

How to maximise performance when working with large datasets (100+ GB).
Streaming data directly from Storage. Ensuring data privacy, governance and optimise model training on very large datasets.

Storage is cheap; computing is expensive.
Today, storing GBs or TBs of datasets for deep learning projects is relatively inexpensive, at just a few cents per GB.
The majority of PaaS that allows you to train Deep Learning models at scale, opt for downloading datasets onto the Virtual Machine’s storage disk.
Small datasets (e.g. under 50GB) might work, but with scale and distribution, we’ll quickly encounter challenges.
In this article, we’ll cover a method that’ll allow us to stream data directly without downloading it up-front, and we’ll see why this might be the optimal solution.
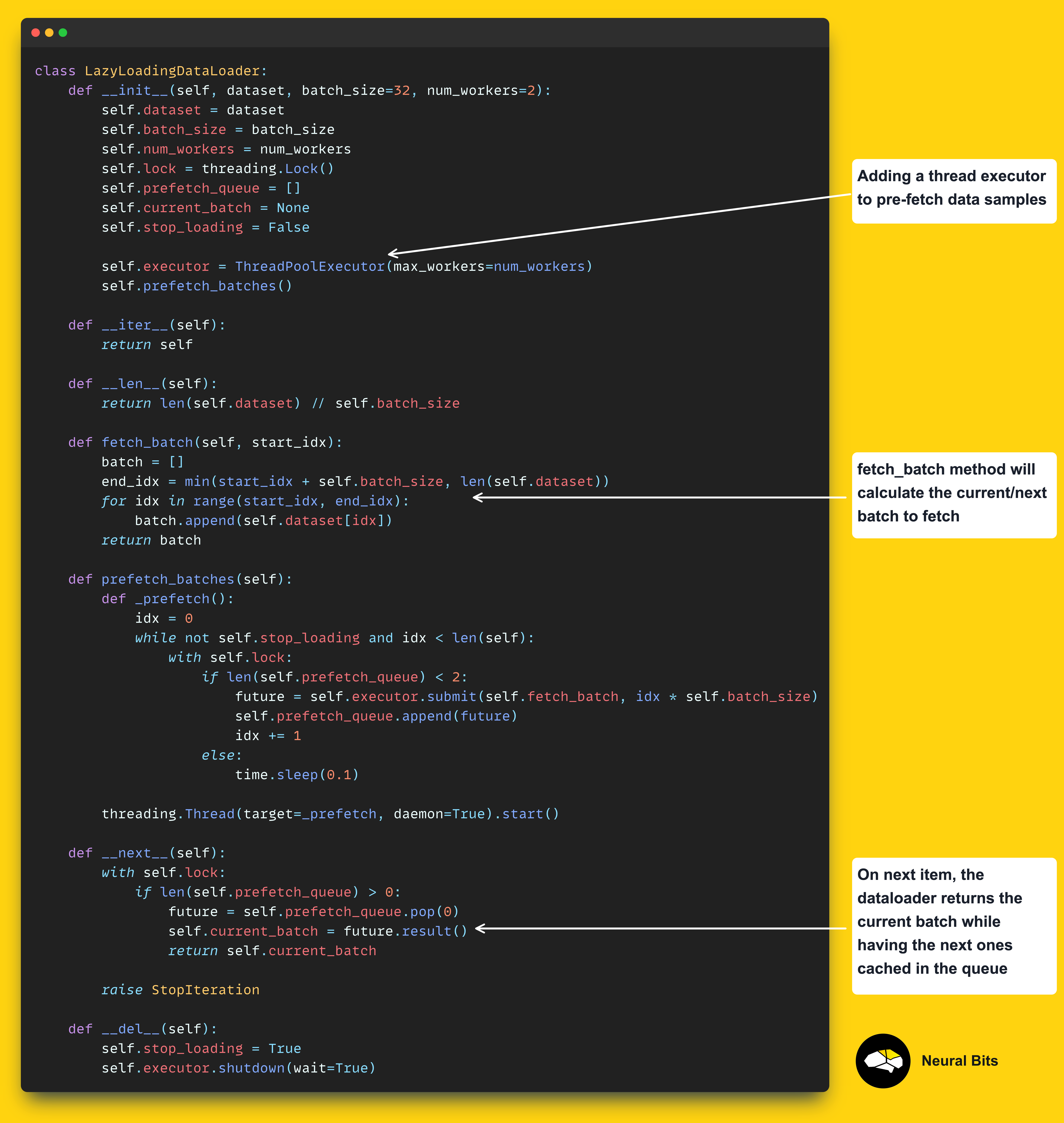
Table of Contents:
1. How storage costs evolved
2. Compute setups for training at scale
3. Challenges with downloading upfront
4. Custom streaming PyTorch DataLoader
5. LazyLoading batches for optimal throughput
6. Advantages
7. ConclusionHow storage costs evolved
For example, AWS charges around $0.023 per GB, and Azure charges $0.02 per GB for the first 50TB of storage in the high-frequency (HOT) access tier.

