

7 Frameworks and Toolkits you must know for AI and Deep Learning
Concise diagrams and summaries of popular NVIDIA libraries used by AI/ML Engineers across all ML, DL and GenAI.

This short, straight-to-the-point article covers all major NVIDIA AI frameworks you must know if you’re working as an AI/ML Engineer, specifically if training, optimizing, and deploying AI workloads at various scales.

1. NVIDIA CUDA
As CUDA is widely known and all major AI frameworks (e.g, PyTorch, MXNet, TensorFlow) depend on CUDA, we won’t spend too much time diving into its details. In short, CUDA is a parallel computing platform and programming model. It allows developers to map complex computations and parallelize operations across multiple GPU cores using GPU kernels.
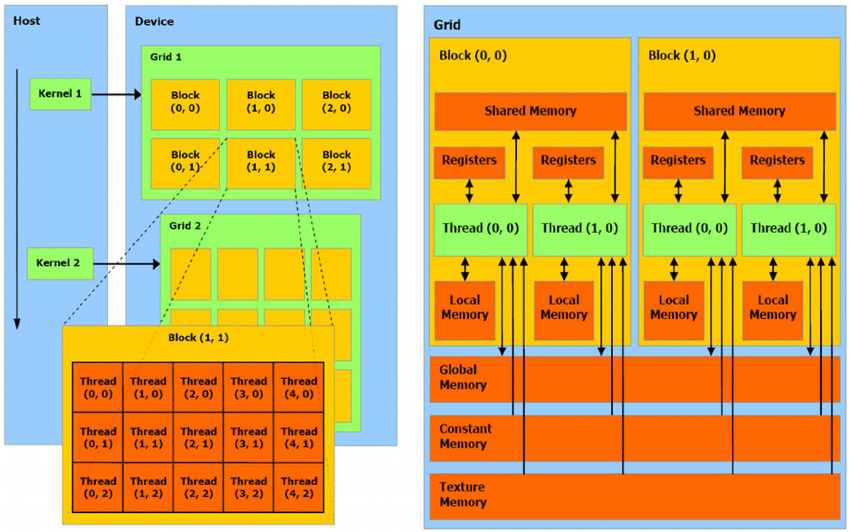
Let’s cover the key points you must know about CUDA:
Kernels - C/C++ functions that CUDA executes on the GPU, an array of CUDA threads executes each kernel.
Thread - executes the kernel instructions and is the smallest unit of abstraction in CUDA.
Block - groups of threads that can be organized in 1D-3D structures. Threads in a block can synchronize and share a fast shared_memory.
Grid - collection of blocks that execute a kernel. For example, a grid of 10x10 blocks with 256 threads/block will result in a total of 25600 threads.
Streaming Multiprocessor (SM) - is the processor unit that executes thread blocks.
Global Memory - is the GPU memory, the VRAM, which can be accessed by all threads.
Shared Memory - fast, on-chip memory that can be accessed by all threads in a block.
The GPU architectures are built around a scalable array of multithreaded SMs. When a CUDA program invokes a kernel grid, the thread blocks are distributed to these multiprocessors, which are designed to execute hundreds of threads concurrently.
Now, to make that possible, CUDA follows the SIMT (Single Instruction Multiple Thread) architecture, which allows threads to run async and use a Barrier for synchronization. As per CUDA documentation, here’s how that works:
#include <cooperative_groups.h>
__global__ void simple_sync(int iteration_count) {
auto block = cooperative_groups::this_thread_block();
for (int i = 0; i < iteration_count; ++i) {
/* code before arrive */
block.sync(); /* wait for all threads to arrive here */
/* code after wait */
}
}The `block.sync()` is the barrier and awaits all threads to arrive at this execution step. There are more intricacies to CUDA as we’ve barely touched the surface, but you as an AI/ML Engineer don’t need to know the low-level details of it.
Having an understanding of what CUDA is, how it works, and where it is used is more than enough. If you’re interested in a practical tutorial with CUDA and GPU Programming in general, find this previous article showcasing how to build a CUDA Kernel in C++, Python, and OpenAI Triton Language.

2. NVIDIA cuDNN
Another key library that builds on top of CUDA and powers up AI workloads is cuDNN, which stands for NVIDIA CUDA Deep Neural Network library (cuDNN). This library contains a large set of primitives that are fundamental to model training, inference, and optimizations.
Under the hood, it provides highly tuned implementations for standard routines such as forward and backward convolution, attention, matmul, pooling, and normalization - which are used in all Neural Network Architectures, from basic CNN Image Classifiers up to complex, billion-parameter LLMs.
When you install any version of CUDA, either standalone or via PyTorch binaries, cuDNN comes out of the box as they’re tightly coupled.

3. NVIDIA TensorRT
Also built on top of CUDA, TensorRT is a compiler toolkit for Deep Neural Network Architectures. If we unpack a model architecture, we have multiple layer types, operations, layer connections, activations, etc. Imagine an NN architecture as a complex Graph of operations. TensorRT can scan that graph and identify bottlenecks, optimize, remove, merge layers, reduce layer precision, and perform many other optimizations.
