
Guide to understanding Concurrency & Parallelism in Python
When, what and how to use AsyncIO, Threading and Multiprocessing in Python.

Nowadays, CPUs are manufactured with multiple cores to boost performance by enabling parallelism and concurrency of applications.
To effectively use the CPU cores when running applications, we make use of the “concurrency” programming model, which encapsulates parallel processing such as multithreading, multiprocessing, and asynchronous execution.
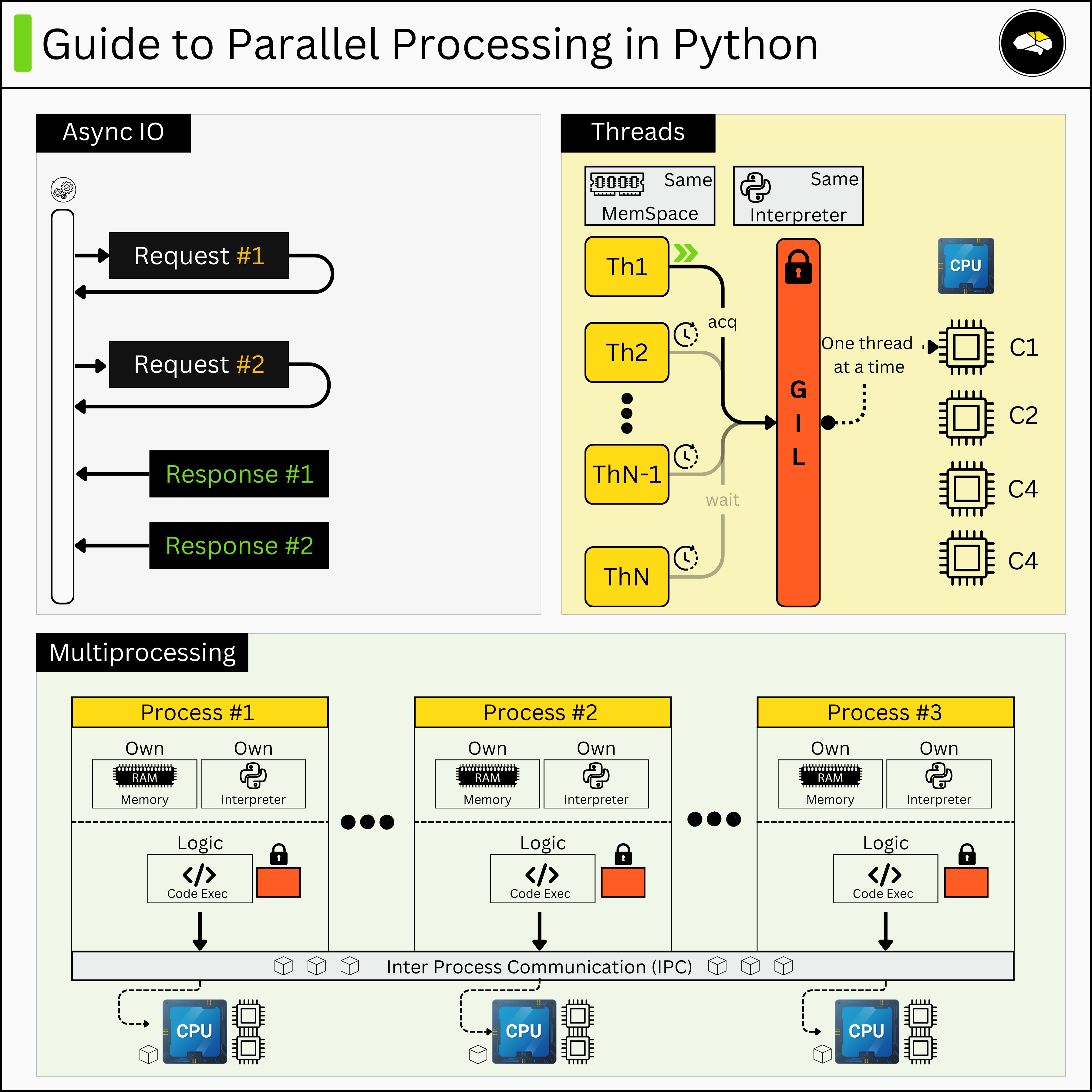
Even though in Python 3.13, the GIL was set to Optional, enabling full parallel execution, many projects still use earlier versions of Python as it’s risky to port relatively mature projects to bypass the GIL.
