

How to add structure to your LLM Applications using SGLang
Unpacking SGLang technicals, RadixAttention and fast decoding for Structured Output.

In the last article, we covered the vLLM Inference Engine for serving LLM models using both the Online mode as a separate server and the Offline mode by instantiating the LLM client from vLLM and using it as a default PyTorch module.
In this article, we’re going to cover SGLang, another inference engine for serving LLMs, but with a few twists and improvements to it when compared with vLLM.
But you might ask, why so many inference engines for LLMs out there?
All the LLM inference engines aim to solve both of these critical problems in serving:
Difficulty in programming LM(language model) programs due to the non-deterministic nature of LLMs.
Inefficient execution of LM(language model) programs due to redundant computation and memory usage.
Although every engine focuses on and optimizes for the second point, SGLang provides a unique take on the first point by structuring how LLM applications are built.
SGLang is all about standardized structure.
The name stands for Structured Generation Language for LLMs and is a fast-serving framework for both LLMs and VLMs. It was introduced in this 2024 paper, Efficient Execution of Structured Language Model Programs. The core idea of SGLang is to systematically exploit the multi-call structure in LM programs for efficient execution.
The concept behind SGLang is split into a front-end language and a back-end runtime. The front end simplifies programming with primitives for generation and parallelism control. The backend runtime accelerates execution with optimizations like RadixAttention for KV cache reuse.

In this article, we’ll unpack SGLang's frontend-backend structure, explain how RadixAttention, the proposed method for KV Cache reuse, works, and provide examples of how to serve LLMs and build LM programs using SGLang’s proposed frontend primitives.
Table of Contents
SGLang Frontend Language
The Backend Runtime
RadixAttention and LRU Eviction Policy
The Compressed Finite State Machine
Conclusion
1. SGLang Frontend
SGLang is built mainly in Python (91%) alongside CUDA, C++, and Rust (~8%). It also supports speculative decoding, quantization, and continuous batching of requests, similar to other engines. Being built in Python, the front-end language syntax of SGLang is easy to understand as you’ll work with decorators or pre-configured methods to structure how a request passes through the application
Let’s go through a few front-end examples and showcase how we can use the front-end primitives. First, we need to install sglang using either pip or uv:
pip install
or
uv add sglangTo deploy a model using SGLang, follow this guide for Supported Models
SGLang provides some simple primitives such as gen, select, and fork. You can implement your prompt flow in a function decorated by sgl.function. You can then invoke the function with run or run_batch. The system will manage the state, chat template, and parallelism for you.
One of the most basic examples is multi-turn question answering:
import sglang as sgl
@sgl.function
def multi_turn_qa(s):
s += sgl.system(f"You are a helpful assistant than can answer questions.")
s += sgl.user("Please give me a list of 3 countries and their capitals.")
s += sgl.assistant(sgl.gen("first_answer", max_tokens=512))
s += sgl.user("Please give me another list of 3 countries and their capitals.")
s += sgl.assistant(sgl.gen("second_answer", max_tokens=512))
return s
state = multi_turn_qa()
print_highlight(state["first_answer"])
print_highlight(state["second_answer"])Here, we use the `system`, `user`, `gen`, and `assistant` primitives from the sglang frontend to define the workflow. The sgl.system primitive handles and injects the system prompt, further sgl.user and sgl.assistant are used in the chat template, and sgl.gen is a generation call.
We could already observe the structure and logic flow this approach has, compared to a more traditional approach such as:
def multi_turn_qa_default():
prompt = "You are a helpful assistant than can answer questions.\n"
prompt += "User: Please give me a list of 3 countries and their capitals.\n"
first_answer = call_llm(prompt, max_tokens=512)
prompt += "Assistant: " + first_answer + "\n"
prompt += "User: Please give me another list of 3 countries and their capitals.\n"
second_answer = call_llm(prompt, max_tokens=512)
return {
"first_answer": first_answer,
"second_answer": second_answer
}
answers = multi_turn_qa_default()
print(answers["first_answer"])
print(answers["second_answer"])Another interesting example we could cover is implementing the control flow for an LLM Agent trace, which has to choose which tool to use to solve the task at hand:
import sglang as sgl
@sgl.function
def control_flow(s, question):
s += "To answer this question: " + question + ", "
s += "I need to use a " + sgl.gen("tool", choices=["calculator", "web browser"]) + ". "
if s["tool"] == "calculator":
s += "The math expression is" + sgl.gen("expression")
elif s["tool"] == "web browser":
s += "The website url is" + sgl.gen("url")Commonly, throughout the evaluation steps for LLMs, we use the concept of LLM-as-a-judge, where we could have a smaller task-specific LLM that we aim to fine-tune or integrate into our project and evaluate its outputs using a larger model.