In inference pipelines, we take a trained model and make it run efficiently on existing hardware. TensorRT does just that by compiling the model, thus reducing inference latency and increasing overall throughput. Here’s an illustration of how TensorRT Compiler works:
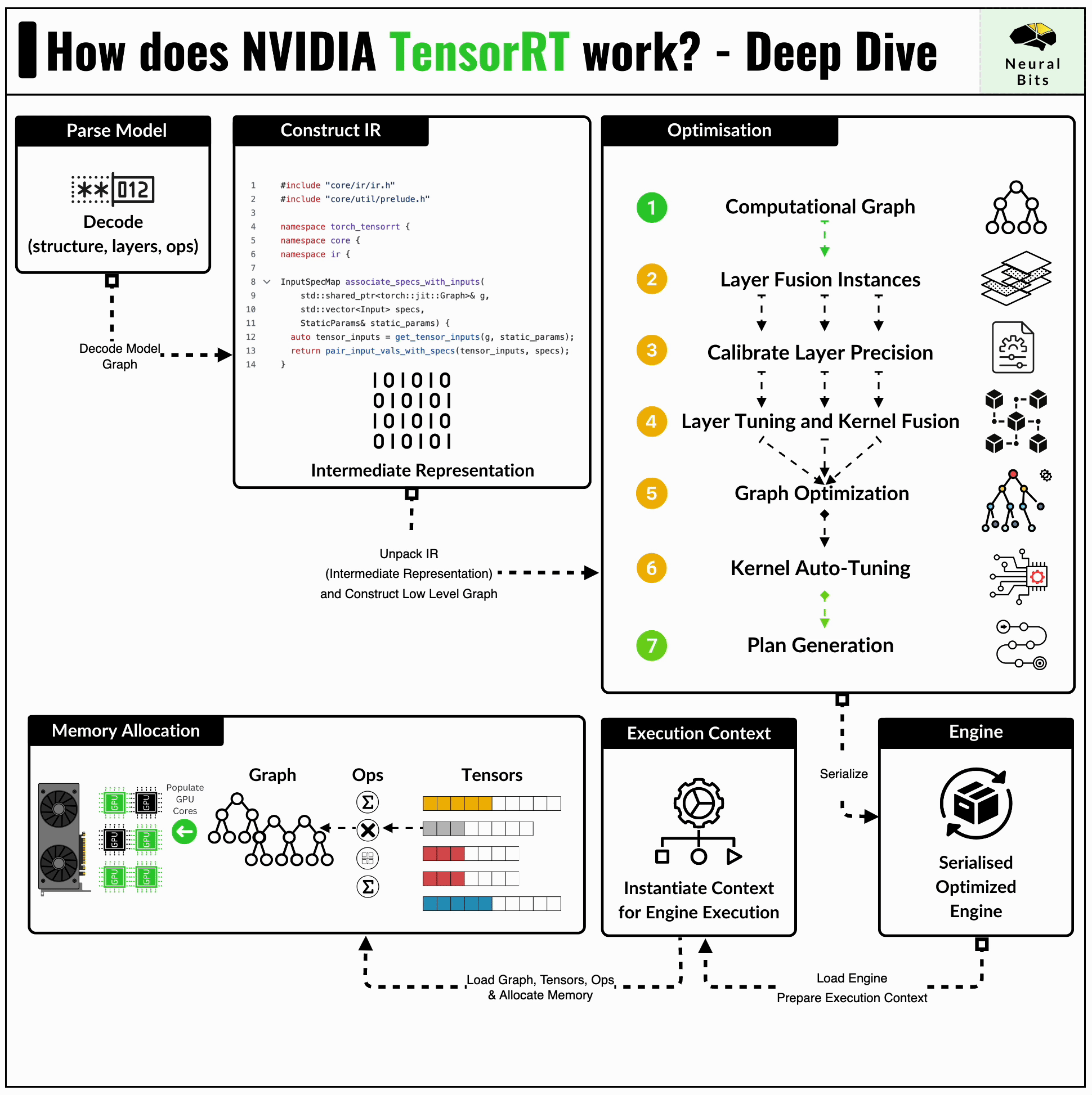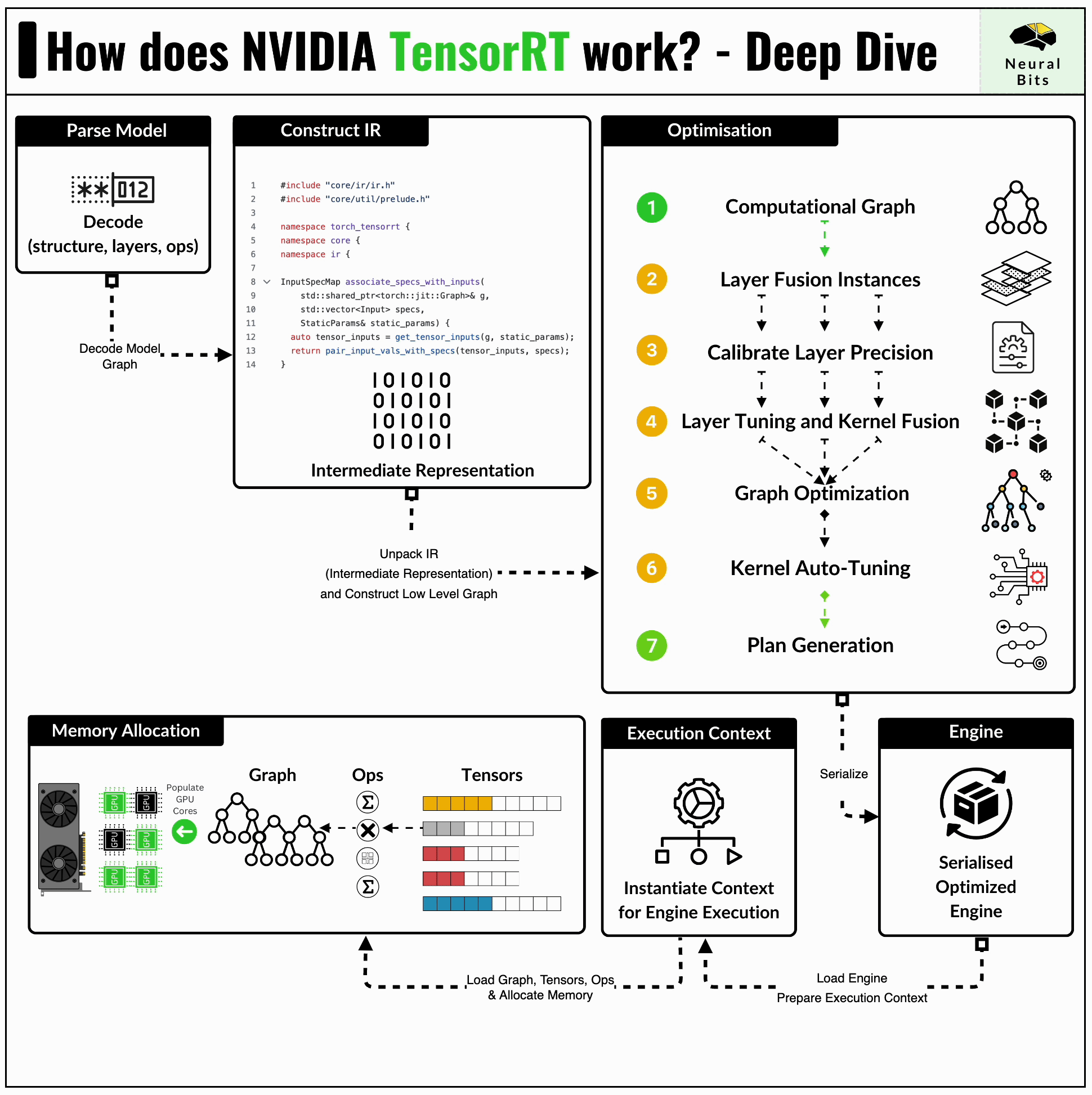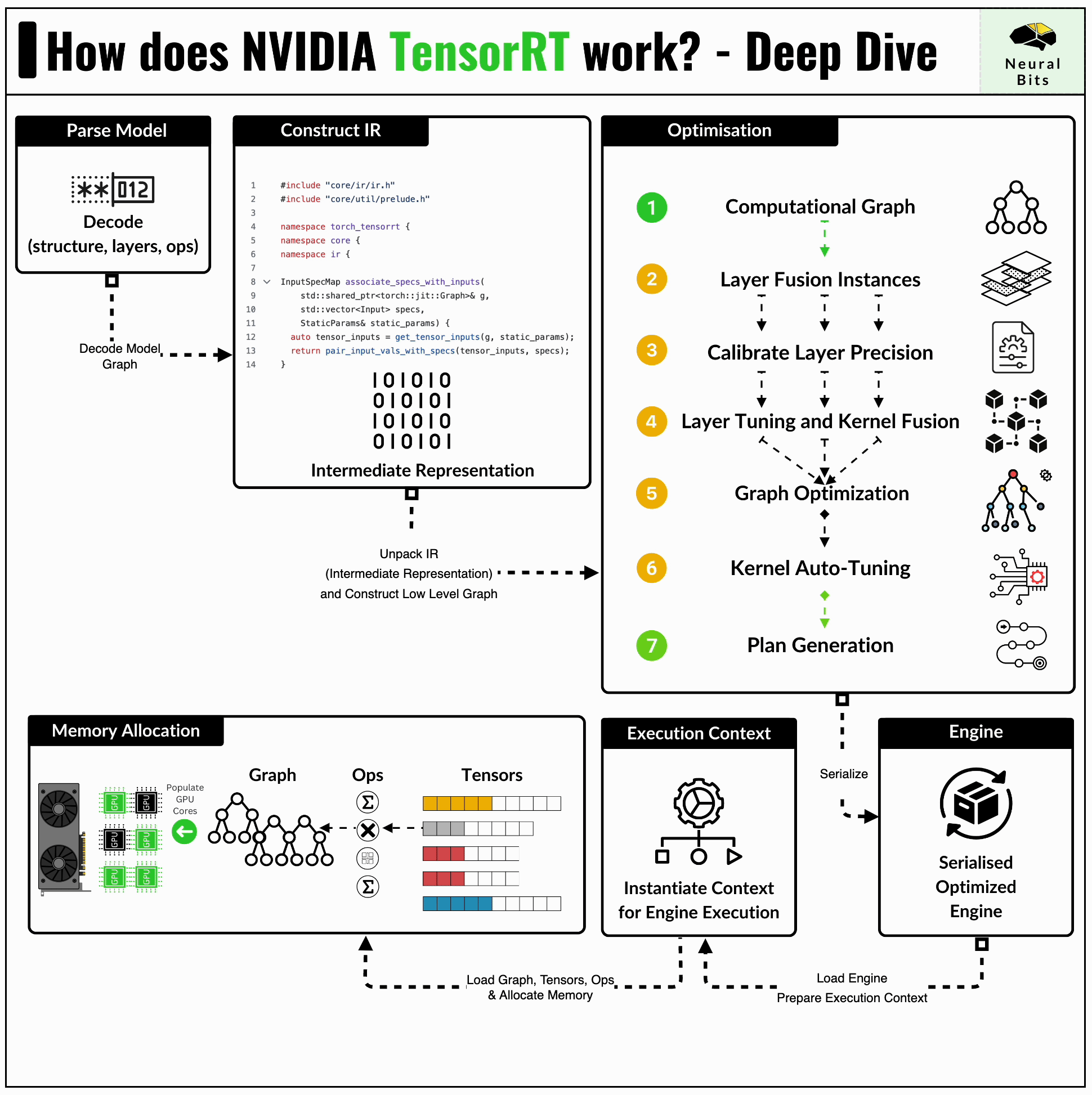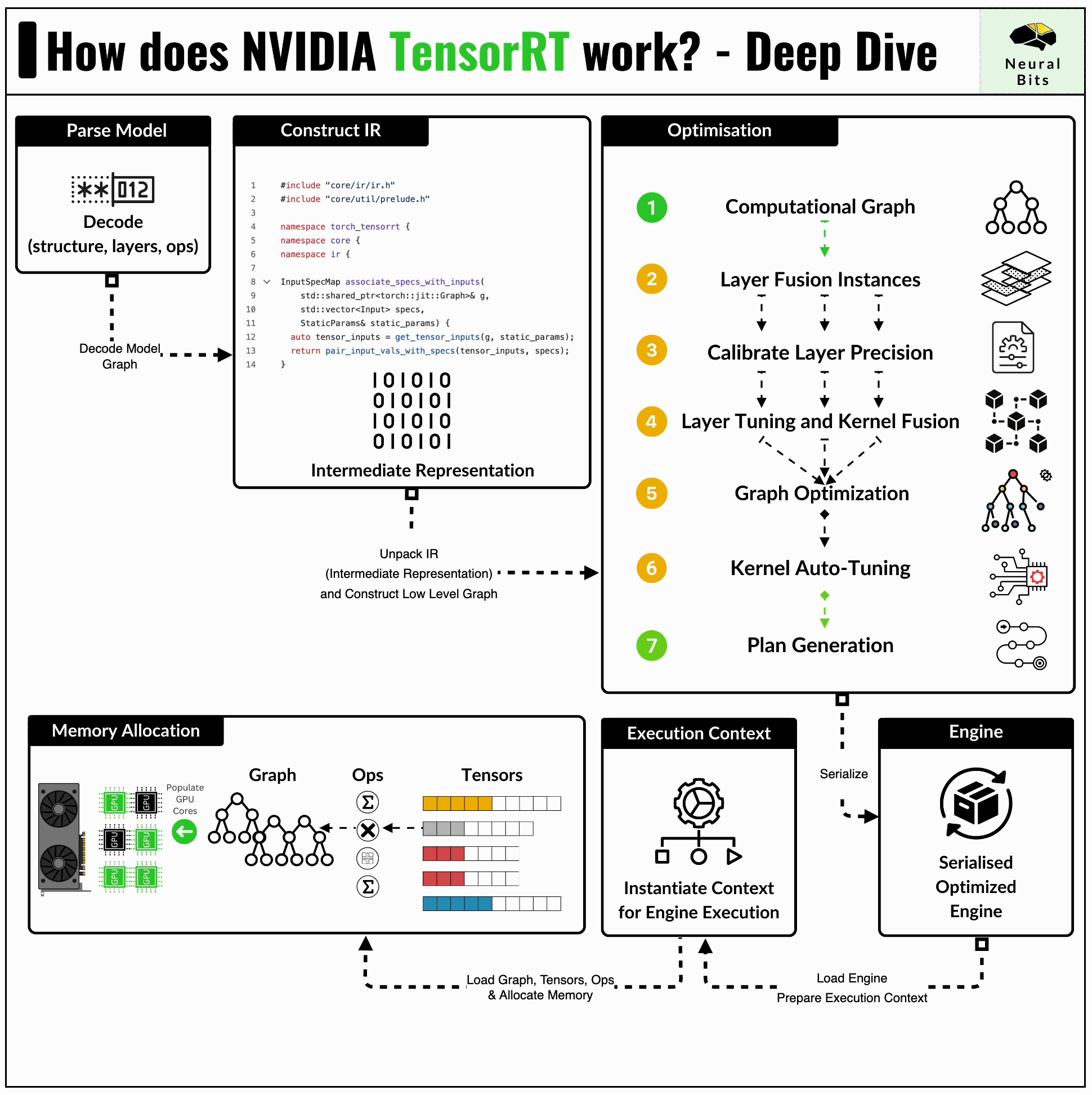
When we compile a model into an engine using TensorRT, the following workflow is executed:
First, we have our trained model, which is in its default format, not yet compatible with our compiler. At this stage, the model usually needs to be converted to the ONNX (Open Neural Network Exchange) format, which acts as a bridge between different frameworks. Using ONNX, we can take a PyTorch model and reconstruct it in Tensorflow, for example.
Secondly, having the ONNX model, the TensorRT compiler scans the model graph and creates its internal format representation of it.
Next, it applies a series of inflight optimizations to the graph itself, which might include:
Fusing Layers to reduce overhead, speed up execution, and shrink the model size.
Calibrate Layer Precision by identifying the range of numbers a layer might take and clamping the outliers. For instance, if some operations yield values that can be represented in FP16, there’s no need for the layer to be in FP32 data type format.
Kernel Autotuning identifies which kernels are to be executed at each stage of the graph and automatically generates the best parallelism configuration for these, mapped on the specific GPU.
For instance, the GPU architectures vary in the numbers of CUDA Core, SMs, Tensor Cores, FLOps, and VRAM. During compilation, TensorRT can map kernels differently for each GPU architecture, leveraging the numbers of CUDA Cores to be used.
Finally, TensorRT exports an `.engine` file containing the new optimized model format, which can be used for inference.
Further, we can load this file in C++ and use TensorRT C++ API or load it in Python and use the `tensorrt` API bindings. In production scenarios, TensorRT Engines are usually served with the NVIDIA Triton Inference Server, which is designed for large-scale deployments and supports the TensorRT backend.
For a hands-on tutorial on the TensorRT Compiler, please see this article:

4. NVIDIA TensorRT-LLM
TensorRT-LLM is an customized and enhanced version of the standard TensorRT compiler toolkit, that brings state-of-the-art optimizations to LLM and Generative AI model architectures.
These model architectures are more complex and bring their challenges due to the auto-regressive nature of Transformers. With LLMs or VLMs, we need to optimize the attention mechanisms, also account for model parallelism since many LLMs don’t fit on a single GPU and have to be partitioned via Pipeline Parallel or Tensor Parallel. Additionally, the prefill and decode stages require KV caching, and default dynamic batching doesn’t apply to LLMs because input prompts vary in size, and it’s difficult to find a batch strategy to fit all patterns, thus, custom batching such as inflight request batching is required.