In this article, we’ll focus on how Python handles the concurrency concept, explain the GIL limitation, and go over when and how to use async, multithreading, and multiprocessing with real use cases.
Table of Contents
Understanding Python GIL
Interpreted vs Compiled Languages
What are I/O Bound and CPU Bound Tasks
Using AsyncIO for I/O Bound Tasks
Using Multithreading for I/O Bound Tasks
Using Multiprocessing for CPU-Bound Tasks
Conclusion
1. Understanding Python GIL (Global Interpreter Lock)
The GIL is a mutex (mutual exclusion lock) that protects access to Python objects and prevents multiple native threads from executing Python bytecode simultaneously.
A mutex (mutual exclusion) is a synchronization primitive used to prevent multiple threads from accessing a shared resource simultaneously.
This lock ensures thread safety within Python's memory management and object reference counting system.
Why does Python have GIL?
The GIL exists primarily to simplify memory management in CPython, the most widely used Python implementation.
Python's memory management system relies on reference counting.
Without GIL, multiple threads could update reference counts simultaneously, causing memory corruption or crashes.
Why does C++ or Rust don’t have GIL?
In C++ and Rust, threads can execute concurrently and in parallel fully utilizing multiple CPU cores for CPU-bound tasks.
C++ is build with native concurrency in mind and uses manual memory management. It is mainly the developer’s task to handle memory safety.
On the same topic, Rust’s ownership model ensures memory safety.
Rust, at compile time prevents data races through the borrow-checker mechanism, which enforces strict rules on how memory is accessed by multiple threads.
2. Interpreted vs Compiled Programming Languages
Python is an interpreted language, which means that between the High-Level API code and machine code execution chain, there’s a layer of abstraction.
First: Python code is first compiled to bytecode.
Second: The bytecode is then executed by the CPython Interpreter.The GIL is introduced at the interpreter level.
Compared to compiled languages (e.g. C++, Rust) where the High-Level API code is compiled and saved as an executable - the Interpreted languages like Python will load and keep the code in memory and interpret it at each run.
This workflow implies slower execution and error handling because errors are detected at runtime.
3. What are I/O-bound and CPU-bound Tasks
Across all methods of concurrency, we could separate these by the tasks they run.
In short, we could understand them as follows:
A I/O task stands for Input/Output and means then program is bottlenecked by input/output operations.
A CPU task means the program is bottlenecked by CPU processing.
A CPU-bound task spends most of its time doing heavy calculations with the CPUs. Some examples of CPU-bound tasks:
ML model training
Image/Data Processing
Video Decoding and Transcoding
An I/O-bound task spends most of its time waiting for I/O responses, which can be responses from web pages, databases, or disks. Some examples of I/O tasks:
Fetching data from APIs
Querying Databases
Asyncio and Multithreading in Python are efficient for I/O bound tasks while it is recommended that CPU-bound tasks are delegated using multiprocessing.

4. Using Asyncio for I/O Bound Tasks
Asyncio is excellent for applications where you need to manage a large number of I/O-bound tasks simultaneously, such as thousands of open network connections or file read/write operations.
Here’s a simple example of running an asyncio loop from scratch:
import asyncio
async def hello():
print("Hello...")
await asyncio.sleep(2) # seconds
print("...World!")
async def main():
task1 = asyncio.create_task(say_hello())
task2 = asyncio.create_task(say_hello())
await task1
await task2
asyncio.run(main())A more advanced example is the FastAPI which is a widely popular framework, built in Python that uses asyncio to enable highly efficient, non-blocking handling of API requests, queries, and external service calls.
from fastapi import FastAPI
import asyncio
app = FastAPI()
async def model_inference():
result = await <model_inference_task>
return {"msg": result, "code": 200}
@app.get("/model_inference")
async def run_async_task():
result = await model_inference()
return resultFastAPI is deployed on top of Uvicorn and it supports asynchronous execution via asyncio.
5. Using Multithreading for I/O Bound Tasks
Real multithreading in Python is not possible due to the GIL limitation.
📝 Threads work in a shared memory space.
They can access objects using simple synchronisation mechanisms (e.g threading.Lock)
Multithreading in Python is most useful for I/O-bound tasks.

Since the GIL is released during I/O operations, Python threads can switch between tasks while waiting for data, making multithreading effective in these scenarios.