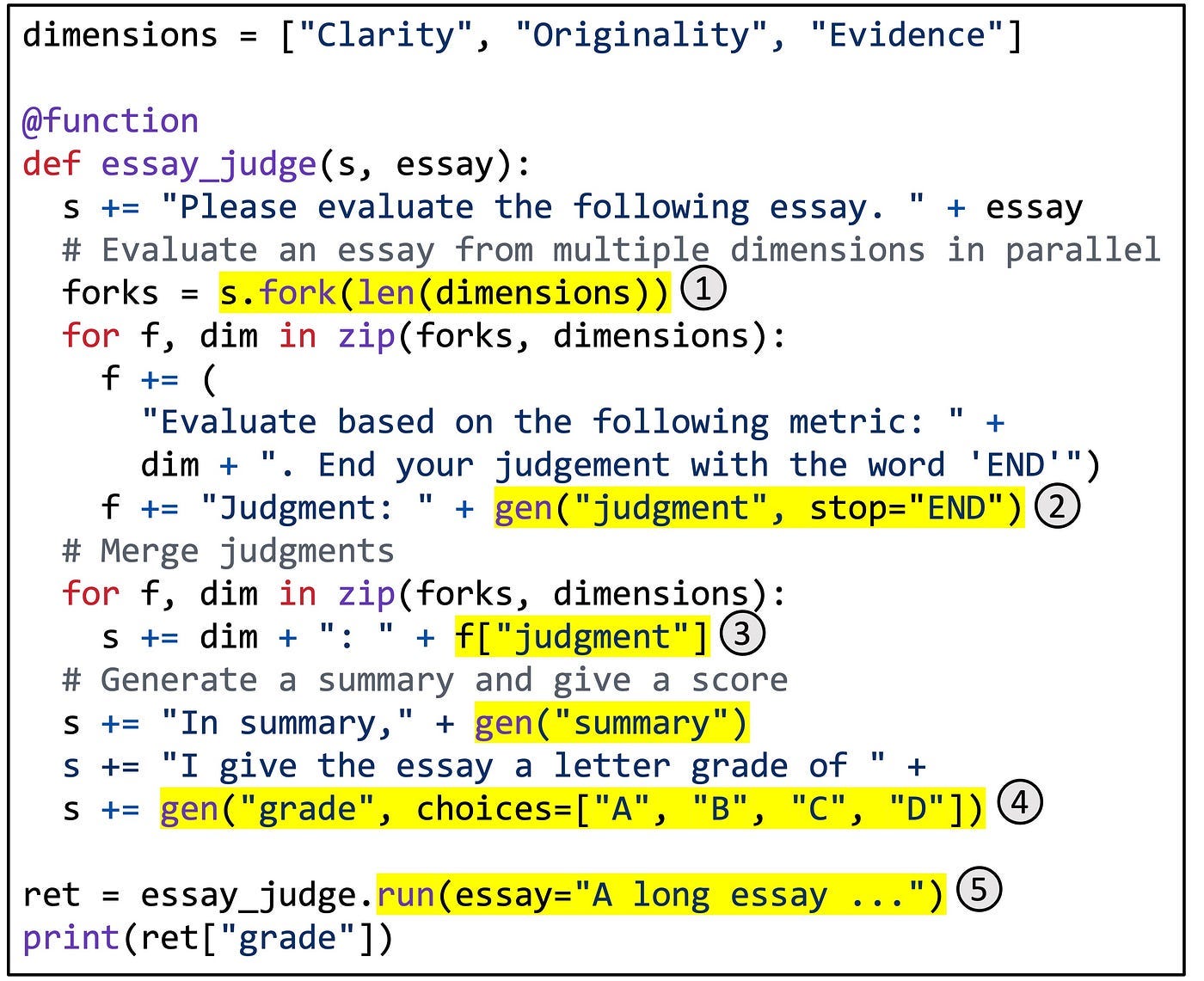
The `fork` primitive will parallelize our LLM calls into 3 since we have 3 different metrics we grade on, and we’ll execute them in parallel. Alongside the fork primitive, we use the sglang `function` decorator to wrap our evaluation logic and the same `gen` primitive to trigger generation calls.