While some optimizations still apply between standard DNN architectures and newer transformer-based ones, LLMs require many custom techniques, and TensorRT-LLM is a library engineered to bring all that.

To use a tensorrt-llm optimized engine, the library implements an LLM API in Python to simplify model setup and inference across both native PyTorch or TensorRT backends.
To mention a few key points:
We could pass in a model directly from Hugging Face and convert/optimize it to TensorRT-LLM.
After compilation, the model is split into 2 sub-models, one for the Tokenizer and one for the actual LLM engine. These are connected as a pipeline. The input request pattern is prompt → tokenizer → model_engine → detokenize → output.
However, a nicer approach and standardization for inferencing LLMs in TensorRT-LLM format is brought by deploying the optimized LLM model with Triton Inference Server.
5. NVIDIA Triton Inference Server
NVIDIA’s Triton Inference Server is an open-source software that provides a high-performance serving system for AI models. It’s designed to optimize and serve models for inference in production environments, ensuring efficient utilization of GPU and CPU resources.
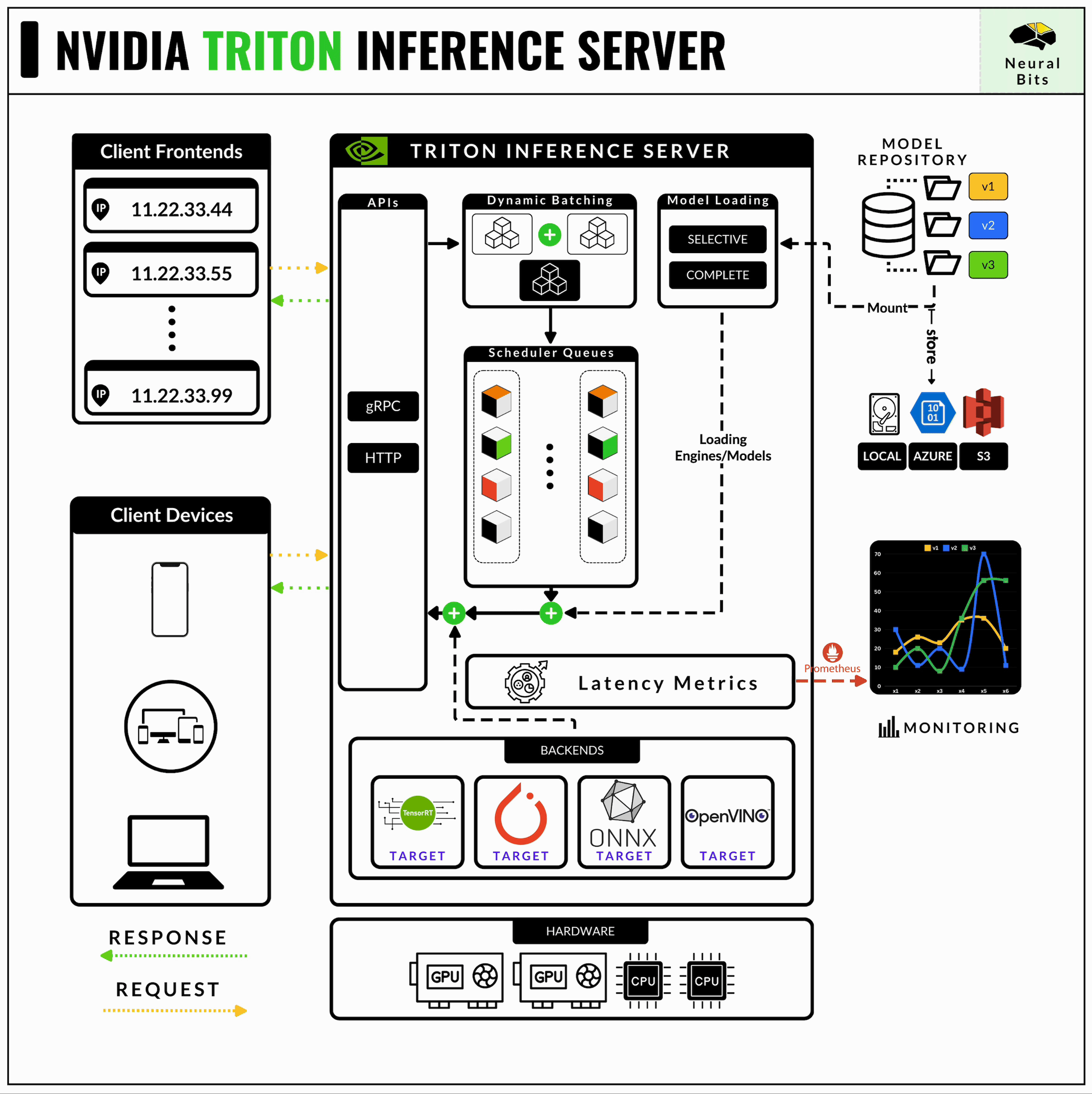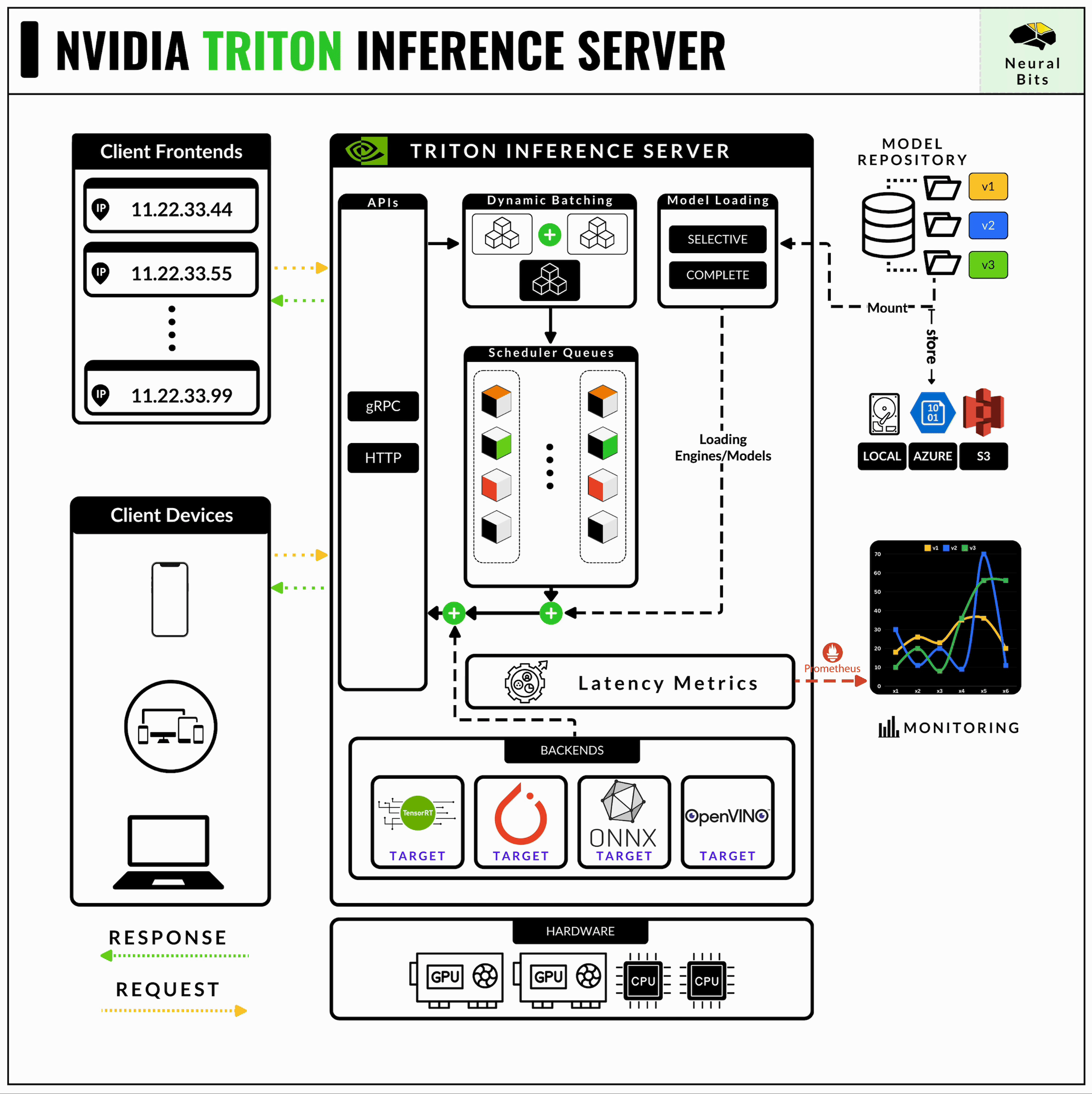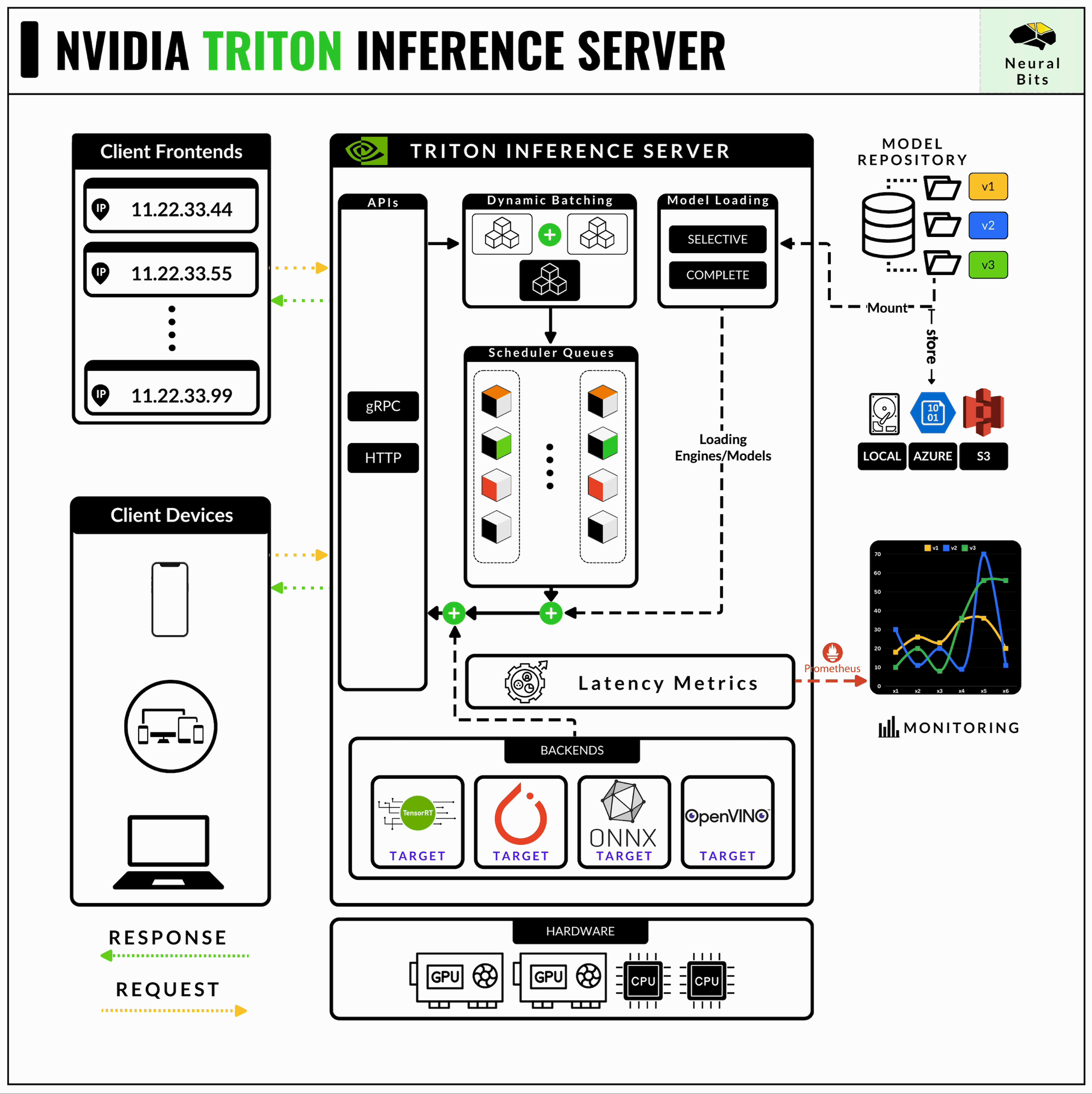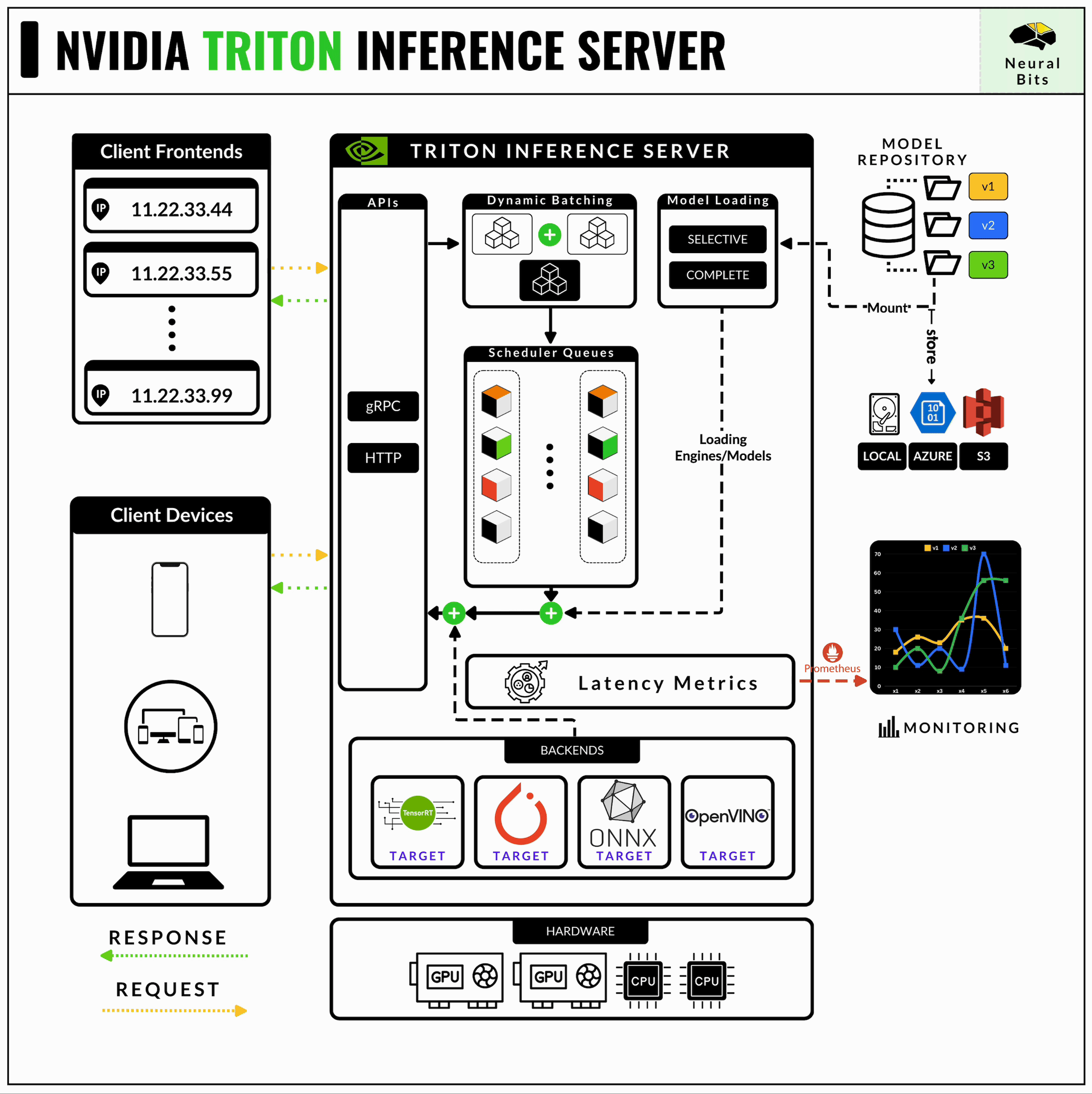
Triton started as a part of the NVIDIA Deep Learning SDK to help developers encapsulate their models on the NVIDIA software kit. It further branched out and was called TensorRT Server which focused on serving models optimized as TensorRT engines and further became NVIDIA Triton Inference Server.
In production environments, latency, workload distribution, and cost are critical factors for each AI product. Triton is a robust framework to handle and optimize for all these factors, including more.
Let’s unpack the key details you must know:
It supports multiple frameworks, including ONNX, TensorRT, PyTorch, Tensorflow, and even Python or C++ scripting modules.