There are 3 types of cloud storage, as follows:
Hot storage: For frequently accessed data.
AWS S3 Standard and Azure Hot Blob Storage
Cold storage: For less frequently accessed data
AWS S3 IA (Infrequent Access) and Azure Cool Storage
Archive storage: For long-term data that is rarely accessed
AWS S3 Glacier and Azure Archive Blob Storage
However, computing costs can rise quickly, especially as you scale your deep learning model training in the cloud. Managing this balance—between the large volumes of data you need and the computing resources required to process it—is key for both performance and cost efficiency.
Compute Setups for Training at Scale

Many companies that work with Deep Learning and large datasets (100+ GBs and more), follow one of these two common approaches:
On-premise:
They build and maintain a local GPU cluster.
Physical storage, like NFS (Network File Share), is attached.
All data is stored locally, and models are trained on their infrastructure.
Cloud-based:
They use cloud provider's VMs for computing.
Datasets are stored in cloud storage solutions like AWS S3 or Azure Blob Storage.
Training is fully cloud-based and often integrated with MLOps pipelines for scalability.
Both approaches are viable, but due to data model lineage, data governance, and security requirements, many organizations prefer the cloud-based option.
What is the challenge here?
Research teams training models frequently might encounter challenges in handling data and models at scale. A common approach includes:
Using a few cloud GPU VMs.
Storing datasets in cloud storage (e.g., AWS S3, Azure Blob).
Downloading datasets to each VM before training.
Mounting cloud storage onto VMs as a filesystem (e.g., AWS S3FS, Azure BlobFuse).
Mounting cloud storage as an NFS within the same network layer as the VMs.
However, this approach can violate specific data privacy rules, especially when handling multi-regional data.
Challenges with Downloading Upfront
Here are a few obvious downsides to having the entire dataset on the VM’s disk, used for training:
Data Duplication - the same dataset is downloaded multiple times and stored on the disks. This leads to redundant data storage across machines.
Dataset Updates - if the datasets are updated regularly and they’re large, we’re wasting resources by downloading repeatedly.
Data Security - the more places the data is stored, the higher the attack surface for potential breaches.
A solution to this?
Decoupling the data location from the compute workload and stream batches directly into the model without moving or copying large datasets.
Custom streaming PyTorch DataLoader
The key is to implement a custom DataLoader with lazy loading, which connects to the cloud storage locations and streams batches of training data directly to the model, avoiding unnecessary data transfers and maintaining privacy.
This will allow us to check the following boxes:
We can train a global model on data from different regions
We can easily integrate Federated Learning into our workflow
If our training fails within the first epochs, we don’t download 100+ GB of datasets onto the VMs
We can opt for low-priority VMs (which are 90% cheaper) compared to dedicated instances
We can easily scale and distribute to multiple GPU VMs for training.
We can easily ensure all client’s requirements regarding data location and processing.
Let’s walk through an example, using a dataset stored in an Azure Blob Storage.

Here, we have the following functionality:
Azure Blob ContainerName and ConnectionString variables are fetched directly from our .env file, such that they are sensitive and protected values.
A transform pipeline will be applied to our images.
When fetching a sample, we download the image, preprocess it, and return it (image, labels) in our training loop, all done in memory.
Depending on the task, the metadata object might look like this:
metadata = [
{
"image": "<container_name>/client/train/image_001.jpg",
"label": np.array(<labels>)
},
{
"image": "<container_name>/client/train/image_002.jpg",
"label": np.array(<labels>)
},
...
]Which is an object detection use case, where labels are np.array(5) representing the bounding-box coordinates, and class_id (e.g 0 = person, 1 = car …).
Our metadata could contain 1000s of entries, and we could split them into train/test/val accordingly, and create data loaders for each subset.
How to further optimize?
Since we’re preparing the training samples, fully in memory and “discarding” them after use - we can further optimize our loader with a lazy-loading dataloader.
LazyLoading batches for optimal throughput
Instead of a blocking operation, where on each __next__ we get one batch, we could reduce the waiting time by adding lazy-loading.
Once a batch is downloaded and returned, we can download the next batch in the background.
Here, if we select a batch_size=32, we have:
After each batch is downloaded, we pre-fetch the next one using background threads.
When Dataset.__next__ is called, we’ll download the batch where idx=0 to idx=32.
In the background, we’ll also pre-fetch the next batch where idx=32 to idx=64.
The Dataset.__next__ relates to Python's iterator protocol.
In Python, any object that implements the
__iter__()and__next__()methods is considered an iterator. This method is responsible for returning the next item from the iterator and raising a StopIteration exception when there are no more items to return.
Here’s how we would use this DataLoader:
if __name__ == "__main__":
#load_env_variables()
metadata = [
{"image": "<container_name>/.../image_001.jpg", "label": 0},
{"image": "<container_name>/.../image_002.jpg", "label": 0},
]
dataset = BlobDataset(metadata)
data_loader = LazyLoadingDataLoader(dataset,
batch_size=32,
num_workers=2)
for batch in data_loader:
images, labels = zip(*batch)
images = torch.stack(images)
labels = torch.tensor(labels)
...
preds = model(images)
...Advantages
This approach of separating Data Location from the VMs where we train our model, allows us to scale easily.
Also, if we have multi-region clients and want to train a global model, we could train in a Federated Learning manner where each region trains a sub-copy of the model and aggregates the gradients.
For example, if we have Storage in the West-Europe region and a cluster of VMs for training in the same region - there are no additional costs for egress operations.
This means 0 cost on streaming data from the Storage to the Training loop.
Additionally, :
We ensure dynamic data access as we fetch it on the fly.
We don’t duplicate data locality and save storage costs.
We ensure clients’ data privacy requirements, without transferring data that might be sensitive (videos of people, CCTV footage) in raw format to disks.
Conclusion
In this article, we’ve showcased a method to stream data directly from the Cloud Storage into our training workflow, by using a custom Lazy-Loading DataLoader.
This approach allows us to keep the data in a single location (S3, Azure Blob), not duplicate it by downloading on the VM’s disk, and not exposing it to security risks, such as breaching the VM and viewing sensitive data, such as Images, CCTV, Audio footage used for training.
Subscribe if you haven’t, and stay tuned for the next deep-dive articles.
See you next week! :)