Here’s a simple example of multithreading in Python:
import threading
import time
def say_hello():
print("Hello...")
time.sleep(2)
print("...World!")
thread1 = threading.Thread(target=say_hello)
thread2 = threading.Thread(target=say_hello)
thread1.start()
thread2.start()
thread1.join()
thread2.join()In this order, we will have the following output:
Hello... # 1A: starts waiting 2 sec
Hello... # 1B: starts waiting 2 sec
...World # 1A: after 2 sec
...World # 1B: after 2 secA more complex example is this implementation, where we have N Threads as producers of messages to a Kafka cluster.
class KafkaProducerThread(threading.Thread):
def __init__(
self,
producer_id: int,
producer: KafkaProducer,
topic: str,
fetch_function: Callable,
) -> None:
super().__init__(daemon=True)
self.producer_id = f"KProducerThread #{producer_id}"
self.producer = producer
self.topic = topic
self.fetch_function = fetch_function
self.wait_window_sec = 5
self.running = threading.Event()
self.running.set()
def run(self) -> NoReturn:
while self.running.is_set():
try:
msgs = self.fetch_function()
if msgs:
msgs = [msg.to_kafka_payload() for msg in msgs]
self.producer.send(self.topic, value=msgs)
self.producer.flush()
)
time.sleep(self.wait_window_sec)
except Exception as e:
self.logger.error(f"Error {e}")
self.running.clear()
def stop(self) -> None:
self.running.clear()
self.producer.close()
self.join()For true parallelism in Python, we’ll have to use Multiprocessing that bypasses the GIL.
6. Using Multiprocessing for CPU Bound Tasks
For real parallel processing in Python, we’ll have to use multiprocessing.
Multiprocessing in Python is most useful for CPU-bound tasks. Different processes work in separate memory spaces, thus needing IPC (Inter Process Communication) to communicate.
With Python, there are 3 different methods to start a multiprocessing pool:
Fork - faster because the child process doesn’t need to start from scratch and inherits parent process memory. (Default on UNIX)
Spawn - starts a fresh process, fresh Python Interpreter, copies data. (Default on Windows)
Fork-Server - merge between both methods (Optional)
A process runs in its own Memory and CPU space, having its own GIL. More specifically, a standalone process “clones” the Python interpreter workflow, thus we could imply that, 1xProcess = 1xSeparate Python program.

Here’s one simple multiprocessing example:
import math
from multiprocessing import Process
def calc_square(numbers):
squares = [i*i for i in numbers]
print("Squares: {0}".format(squares))
def calc_square_root(numbers):
square_roots = [round(math.sqrt(i), 2) for i in numbers]
print("Square Roots: {0}".format(square_roots))
if __name__ == "__main__":
number_set = list(range(1,6))
p1 = Process(target=calc_square, args=(number_set,))
p2 = Process(target=calc_square_root, args=(number_set,))
p1.start()
p2.start()As the output, we’ll have both run independently:
Squares: [1, 4, 9, 16, 25]
Square Roots: [1.0, 1.41, 1.73, 2.0, 2.24]An example close to AI/ML Engineers is the PyTorch Dataloader worker, as it uses a multiprocessing pool underneath to load and transform data samples in parallel. When we use the Dataloader, we specify num_workers to distribute the workload.
A worker is a separate process in the Pytorch Dataset class helps loading a batch of data and apply processing to it (e.g transforms library) independently of other processes.
This allows for lazy_loading and faster fetching of batches.
import torch
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from PIL import Image
class CustomImageDataset(Dataset):
def __init__(self, image_paths, transform=None):
self.image_paths = image_paths
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path)
if self.transform:
image = self.transform(image)
label = 0
return image, label
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
dataset = CustomImageDataset(image_paths, transform=transform)
N = 4
dataloader = DataLoader(dataset, 32, shuffle=True, num_workers=N, pin_memory=True)Here, we have a batch_size=32 and num_workers=4 which means that:
4 Processes will load images separately.
They will all push images to mp.Queue (which is a form of IPC)
The Dataset class will gather from the Queue and assemble the batch
7. Conclusion
In this article, you’ve learned everything you need to know about concurrency in Python and when to use asyncio, multithreading, and multiprocessing.
We’ve explained the GIL limitation and the difference between Interpreted and Compiled languages over memory access.
We’ve covered the difference between I/O and CPU-bound tasks, provided 2 examples, one simple and one complex for each method, and explained the intricacies that each of these methods imposes.
This article will help you choose the right concurrency method based on what workloads you’re planning to implement.
Appendix:
All images were created by the Author.
great one!!