Once deployed, you can implement clients in Python, C++, or Java.
Supports HTTP for standard inference requests that don’t require real-time as well as gRPC for real-time latency.
Automatically exports rich metrics, such as GPU times, server loads, inference times, and more, via Prometheus endpoints.
Allows developers to control the deployment at the lowest level, specifying model replicas, batching times, model-control flow, and more.
It’s extensible, as one could add Python scripts as model stages and couple a custom model graph using the Pipeline (Ensemble, BSL) concept.
Cloud integration, popular on Azure, AWS, and GCP, Kubernetes ready.
One important detail on Triton Server is the triton_backends interface, which is a collection of integrations that allowed for TensorRT-LLM engines or vLLM engines to be compatible for serving with Triton Server.
Once a model is optimized, we have to define the configuration files in `.pbtxt` format that Triton understands before deploying the said model. These configuration files specify the Input/Output structure of layers, data types, layer names, shapes, server scale config, GPUs, and more.
When serving a TensorRT-LLM engine with Triton, the model is split into 4 sub-models, each handling a task from the end-to-end inference request. For instance, if we take Microsoft Phi-3-128k LLM:

Our LLM model will be an Ensemble or a Pipeline of models, where each part of an inference request is modularised. Here we have:
preprocessing - handles the prompt tokenization. (text-to-tokens)
postprocessing - handles the logits de-tokenization (logits-to-tokens).
tensorrt_llm - is the actual LLM model engine, which processes raw logits.
tensorrt_llm_bls - the backend-launcher-service that serves tokens back to the client's request.
ensemble - defines the pipeline structure and chains model steps together. This is the entry point to our model.
For a hands-on, end-to-end example on deploying a simple model with Triton

6. NVIDIA NIM
NVIDIA NIM is a set of easy-to-use, plug-and-play microservices designed for secure, reliable deployment of high-performance AI model inferencing across clouds, data centers, and workstations. It was specifically designed to encapsulate and deploy enterprise-ready Generative AI solutions into production environments.

To simply understand NIMs, think of them as specialized pre-built containers that come with Triton Server, CUDA, cuDNN, and TensorRT-LLM out of the box as the runtime and expose the Client API with FastAPI using the OpenAI API template. The latter refers to a standard proposed by OpenAI on building LLM clients and is not to be mistaken for `calling the OpenAI GPT models.‘
A few key details on NIMs:
Once deployed, NIM scans the hardware and identifies the GPUs available.
For that specific GPU, it searches NGC for the optimized TensorRT-LLM engine of the model being deployed within a NIM.
In case it finds the engine on NGC, it downloads, caches, and serves it.
If the engine isn’t found, as a fallback mechanism, it’ll download and cache the model from HuggingFace in its raw format and serve it using the vLLM backend in Triton Server.
For a more in-depth dive on NIMs, please see this article:

7. NVIDIA Dynamo Inference Framework
Dynamo is the latest installment amongst the NVIDIA AI Stack, announced and open-sourced at NVIDIA GTC 2025 on March 17. Dynamo is an inference framework for accelerating and scaling AI reasoning models at the lowest cost with the highest efficiency.
Dynamo is built mainly in Rust (55%) for critical performance-sensitive modules, thanks to the memory safety and concurrency of Rust. Go (28%) for the deployment module, including Operator, Helm, and API Server part, and Python (10%) for its flexibility and customization to bring it all up together.

To simply understand Dynamo, think of it as an out-of-the-box framework that scales Generative AI inference, particularly the Prefill/Decode stages of token generation on multiple GPUs.
A few key points on Dynamo:
Leverages Dissagregated Serving, which splits the prefill stage, which runs faster, non-blocking and can be parallelizable on GPUs, and decode stage which runs iteratively, one token at a time. Splitting and distributing these two increases the performance and throughput by a large factor.
GPU Planner can adjust the cluster elasticity by adding or removing GPU nodes to saturate the workload.
KV Cache manager handles hot-loading of the KV cache that can be shared across the system via NIXL.
NIXL is a high-speed special communications protocol, specifically designed to exchange Tensors, KV Cache, and other objects.
For a deeper dive on Dynamo and its sub-components, please see this article:

Conclusion
Knowing about the purpose of each library, toolkit, and framework discussed here won’t make you an AI Expert, but it’ll provide a solid ground into understanding the software landscape that powers most of the current AI stack across many industries.
In this article, we’ve covered the major libraries and frameworks for AI and Deep Learning from NVIDIA. We started with CUDA, which parallelizes operations on GPUs, then TensorRT/TensorRT-LLM Inference Engines for optimizing models before deployment and ended up with Serving Engines such as Triton Server and Dynamo for deployment at scale.
With NVIDIA having the largest share of software & hardware in the AI Space, this article will help you understand which tool applies to which sub-domain of AI, be it Machine Learning, Deep Learning, or GenAI.
Thanks for reading, see you next week!
Resources:
ai-dynamo/dynamo: A Datacenter-Scale Distributed Inference Serving Framework. (n.d.). GitHub. https://github.com/ai-dynamo/dynamo
NVIDIA/TensorRT: NVIDIA® TensorRTTM is an SDK for high-performance deep learning inference on NVIDIA GPUs. This repository contains the open source components of TensorRT. (n.d.). https://github.com/NVIDIA/TensorRT
NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that execute those TensorRT engines. (n.d.). https://github.com/NVIDIA/TensorRT-LLM
triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution. (n.d.). https://github.com/triton-inference-server/server
NVIDIA/nim-anywhere: Accelerate your Gen AI with NVIDIA NIM and NVIDIA AI Workbench. (n.d.). https://github.com/NVIDIA/nim-anywhere
If not mentioned otherwise, images are created by the author.