Finally, we run this function using `.run` by passing in the essay contents.
These examples should provide a clearer idea of how the SGLang Frontend Language works. In the next section, let’s cover the backend runtime, the component which does the inference heavy-loading.
The Backend Runtime
In the SGLang paper, the authors propose 3 different techniques for optimizing LLM inference: RadixAttention for efficient KV Cache Management and Sharing, Compressed FSM (Finite State Machine) for faster decoding for structured outputs, and API Speculative Execution to optimize multi-calls to API-based LLMs only.
Let’s unpack them in order.
RadixAttention
If vLLM proposes PagedAttention to speed up the throughput, SGLang proposes a different KV Caching Layout called Radix Attention, which is based on the LRU Caching structure.
A radix tree is a data structure that serves as a space-efficient alternative to a classical trie (prefix tree). Unlike typical trees, the edges of a radix tree can be labeled not just with single elements but also with sequences of elements of varying lengths, significantly enhancing efficiency.
In the following image, we can follow how a new KV node is added in the KV Cache RadixTree and also see how an unused cache node is being evicted.
Let’s analyze it:

This approach is interesting in many ways as Paged Attention from vLLM, for example, uses fixed-size logical blocks, while Radix Attention doesn’t involve any fixed size but instead lets the cached tokens and currently running requests share the same memory pool, allowing the system to allocate memory dynamically for the cache.
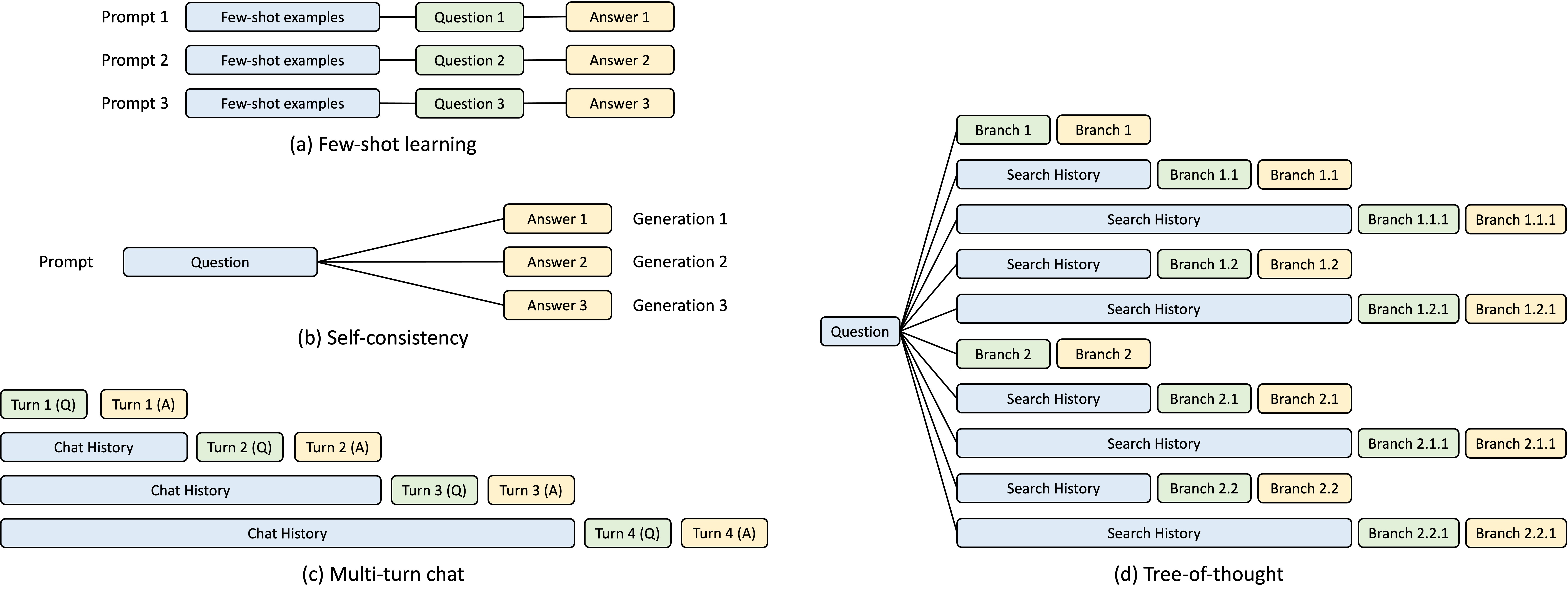
Because GPU memory is quickly filled by the KV Cache, a simple LRU eviction policy is added that will drop the least recently used leaf first. Thus, the KV Cache can be shared among requests, leading to better performance and generation speed and also memory efficiency due to the LRU Eviction mechanism.
