Mojo language was built.
References
Link | Title | Year of Publishing
Mojo [1], Mojo Programming Language, 2024
LLVM [2], The LLVM Compiler Framework, 2024
MLIR [3], MLIR Compiler Framework, 2024
Julia [4], The Julia Programming Language, 2024
Jax [5], Google JAX, 2024
Cython [6], Python C Bindings
Tensorflow [7], Tensorflow MLIR Documentation, 2024
MLIR Dialect [8], MLIR Dialects Documentation, 2024
Fast.ai Blog [9], Blogpost on Mojo from Jeremy Howard, 2023
llama2.mojo [10], Llama2 implementation in pure Mojo, 2023
Mojo vs 7 other Languages [11], Llama2 Mojo Benchmark, 2023
NeuralBits Hub [12], The NeuralBits Hub Repository, 2024