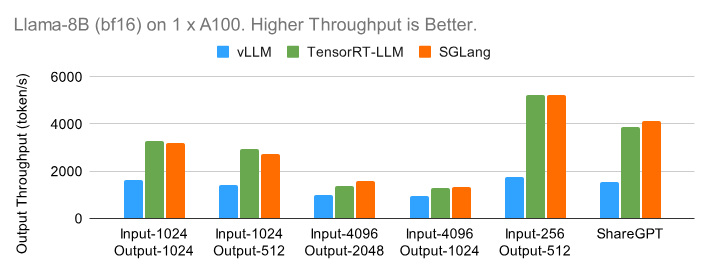
As we can see in the following throughput benchmark between SGLang, TensorRT-LLM, and vLLM on Llama3-8B, SGLang is almost on par with TensorRT-LLM and way faster than vLLM inference across all 4 querying patterns.
The four querying patterns are:
LILO: Long-Input-Long-Output, which could apply in a case where a user prompts an LLM with an essay and asks it to extend the essay to double/triple its length.
LISO: Long-Input-Short-Output, which could apply to a summarisation task, taking long text (long-input) and summarizing it (short-output)
SILO: Short-Input-Long-Output, which could apply to a story generation task, where the LLM is prompted with a few sentences and generates a complete story.
SISO: Short-Input-Short-Output could apply to short and structured responses from an LLM.
Compressed FSM
Constraining an LLM to consistently generate valid JSON or YAML that adheres to a specific schema is a critical feature for many applications. SGLang accelerates this using a compressed finite state machine that is compatible with any regular expression, thereby accommodating any JSON or YAML schema.
To understand it more simply, let’s follow this mental model:
The FSM method converts a JSON schema into a regular expression.
It then builds an FSM from that regular expression.
For each state in the FSM, it calculates the possible transitions.
It identifies the acceptable next tokens.
The FSM tracks the current state during decoding.
It filters out invalid tokens by applying logit bias to the output.
Essentially, the FSM guides the language model's (LLM) generation, ensuring the output follows the specified JSON schema by determining the valid next tokens at each step.

Find below a quick comparison of FSM in action against the default approach to structured format generation with vLLM as the inference engine:
For full benchmarks, please see this guide from SGLang (LMSYS.org)
Conclusion
In this article, we’ve covered the SGLang inference engine for LLMs. We unpacked and explained the frontend-backend structure, covered the primitives that SGLang offers to bring structure to LM applications, and explained what makes SGLang fast and memory efficient, especially for LLM applications that involve structured outputs such as JSON or YAML.
We provided a few examples on how to use the SGLang frontend primitives and explained RadixAttention and how it manages KVCache.
After reading this article, you have a clear understanding of what SGLang is, how it works, and when to consider it a best fit for your LLM applications.
Thank you for reading, see you in the next one!
References:
vLLM Optimization: (Medium: Bhukan, 2024) - https://medium.com/cj-express-tech-tildi/how-does-vllm-optimize-the-llm-serving-system-d3713009fb73
vLLM & PagedAttention: (Continuumlabs.ai, 2024) - https://training.continuumlabs.ai/inference/why-is-inference-important/paged-attention-and-vllm
SGLang: (arXiv:2312.07104, 2023) - https://arxiv.org/abs/2312.07104
vLLM GitHub: (GitHub: vllm-project) - https://github.com/vllm-project/vllm
SGLang Llama3: (Lmsys.org, 2024) - https://lmsys.org/blog/2024-07-25-sglang-llama3/
Willard, B. T., & Louf, R. (2023, July 19). Efficient guided generation for large language models. arXiv.org. https://arxiv.org/abs/2307.09702
Fast JSON Decoding for Local LLMs with Compressed Finite State Machine | LMSYS Org. (2024, February 5). https://lmsys.org/blog/2024-02-05-compressed-fsm/#figure3